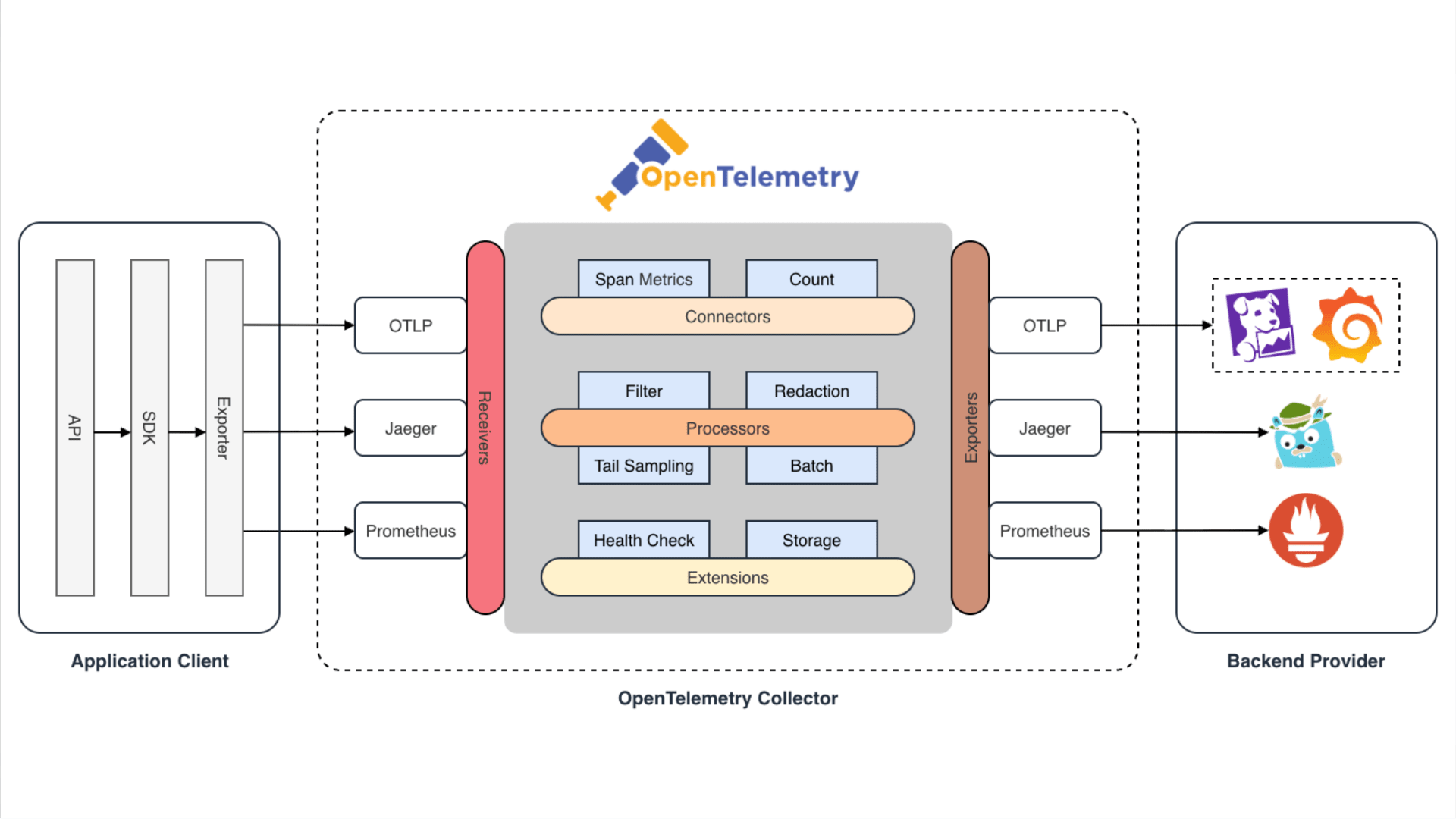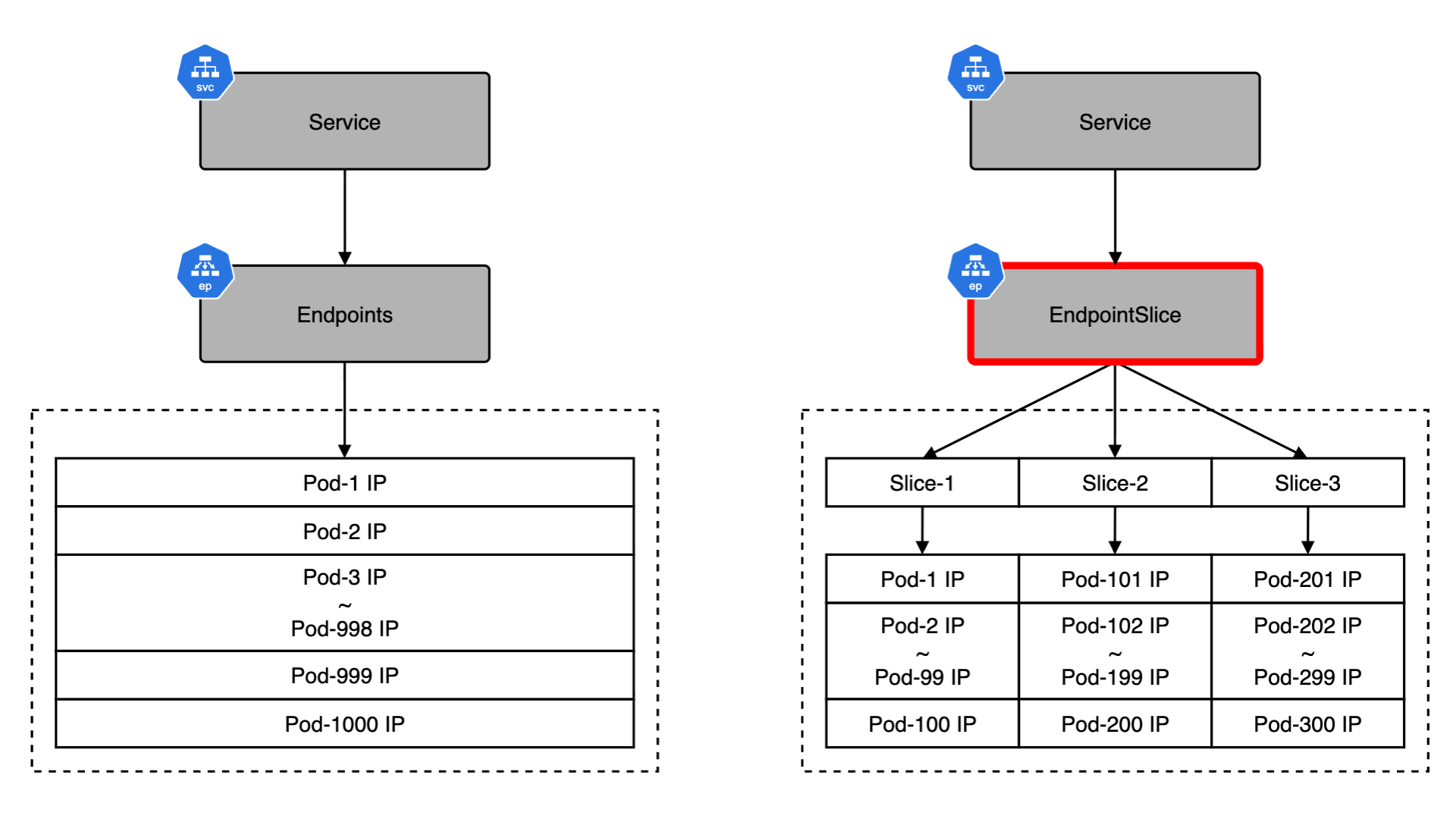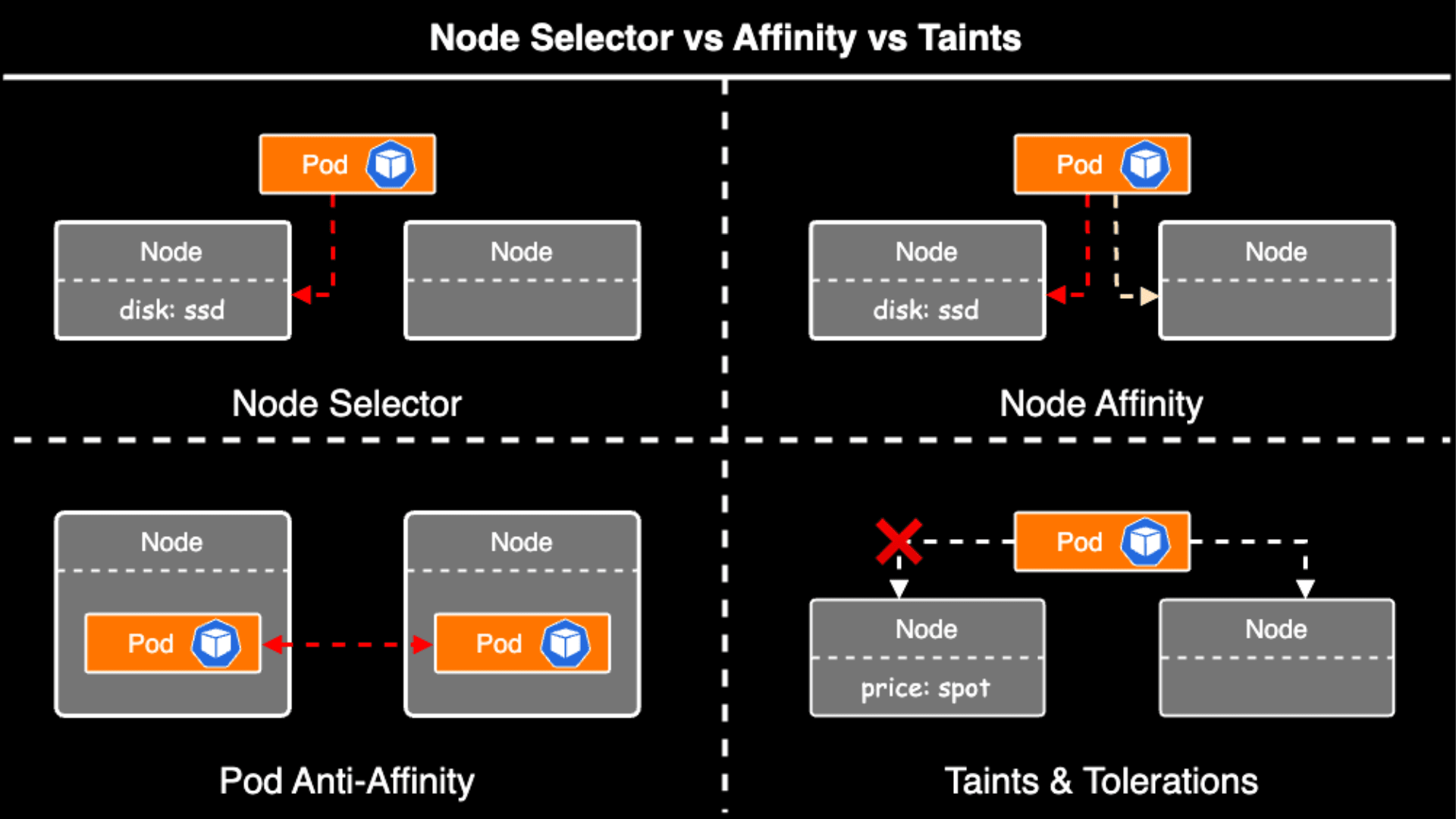