Rook/Ceph で実現する分散ストレージの構築
はじめに
現在、研究室で利用するための KaaS 基盤(プライベートクラウド)を整備するべく、ベアメタル Kubernetes の構築に取り組んでいます。
【マルチテナント・シングルクラスタで運用】

今回は、CNCF cloud native landscape にもある Rook/Ceph を使用して分散ストレージシステムを導入し、Amazon S3 や Google Cloud Storage に相当するオブジェクトストレージを自前で構築してみたので、その紹介です。
分散ストレージシステム
ストレージシステムの種類
ストレージと一言で言っても、いくつか種類が存在し、扱うデータの容量や種類によって使い分けられます。
ファイルストレージ
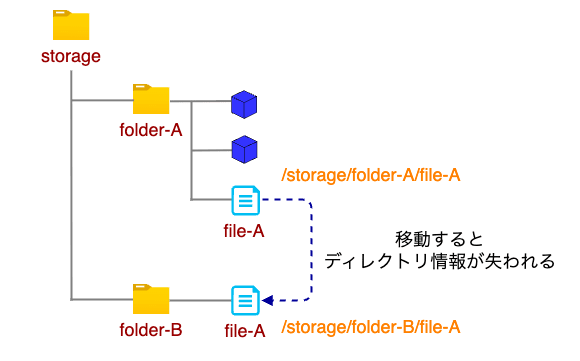
- データは「フォルダ」や「ディレクトリ」といった形式で階層的に管理・保存される
- 階層的に保存されたデータには一意のパスを用いて、階層を辿る形でアクセスする
- データ保存の際にはファイル名、作成日、サイズ、データの種類等、最低限のメタデータが付与される
- メリット
- 小中規模のデータ管理を行うにあたり、簡潔かつ直感的な利用を実現できる
- CIFS や NFS といった通信規格を用いることで、ネットワーク越しに利用することができる
- デメリット
- 大規模なデータ利用や非構造化データの管理が困難
- データ容量が増加すると、ハードウェアへのリソース要求が大きくなり、パフォーマンスが劣化する
- 利用例:)普段使用している(UNIX 系 OS や Windows を搭載した)PC, Ceph
| ファイルストレージ | |
|---|---|
| 特徴 | ネットワークドライブに格納 |
| データ単位 | ファイル |
| 一貫性 | 結果整合性 |
| 構造化 | 階層構造 |
| メタデータの付与 | 限定的 |
| 制御構造と処理速度 | 階層構造により 一定容量 まで高速 |
| データ転送プロトコル | CIFS(SMB), NFS |
| マウントパスの例 | /path/to/storage/folder-A/file-A |
| 適合データ | 容量:小〜中規模 更新頻度:高 |
| 主な用途 | ファイルの共有 |
オブジェクトストレージ
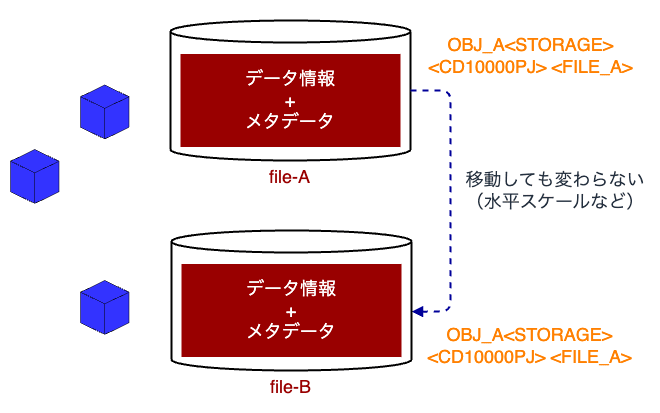
- データは「オブジェクト」というフラットな形式で保存される
- ファイルストレージに比べて保存期間やコピー回数等、より多くのメタデータを付与できる
- 全てのメタデータはオブジェクトと一緒に格納され、一意の識別子を持つアドレス空間に保存される
- メタデータが任意に設定可能である
- フォルダやディレクトリだけでなく、メタデータによる複数の属性情報でグルーピングを行うことができる
- メリット
- オブジェクトストレージはフラットにアドレス空間に保存されているため、インデックスの作成が容易に行える
- 大規模なデータや非構造化データであっても効率的な検索ができる
- 地理的に離れた複数のサーバを並列化して一つのストレージプールを構成できるため、スケールアウトしやすい
- 馴染み深い HTTP API で操作することができる
- デメリット
- オブジェクトというフラットで単純な構造を採用しているため、複雑なクエリ検索や、ファイルシステムのようなディレクトリ階層構造およびブロックレベルのアクセスは制限される
- 後述するブロックストレージよりも低速であるため、更新頻度が高く、読み書きに速度を要求されるデータの保存には向かない
- 利用例:)Amazon S3, Google Cloud Storage, OpenStack Swift, Ceph
| オブジェクトストレージ | |
|---|---|
| 特徴 | オブジェクト単位でのアクセス (ファイルシステムに依存しないため、大量データの格納が可能) |
