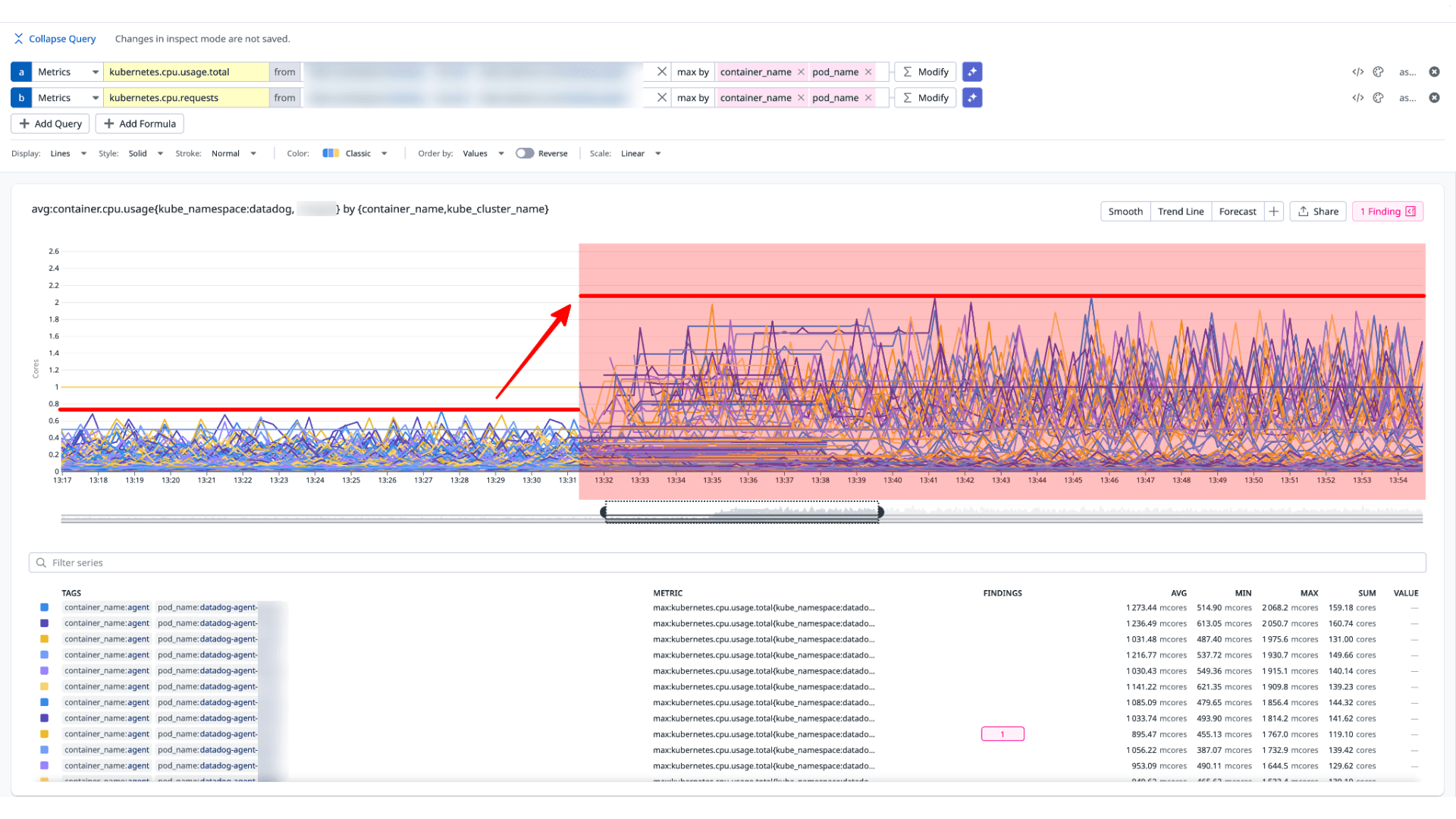
Datadog Agent を v7.66 から v7.76 にアップグレードしたところ、agent コンテナの CPU 使用率が 2〜3 倍に急増する問題を引きました。影響は istio-proxy が多数稼働するノードに集中しており、Agent が内部で利用する Python ベースの prometheus-client ライブラリのパーサ回帰によって、Prometheus テキスト形式のパース処理コストが大幅に増大したことが原因でした。今回のブログでは flare を使った原因の絞り込み方、パーサ回帰の技術的な詳細と特定の環境で影響が顕著になった理由、現時点でのコミュニティの認識と対応方針について整理したいと思います。
- Published on