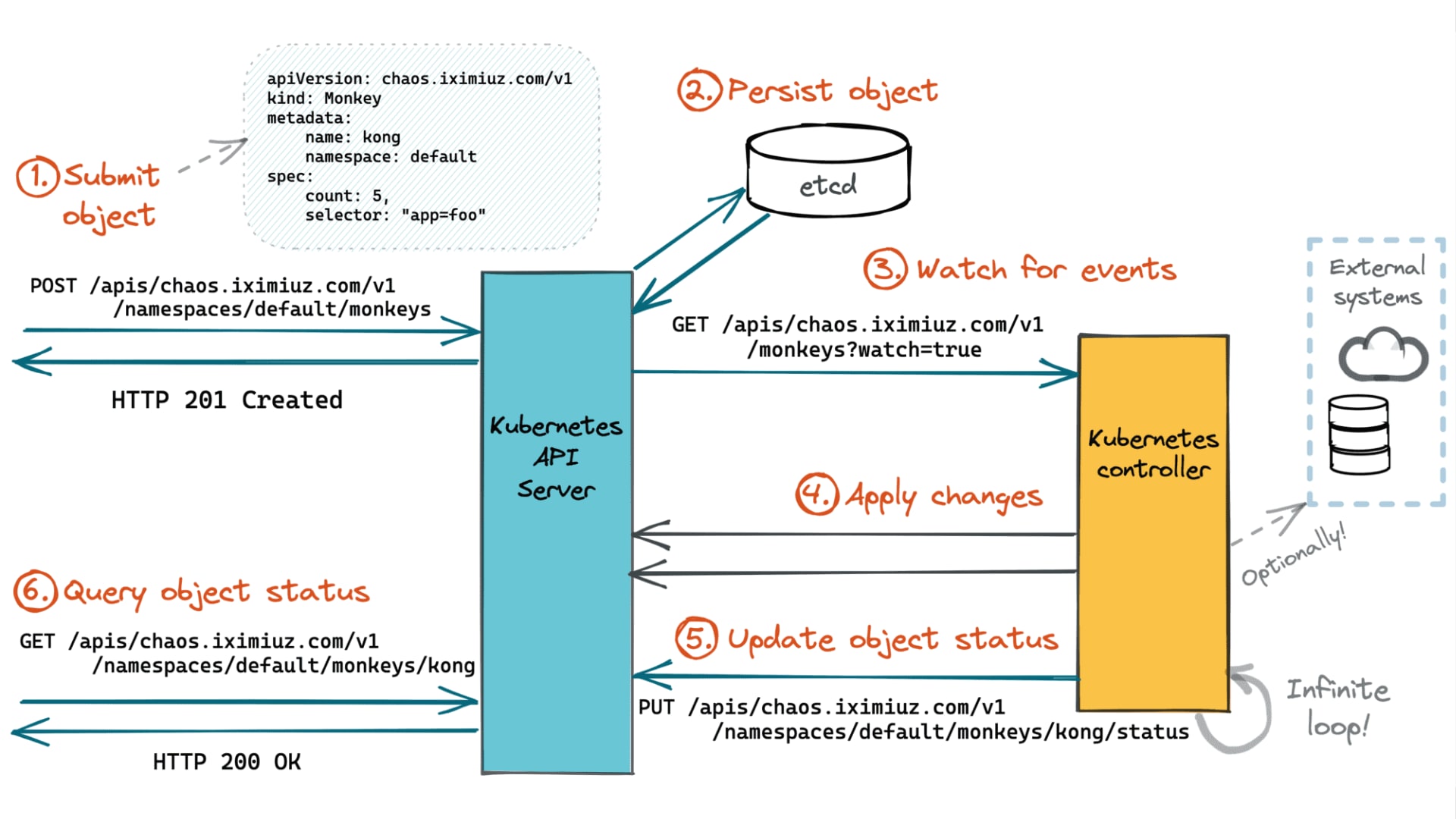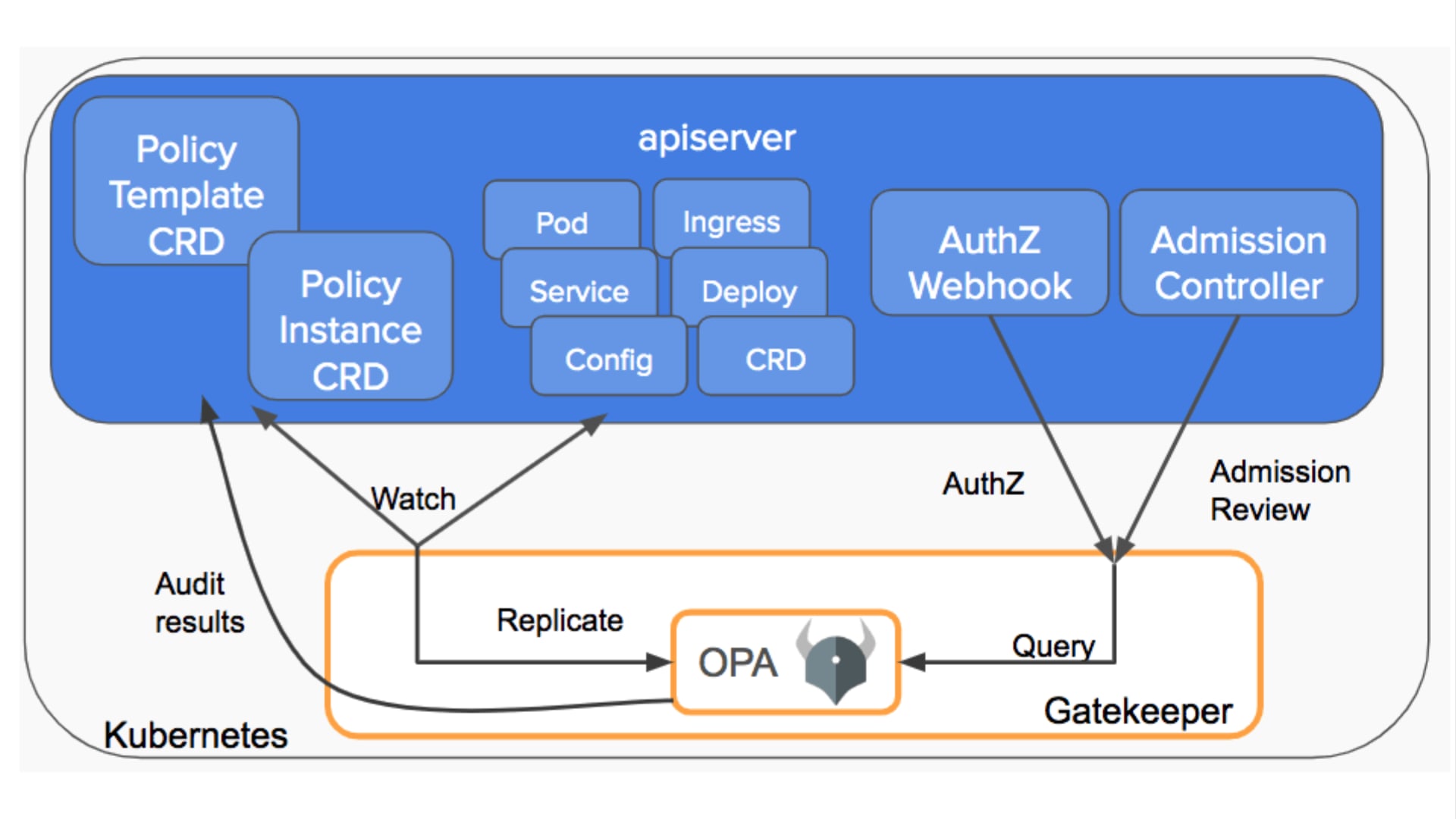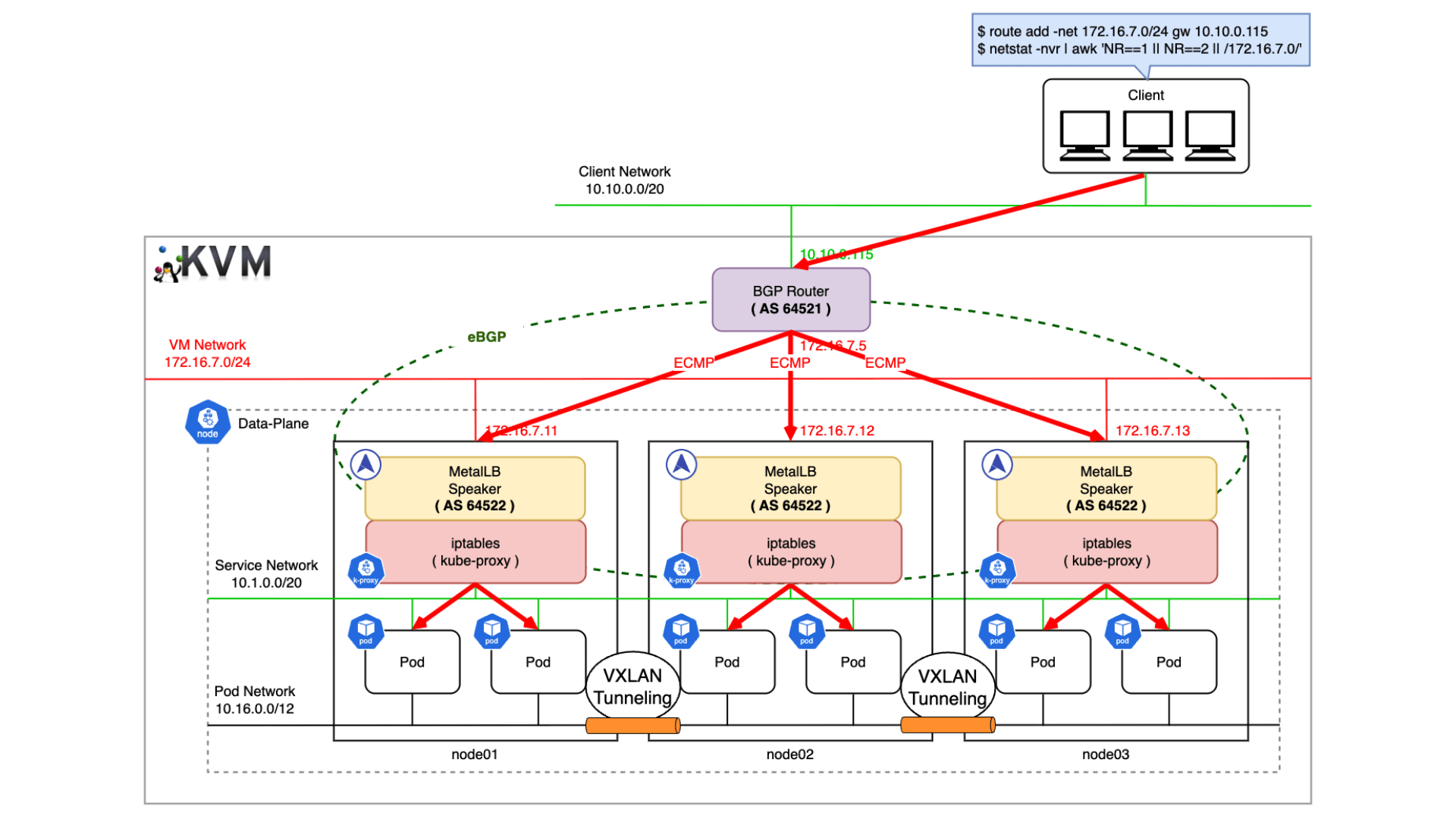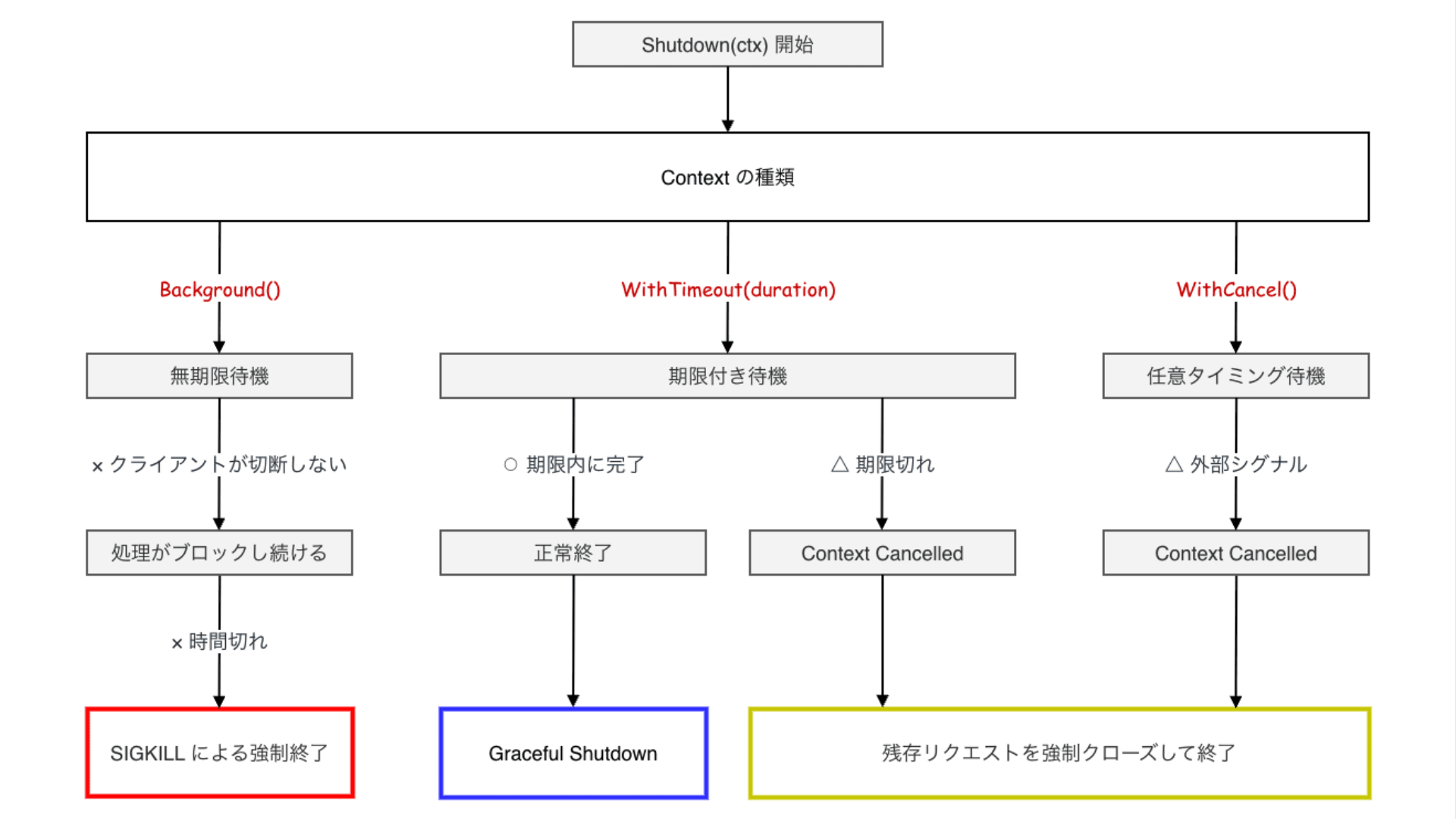