| データ単位 | オブジェクト |
| 一貫性 | 強い整合性 |
| 構造化 | フラット構造 |
| メタデータの付与 | 多様 |
| 制御構造と処理速度 | インデックスにより高速 |
| データ転送プロトコル | REST(HTTP, HTTPS) |
| マウントパスの例 | https://share.org/storage/file-A |
| 適合データ | 容量:中〜大規模 更新頻度:低 |
| 主な用途 | 画像・動画の保存 |
ブロックストレージ
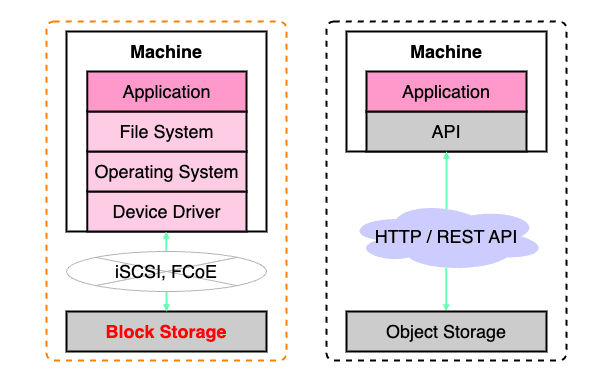
- 物理マシンの記録領域をボリュームという単位で分割して、内部を固定長のブロックで切り出し、そのブロックにデータを保存、管理する
- ボリュームとブロックには固有の番号(アドレス)が振り分けられており、ユーザの要求するデータ容量に合わせて、必要となるブロックリソースの確保と統合が行われる
- 保存するデータがブロックサイズを越える場合、複数のブロック(ブロックが連続している必要はない)に跨ってデータの保存が行われる
- メリット
- ブロックストレージは階層構造を必要としない他、読み込むデータへのパスを複数指定することが可能ため高速なアクセスを行うことができる
- きめ細かやな制御を行うことができるため、高効率なパフォーマンスを求められるアプリケーション(ミドルウェア)の実装に適している
- デメリット
- ハードウェアがとにかく高い
- メタデータの付与を行うこともできないため、ファイルストレージやオブジェクトストレージよりも低レイヤーに位置付けられ、それらの基盤として利用されることが一般的
- 利用例:)RDBMS, VM ストレージ, コンテナ仮想ディスク, Ceph
| ブロックストレージ | |
|---|---|
| 特徴 | 内臓ドライブと同じ RAW デバイスに格納 |
| データ単位 | ブロックデバイス |
| 一貫性 | 強い整合性 |
| 構造化 | ボリューム・ブロック |
| メタデータの付与 | 無し |
| 制御構造と処理速度 | 緻密で効率的な制御により高速 |
| データ転送プロトコル | FC-SCSI, iSCSI, FCoE, NVMe-oF |
| マウントパスの例 | /dev/sda |
| 適合データ | 容量:小〜中規模 更新頻度:高 |
| 主な用途 | データベース, OS ディスク) |
分散ストレージのメリット
分散ストレージの特徴、導入するメリットには次のようなものがあります。
- 高可用性および耐久性
- データを複数の場所に分散して保存するため、システムの可用性が向上し、データの耐久性が高まる
- 単一のディスクやサーバが故障しても、他の場所に冗長なコピーデータが存在するため、データの喪失やアクセスの中断を防ぐことができる
- 拡張性
- 増え続けるデータ数に柔軟に対応することができる
- 新しいノードやサーバをシステムに追加することで、容量やパフォーマンスを必要に応じて拡張し、大量のデータを効率的に管理・処理することができる
- 負荷分散
- データを複数のノードやサーバに分散するため、負荷を分散できる
- データへのアクセスや処理のパフォーマンスが向上し、システム全体の応答性が向上する
- 柔軟性
- 異なるデータのタイプや形式、アクセスパターンに対応するための柔軟性を持ち合わせており、多種多用なデータを効率的に管理することができる
- 異なる場所にデータを配置することも可能であり、地理的な冗長性を確保することもできる(ベアメタルだとこれは厳しい)
- コスト面
- ハードウェアやリソースの共有を可能にするため、コスト効率が高い
- データの冗長性を維持しながらも、スケーラビリティや耐久性を確保することができる
- Ceph, OpenStack Swift, GlusterFS 等の OSS 分散ストレージソリューションも多数存在し、ライセンス費用を節約することができる
今回、分散ストレージを導入しようと思った主な理由は、1. 高可用性と耐久性、3. 負荷分散の恩恵を受けるためです。
そもそも、Kubernetes を構築した理由は、これまで運用していたオンプレのサーバ群の水平スケールや規模拡張性を実現するためです。 これまで、僕が携わっている研究の一部として、マイクロサービスを採用したクラウドシステムを実現しようとしていたのですが、あくまでも単一のサーバとして稼働させることしかできず、クラウドサービスと呼ぶには程遠い状態でした。 また、これまでの検証で、サーバが一定の負荷に耐えられるのに対して、データベース等のミドルウェアがボトルネックとなり、パフォーマンスを十分に発揮できないという課題がありました。 さらに、データの管理に関しても、単一ストレージでは、水平スケールや多重化されたサーバからの大量な R/W アクセスに耐えられない可能性があると考えました。
そこで、まず、ミドルウェアから対処するべく、分散ストレージの導入を検討し、データのレプリケーションを張ることで、冗長化を図るとともにリクエストを分散させようと思いました。
Rook/Ceph の採用
今回はタイトルにもある通り、分散ストレージを構築するためのツールとして Ceph(Rook)を採用しました。
Ceph は、昔から使用されているストレージプロバイダであり、大規模な分散ストレージシステムを構築することができます。 また、NASA 米国国家航空宇宙局 や CERN 欧州原子核研究機構 等、如何にも膨大なデータ量を管理していそうな機関でも導入実績のあるツールです。 日本でも、富士通株式会社が提供する FUJITSU Storage ETERNUS CD10000 S2 ハイパースケールストレージ 等で使用されている様です。
一方で、Ceph コンポーネントは非常に複雑であり、個人運用する場合において、導入のハードルや管理コストが高いという課題があります。 しかし、有難いことに CNCF は Rook という Ceph の運用・管理を自動化し、セルフスケーリング・セルフヒーリングを提供する OSS を準備してくれています。
Rook は Ceph のオペレータとして機能し、Kubernetes クラスタ上で、容易に Ceph のデプロイや構成、プロビジョニング、スケール、アップグレード、モニタリングを行うことが可能になります。 また、Ceph 上にオブジェクトストレージ(バケット)やブロックストレージ(データベースシステム)といった様々なストレージシステムを柔軟に構築することができるため、今回の利用ケースや目的にかなり適していると思いました。
その他、身近なところでは、サイボウズ株式会社 が提供する kintone の裏側でも使用されており、公開情報が豊富に存在することから導入のハードルが比較的低いのも採用理由の一つです。
Rook/Ceph の詳細
Rook の README によれば、それぞれ次のように説明されています。
Rook

Rook is an open source cloud-native storage orchestrator for Kubernetes, providing the platform, framework, and support for Ceph storage to natively integrate with Kubernetes.
Rook は Kubernetes 用のオープンソースのクラウドネイティブストレージオーケストレーターであり、Kubernetes とネイティブに統合するためのプラットフォーム、フレームワーク、Ceph ストレージのサポートを提供します。
Ceph

Ceph is a distributed storage system that provides file, block and object storage and is deployed in large scale production clusters.