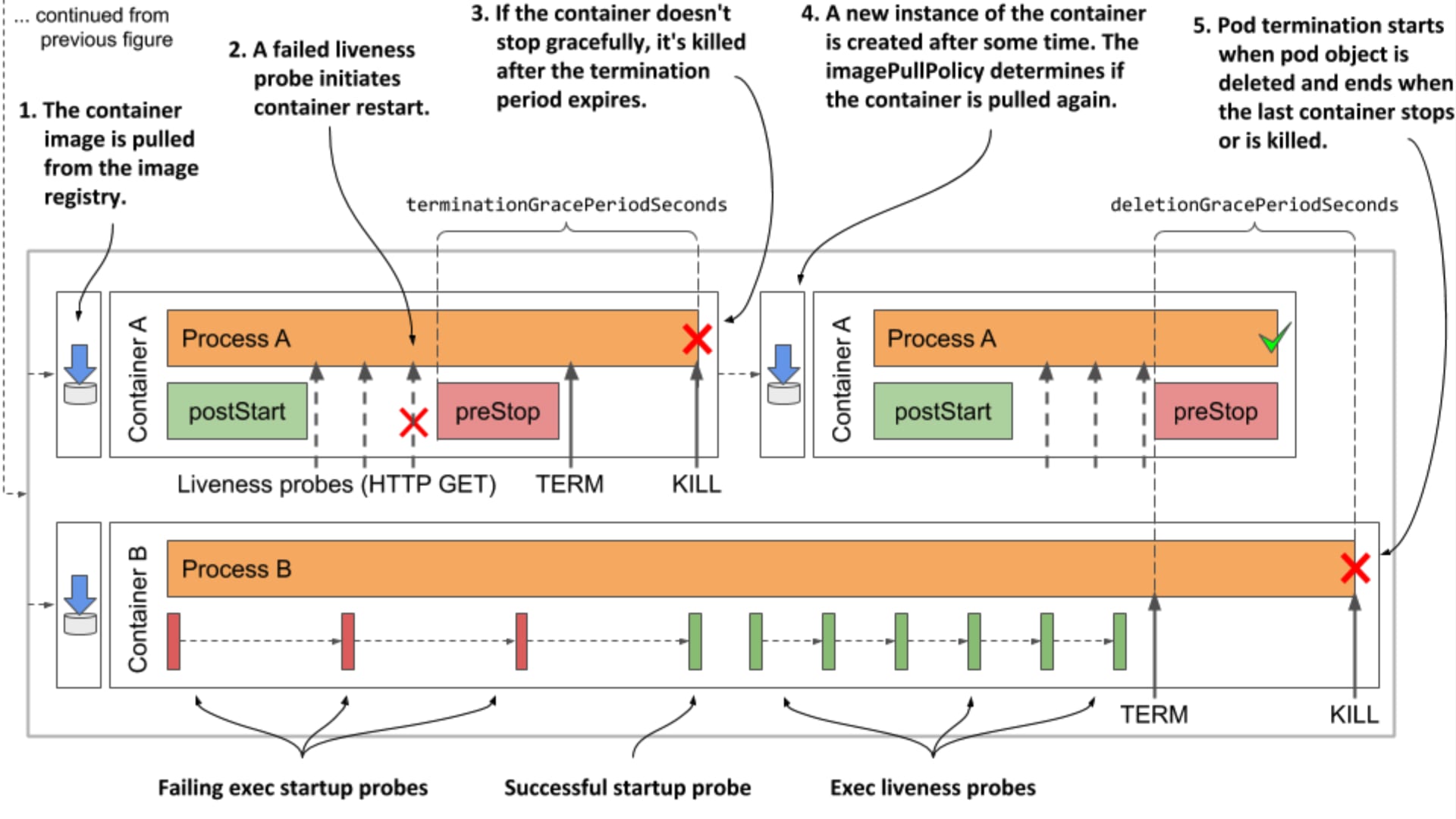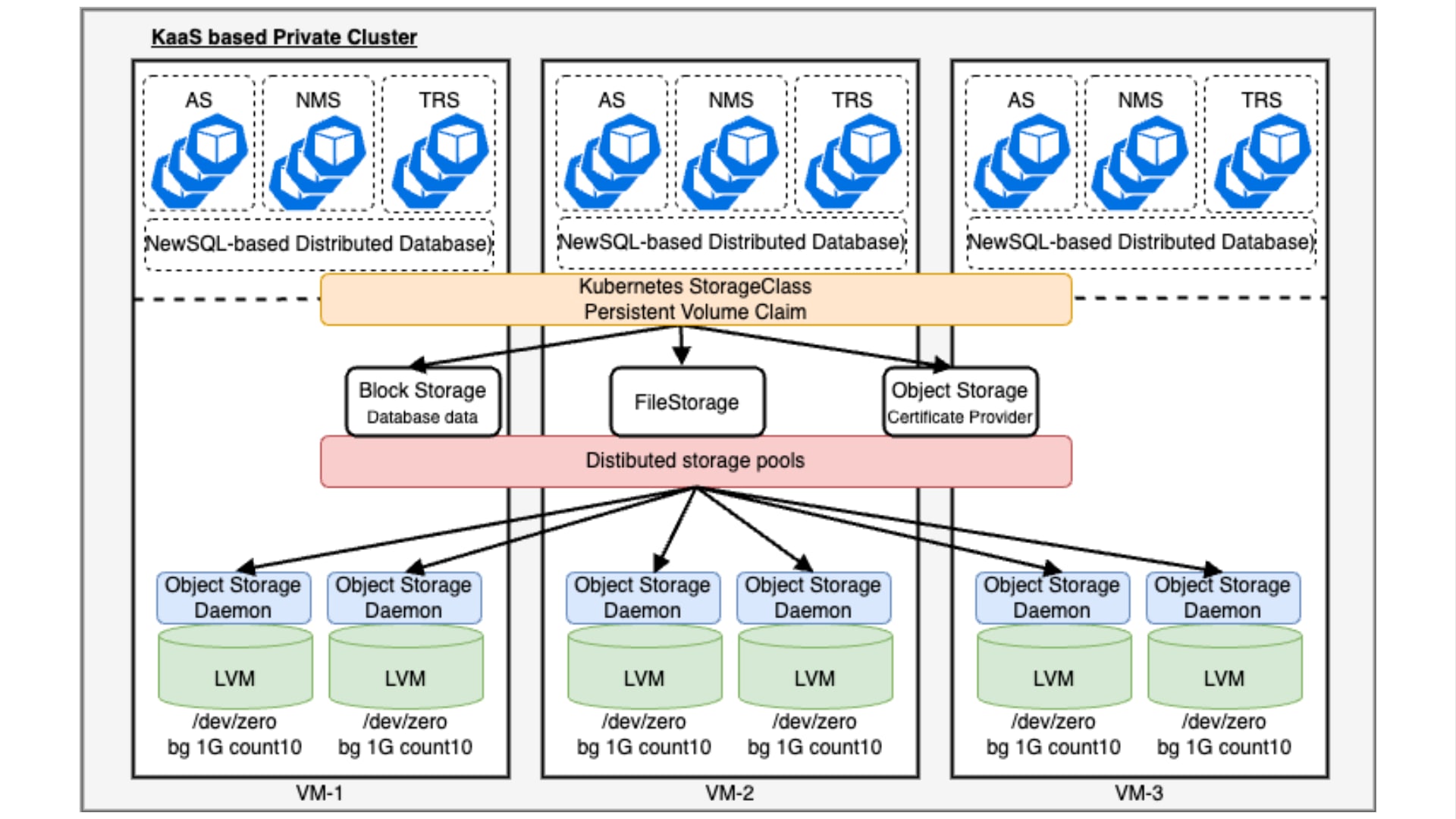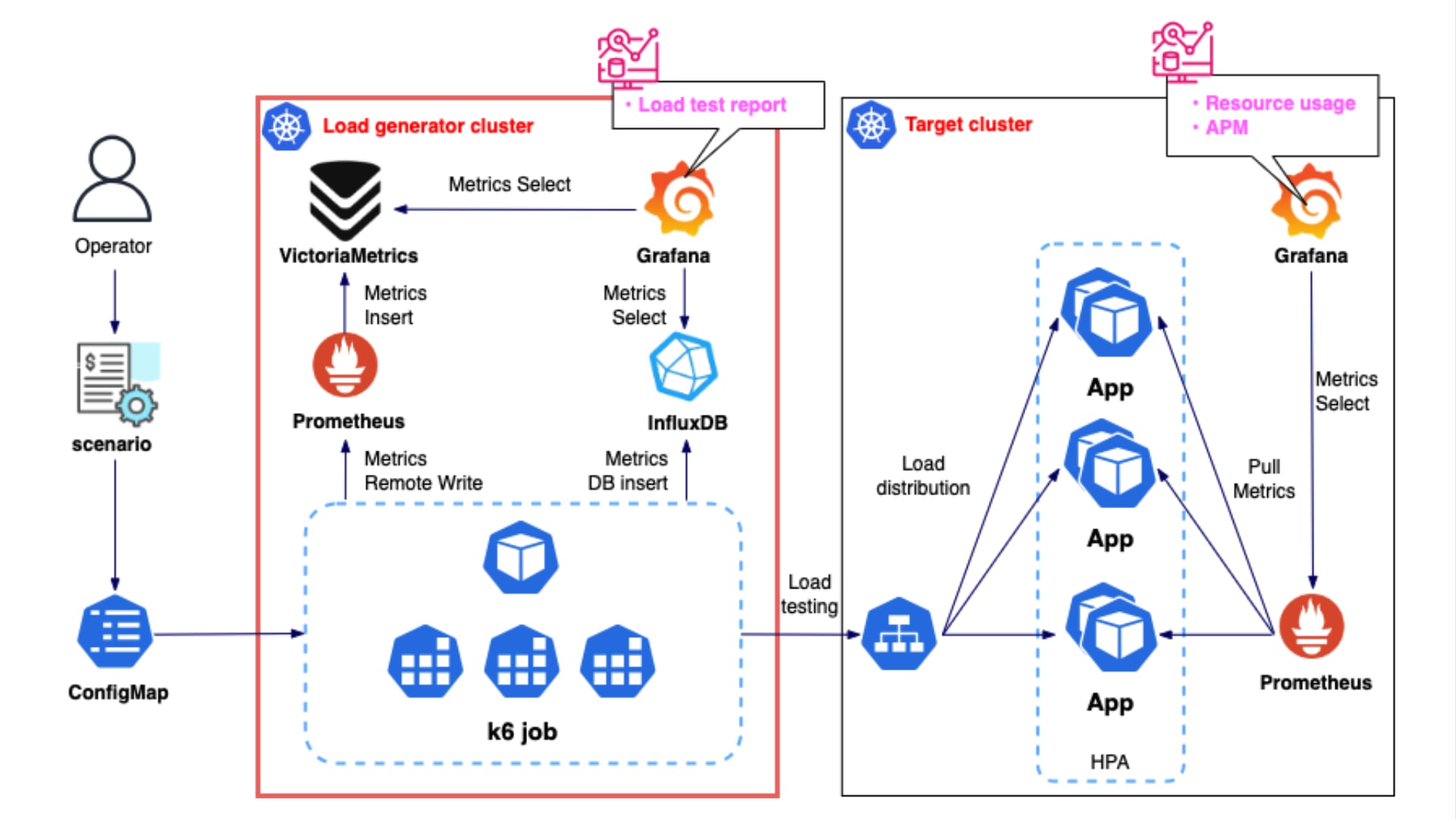