Ceph は、ファイル、ブロック、オブジェクトストレージを提供する分散ストレージシステムであり、大規模な実稼働クラスタにデプロイされます。
要するに、『Ceph は大規模な分散ストレージシステムを構築することができて、Operator である Rook を使用すれば Kubernetes 上で簡単に扱えるよ』といったニュアンスだと思います。
アーキテクチャ

Rook/Ceph アーキテクチャのうち、特に重要な 3 つの Ceph コンポーネント(MON, MGR, OSD)について紹介します。
- MON:Ceph Monitor daemon
- クラスタのヘルス状態に関する情報、すべてのノードのマップ、およびデータ分散ルールを維持する
- 障害または衝突が発生した場合、クラスタ内の Ceph Monitor ノードは、どの情報が正しいかを多数決で決定する
- 必ず多数決が得られるように、奇数個(少なくとも 3 個以上)の Ceph Monitor ノードを設定する必要がある
- 複数のサイトを使用する場合、Ceph Monitor ノードは奇数個のサイトに分散配置する必要がある
- サイトあたりの Ceph Monitor ノードの数は、1 つのサイトに障害が発生した場合、50% を超える Ceph Monitor ノードの機能が維持される数準備する必要がある
- MGR:Ceph Manager daemon
- クラスタ全体からステート情報を収集する
- MGR daemon は MON daemon と一緒に動作する
- 追加のモニタリング機能を提供し、外部のモニタリングシステムや管理システムとのインタフェースとして機能する
- OSD:Object Storage Device daemon 👈 一番重要なコンポーネント
- オブジェクトストレージデバイスを処理するためのデーモン
- OSD は物理ストレージユニットまたは論理ストレージユニット(ハードディスクまたはパーティション)に該当する
- オブジェクトストレージデバイスは、物理ディスク/パーティションにも論理ボリューム(TopoLVM とか)にも設定できる
- OSD は他にも、データのレプリケーションや、ノードが追加または削除された場合のリバランスも処理する
- Ceph の OSD は MON と通信してステート情報を提供する
これらの主要コンポーネントは、クラスタ毎に少なくとも 1 つ以上配置しなければなりません。
その他にも、MDS や RGW 等が存在します。
- MDS:Metadata Server
- CephFS の一部として機能する
- ファイルおよびディレクトリのメタデータ(ファイル名, 所有者, アクセス許可 等)を管理することで、大規模なファイルシステムで高いパフォーマンスとスケーラビリティを実現できる
- Ceph クラスタ内でメタデータの一貫性を確保し、それらの情報を提供する
- 複数クライアントからの同時接続をサポートする
- RGW:RADOS Gateway
- Ceph Object Storage の一部として機能し、Ceph クラスタと通信することで、データの保存、取得、削除等のオブジェクト操作を処理する
- Amazon S3 や Swift とも互換性のある API を提供しており、パブリッククラウド上にオブジェクトストレージを構築できる
→ クラウドストレージやウェブアプリケーションのバックエンドで使用できる
これだけでも、素で扱うと、管理コンポーネントが多すぎてかなり大変そうなのが分かると思います。
Rook 有り難し!
注釈
- RADOS:Reliable Autonomic Distributed Object Store
- オブジェクトストレージ
- パブリッククラウドでいう S3 や Cloud Storage
- RBD:RADOS Block Device
- デバイス
- パソコンの内蔵ハードディスクや外付けハードディスクのようなもの(
/dev/sdaとして認識されるような感じ)
- CephFS(Ceph File System)
- ネットワーク経由で他のマシンと共有可能なファイルシステム
- Samba(CIFS)や NFS のようなもの
- CSI:Containers Storage Interface
- Kubernetes 環境から外部ストレージにアクセスするためのインターフェース
- RAW デバイス
- ファイルシステムを使用せずソフトウェアが直接ディスクへのアクセス制御を行う記録デバイス
- HDD や SSD を RAW デバイスとして OS に認識させることで、様々なストレージシステムを構築する
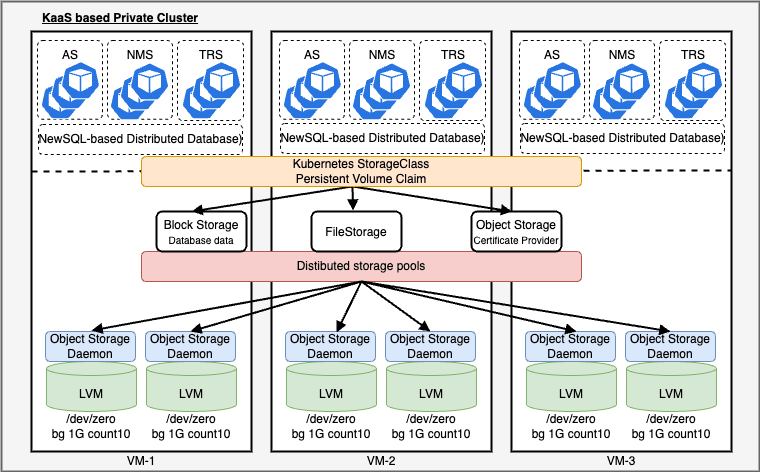
Rook/Ceph による分散ストレージの構築
ストレージシステム、Rook/Ceph の概要をある程度抑えたところで、早速、分散ストレージを構築していきます。
前提条件として、3 ノード以上の Kubernetes クラスタが構築済みであるとします。
環境の確認
今回は一台の物理マシンの上に VM を 4 台構築しました。
一台は、C-Plane として動作し、残りが D-Plane(ストレージプールが構築されるノード)として動作します。
-
ホストマシン
- CPU:Intel(R) Core(TM) i9-13900 CPU @ 5.60GHz 24 コア 32 スレッド
- アーキテクチャ:amd64
- OS:Ubuntu 22.04 LTS
- RAM:128 GB
- 台数:1
-
ゲストマシン
- 仮想化:KVM(libvirt)
- OS:Ubuntu 20.04 LTS
- RAM:16 GB
- 台数:4(C-Plane 1 台 / D-Plane 3 台)
-
ハードウェア(仮想ディスク)
- OSD 用ディスク:
/dev/vdb(仮想 HDD)・・・後の手順で、OSD Pod に認識させるための仮想ディスクを準備する
- OSD 用ディスク:
-
Kubernetes
Tools Version Kubernetes(kubeadm) v1.25.3 KVS(etcd) v3.2.26 CRI(containerd) v1.6.9 CNI(flannel) v0.3.0 -
Rook/Ceph
Tools Version Rook v1.11.0 Ceph v17.2.6
(必要に応じて)仮想ディスクとパーティションの追加
D-Plane ノード の ディスクとパーティションは以下の通りでした。
| パーティション | ファイルシステム | 割り当て |
|---|---|---|
/dev/vda1 | ext4 | boot |
/dev/vda2 | swap | swap |
/dev/vda3 | ext4 | root |
これらは、フォーマット済みおよびマウント済みであり、いずれも OSD に認識させることはできません。 そこで、まず libvirt で構築した VM に OSD に認識させるための仮想 HDD を追加します。
Rook のドキュメント に従って、事前にパーティションを準備します。
ここで、仮想ディスク/dev/vdbを作成しておき、Rook で Ceph をデプロイした際に OSD に認識させます。
なお、この時、/dev/vdbが正常に作成されていないと、OSD が起動せず、クラスタの立ち上げに失敗します。
(当初、この仕組みを知らず結構時間を溶かしました。)
以下の操作を 3 ノード全ての仮想マシンに対して行います。
- ホストマシン上での操作
- 仮想マシン上での操作
【余談】dd コマンド
if- 入力元となるファイルやデバイスを指定
/dev/zeroは, Linux システムにおいてゼロで埋められた無限のデータストリームを提供する特殊なデバイスファイル
of- 出力先となるファイルやデバイスを指定
bs- ディスクのブロックサイズを指定
count- ディスクのブロック数を指定
【余談】ノード の再 join
仮想マシンを再起動すると、NotReady状態になるため、必要に応じて以下のコマンドを実行し、クラスタに再 join する(放っておいても、何れ Ready になる)
Rook/Ceph のデプロイ
仮想ディスクを準備したところで、こちら を参考に Rook で Ceph クラスタをデプロイします。
僕は、Kustomize でデプロイしましたが、動作検証するだけなら、Quickstart ドキュメントに従えば十分かと思います。
デプロイが正常に完了すると、以下の Pod が起動します。
コンポーネントの数が凄い...
何が起動したのか除いてみます。
Rook/Ceph で起動する主な Pod の起動順序、役割、コンテナイメージは次の通りです。
| 起動順序 | 名前 | 役割 | コンテナイメージ |
|---|---|---|---|
| 1 | rook-ceph-operator | Ceph クラスタ(Pod)全体の管理 | Rook プロジェクトが提供する Rook/Ceph コンテナ |
| 2 | csi-* | CSI ドライバ(Ceph クラスタから PersistentVolume を切り出す) | Ceph プロジェクトが提供する各種コンテナ |
| 3 | rook-ceph-mon-*, rook-ceph-mgr-* | Ceph クラスタの MON, MGR daemon | Ceph プロジェクトが提供する各種コンテナ |
| 4 | rook-ceph-osd-prepare-*, rook-ceph-osd-* | Ceph クラスタの OSD 初期化, および OSD daemon | Ceph プロジェクトが提供する各種コンテナ |
csi-*というのは個々の Rook/Ceph クラスタから CephFS や RBD 等を切り出すための CSI ドライバです。
ここで、csi-cephfs*は CephFS に、csi-rbd*は RBD に対応します。
CSI の Pod では、 Rook ではなく Ceph プロジェクトが公式に提供する Ceph CSI ドライバである ceph-csi コンテナが起動している様です。
rook-ceph-mon-*, rook-ceph-mgr-*は、それぞれ 先で述べた MON, MGR に対応します。
-w 等のオプションを付けて kubectl get してみると確認できますが、Rook-operator は最初に MON を起動します。
これは、MON を作って初めて、Ceph クラスタの構築準備を進められるからです。