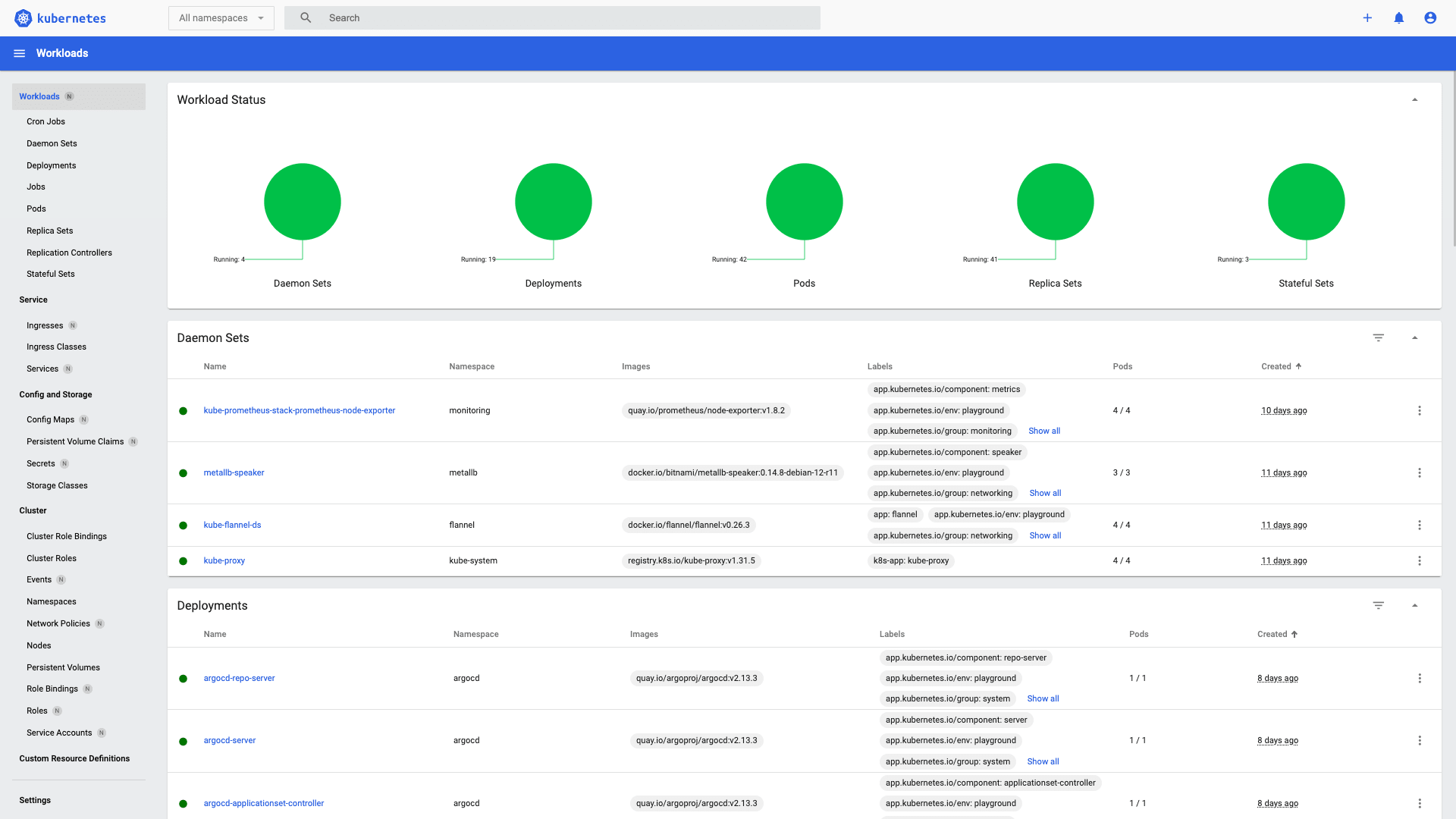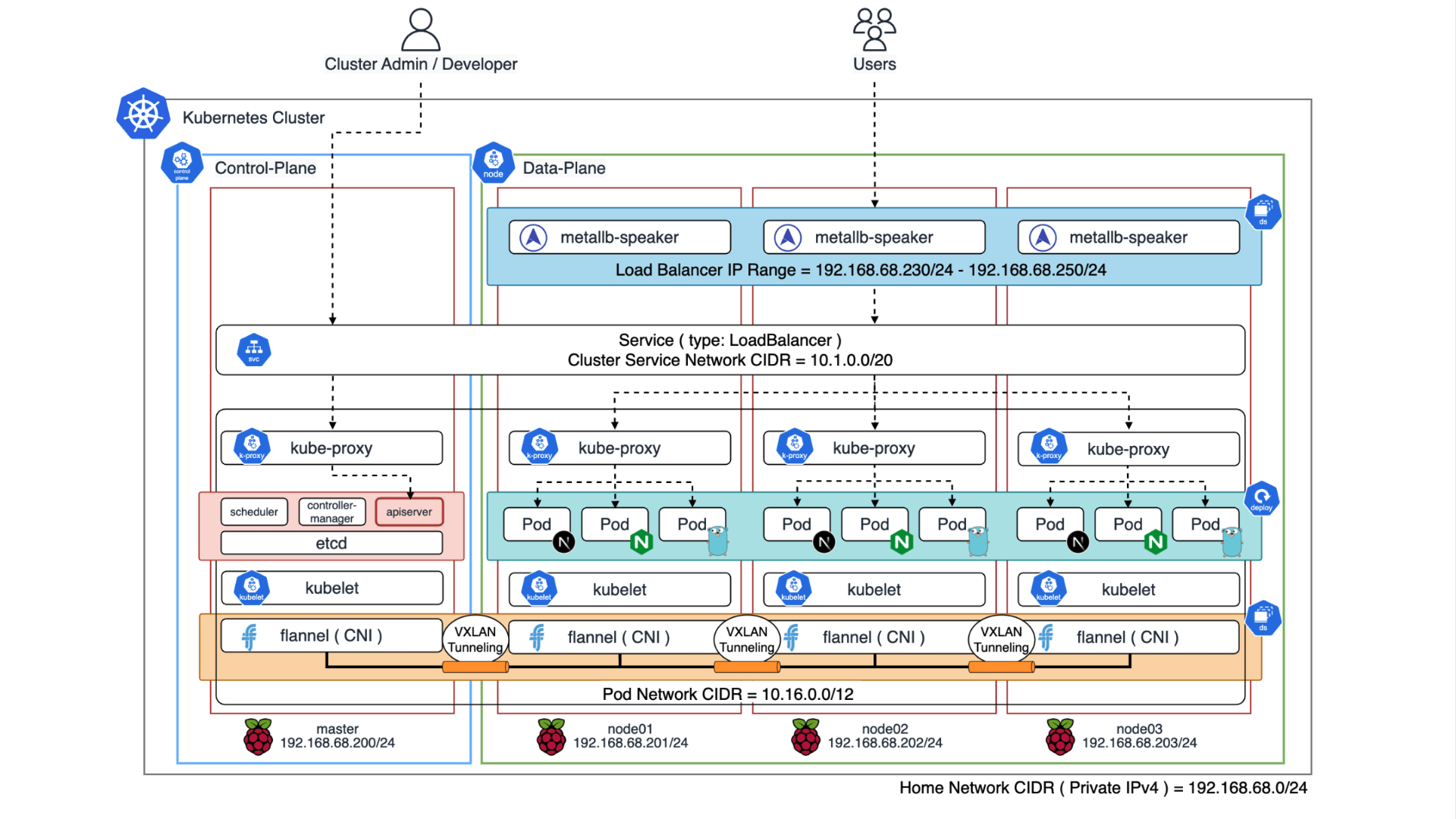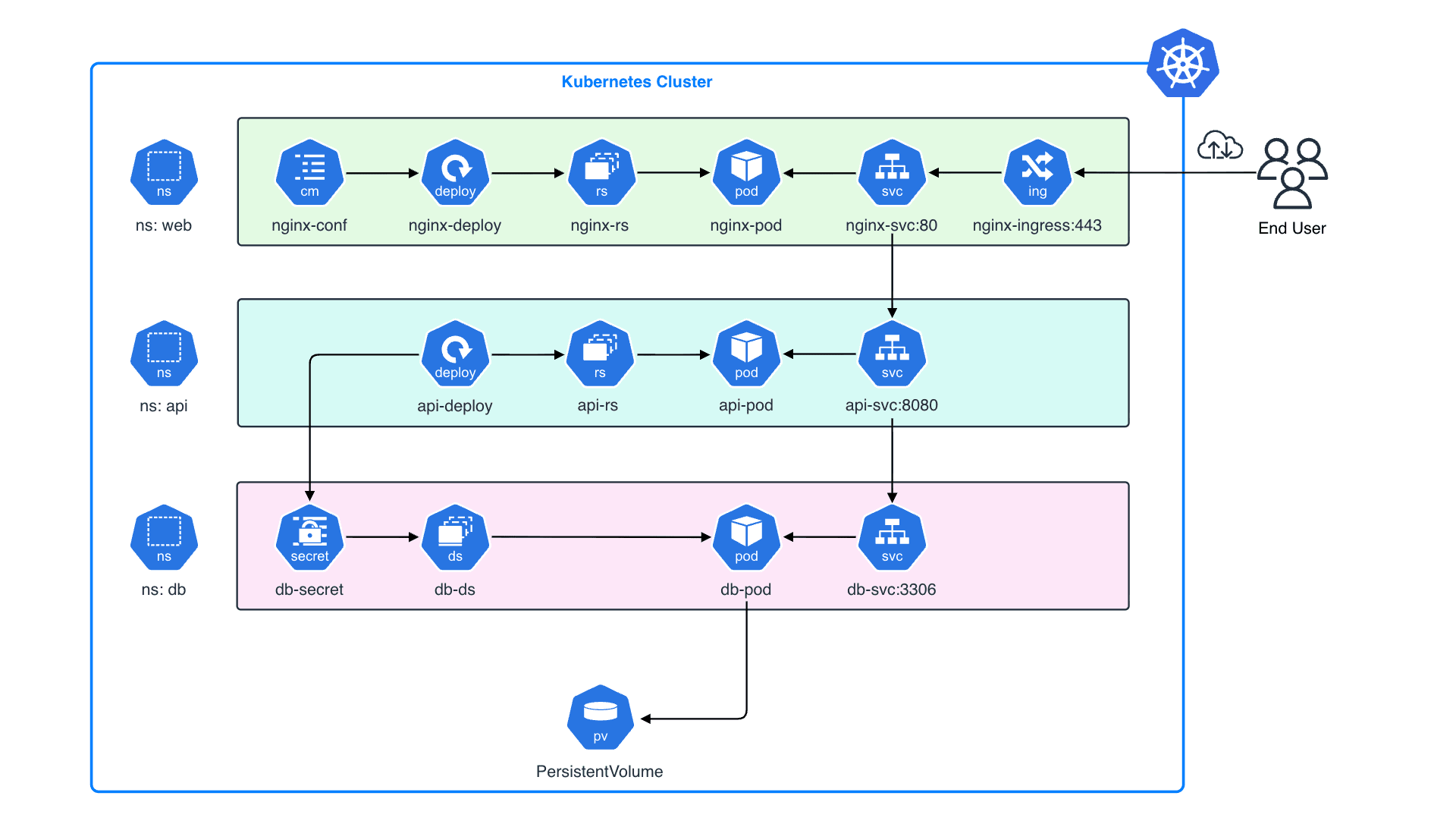