これらの Pod が使うコンテナも Rook ではなく、Ceph プロジェクトが提供する Ceph のコンテナの様です。
rook-ceph-osd-prepare-*は OSD を初期化するための Pod です。
こいつが OSD を初期化して正常終了した後はrook-ceph-osd-*が立ち上がって OSD として動作します。
この時、該当の RAW デバイスがないと、OSD は起動してくれません。
これらは俗に OSD prepare Pod, OSD Pod 等と呼ばれ、OSD prepare Pod と OSD Pod が一つの OSD についてニコイチで存在します。
つまり、例えば、OSD が 10 個ある環境では OSD prepare Pod と OSD Pod がそれぞれ 10 個存在することになります。 CSI, MON, MGR と同様に、OSD prepare Pod と OSD Pod も Ceph プロジェクトが提供する Ceph コンテナを使います。
OSD prepare Pod は Job によって、OSD Pod は Deployment によって作成されます。
デプロイが完了した後、rook-ceph-osd-prepare-* のステータスは Completed となります。
rook-ceph-toolsは開発者サイドから Ceph クラスタの状態を監視するため、こちら を参考にデプロイしました。
Ceph クラスタの確認
toolbox をデプロイして Ceph のステータスを確認します。
今回は、3 ノードのそれぞれに 1 GiB のブロックデバイスを 10 個追加しているので、全体として 30 GiB の分散ストレージとして機能していることが分かります。
また、仮想マシンのディスクパーティションを確認してみると、/dev/vdb/vdb1 が OSD によって認識されていることが分かります。
これで、Rook/Ceph のデプロイは完了です。
S3 互換のオブジェクトストレージを構築
ブロックストレージの追加
Rook/Ceph クラスタの構築が完了したら、分散ストレージを構築するためにブロックストレージを追加します。
こちら を参考に CephBlockPool(CRD) を追加します。
MinIO の導入

今回は、Amazon S3 と互換性のある API で操作可能な MinIO を使用します。
MinIO も CNCF cloud native landscape にあるプロジェクトの一つです。
※ MinIO(みん・あいおー)と読むらしい。
MinIO の詳細なコンポーネントに関する説明は省きますが、大きく MinIO Operator と MinIO Tenant という概念が存在します。 MinIO Operator は、Kubernetes で MinIO を扱うためのオペレーターで、MinIO Tenant が実際にバケットを構築するコンポーネントになります。
手っ取り早く こちら の Helm チャートを用いて minio-operator と minio-tenant をデプロイします。
Service エンドポイントにポートフォワードしてクラスタネットワークに繋ぎます。
- https://localhost:9443/browser(※ HTTPS でアクセスする!)
(実運用だと一々ポートフォワードするのは現実的でないので、Kubernetes クラスタに MetalLB L2Advertisement を導入して、type: LoadBalancer を使用し、DHCP で LAN の IP アドレスを Service に直接割り当てるようにしています。)
以下のような画面が表示されたら、Rook/Ceph による分散ストレージおよびオブジェクトストレージの構築は完了です。
- MinIO Operator

初回ログイン時のトークンは、以下のワンライナーコマンドで取得できます。


- MinIO Tenant(Console)


- ArgoCD Web UI からデプロイされたリソースを確認してみる
(リソースの数は kube-prometheus-stack を遥かに上回ってる...)

今回は特に事前知識が要される作業でした。
Tips:トラブルシューティング
rook-ceph ネームスペースが Terminating 状態になった場合
- マニフェストを json として吐き出す
spec.finalizersの配列の中身を空に変更する
- json データを元に、マニフェストにパッチを当てる
Custom Resource の削除
Troubleshooting を参考
-
CephCluster が Deleting フェーズにあることを確認
-
全ての Custom Resource を削除
-
【各ノードで実行】Ceph クラスタのデータを削除
まとめ
これにて、無事、プライベートクラウドに分散ストレージサービスを構築することができました!やっと研究が進みそう。
あ、なんでパブリッククラウド初めから使わないのって?
だって、面白くないじゃん。 以上 😇
今回使用したコードは以下のリポジトリにあります。
- Rook/Ceph・MinIO Kustomize マニフェスト
- オブジェクトストレージを操作するための API(適当に書いた)