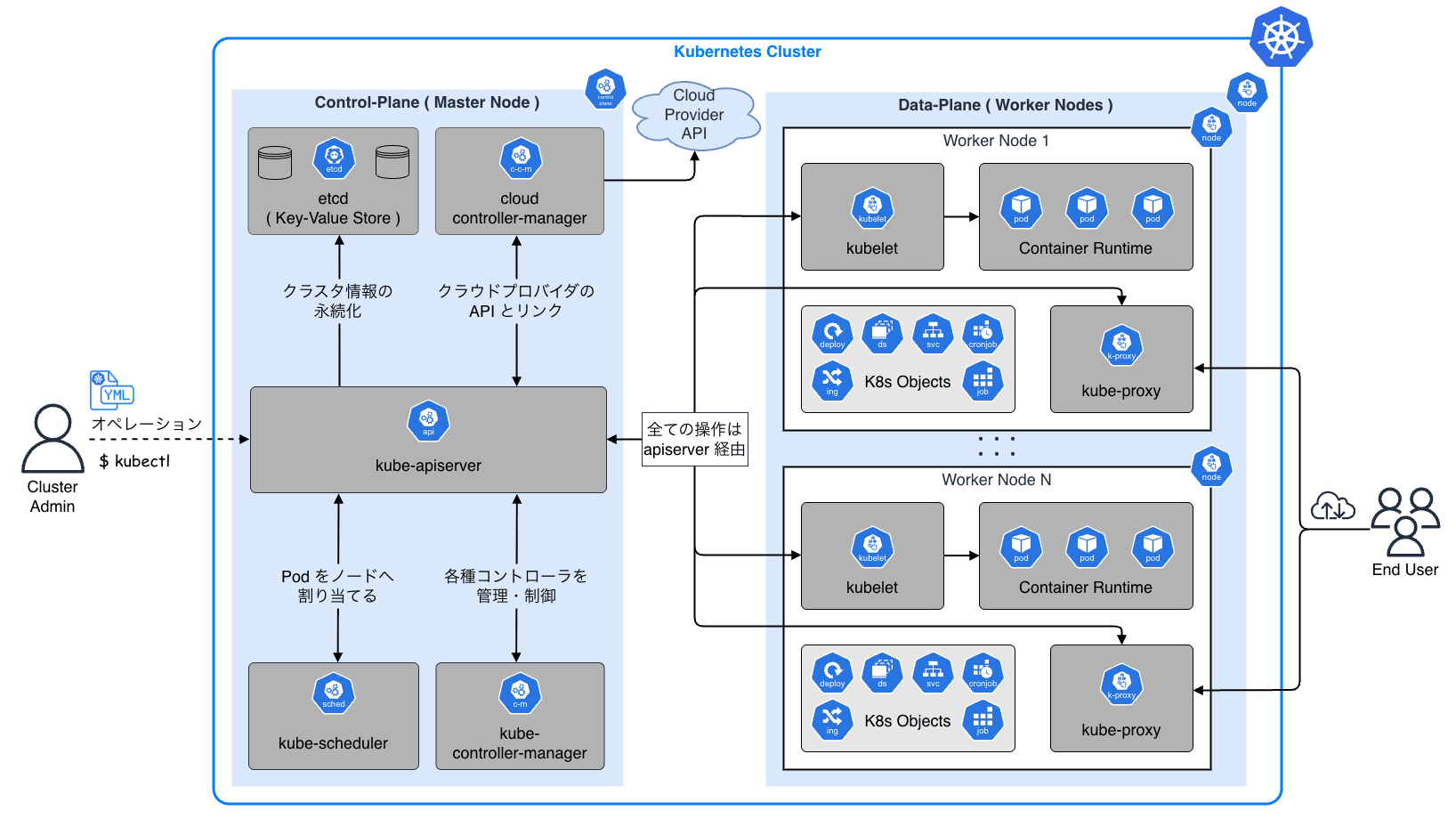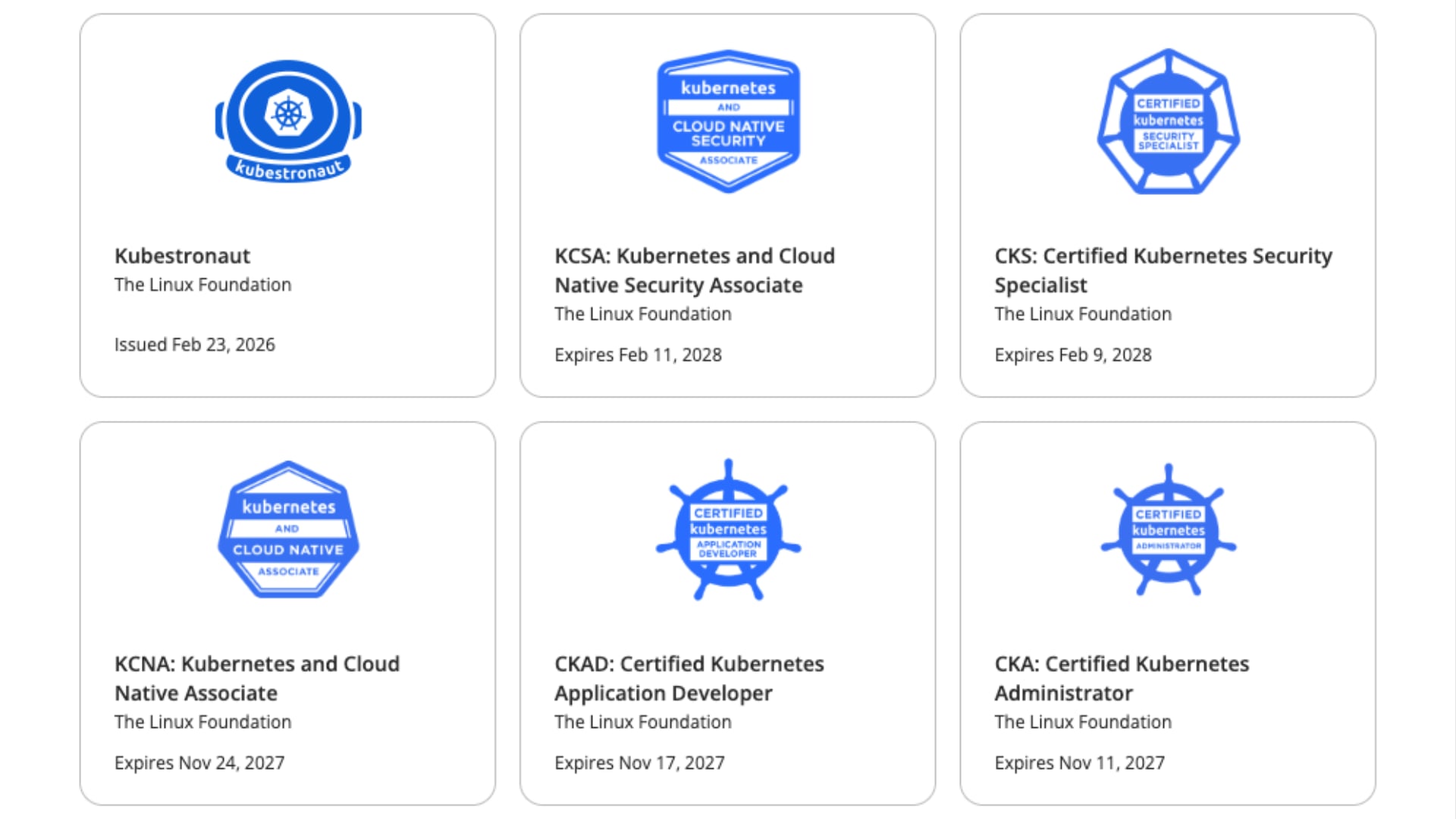
今月に入り CNCF(Cloud Native Computing Foundation)が認定する 5 つの Kubernetes 関連資格を全て制覇し、Kubestronaut の称号を獲得しました。Kubernetes 認定資格はここ数年で試験内容のアップデートが続いており、日本語の具体的な攻略記事がまだまだ少ないと感じたため本記事を執筆することにしました。Kubestronaut の称号を得ることは、Kubernetes に関して運用・開発・セキュリティといったあらゆる側面から深く理解していることの証明になります。今回のブログでは、Kubernetes に興味を持っている方、実際に Kubestronaut を目標にしている方に向けて、私が実践した学習ロードマップや準備のプロセス、高得点を狙うための試験対策についてまとめたいと思います。本記事の内容は 2026 年 2 月時点のものです。試験内容は頻繁にアップデートされるため、受験の際は必ず公式サイトで最新の試験ガイドを確認してください。
- Published on