BGP-ECMP で SNAT を回避した負荷分散を構成
はじめに
Kubernetes でリクエストを Pod に負荷分散する際にクライアントの送信元 IP アドレスを保持したいケースがあります。 LoadBalancer や NodePort を使用する Service の場合、負荷分散の過程で送信元 IP アドレスが NAT(SNAT:Source NAT)されるため、Pod に到達するパケットからはクライアントの IP アドレスを知ることができません。
Service の External Traffic Policy を Local に設定すると、外部からのトラフィックは受信したノード上の Pod にのみ転送されるため SNAT は回避できますが、単一ノードにトラフィックが集中するためクラスタワイドな負荷分散ができません。
また、Ingress Controller を利用すると HTTP X-Forwarded-For ヘッダに送信元情報を付加することができますが、L7 LB が前提となるため、L4 LB のような低レベルロードバランサでは有効に機能しません。
ベアメタル Kubernetes でネットワークロードバランサをプロビジョニングするための代表的な OSS に MetalLB があります。 MetalLB には L2 モードと BGP モードの 2 種類の負荷分散方式が用意されています。 多くの場合は前者が利用されますが、後者の BGP モードでは、より柔軟なネットワーク構成や負荷分散の制御が可能になり、送信元 IP アドレスを保持したままリクエストを分散することができます。
今回のブログでは、MetalLB の BGP モードを利用して SNAT を回避しつつ、クラスタワイドな負荷分散を実現する構成について紹介したいと思います。
MetalLB

MetalLB:
Bare-metal cluster operators are left with two lesser tools to bring user traffic into their clusters, “NodePort” and “externalIPs” services. Both of these options have significant downsides for production use, which makes bare-metal clusters second-class citizens in the Kubernetes ecosystem. MetalLB aims to redress this imbalance by offering a network load balancer implementation that integrates with standard network equipment, so that external services on bare-metal clusters also “just work” as much as possible.
MetalLB は Kubernetes ネイティブな SLB(Software Load Balancer)で、ベアメタルクラスタにおいて外部からのアクセスを可能にするための Add-on です。
AWS / GCP / Azure 等のパブリッククラウドでは、type: LoadBalancer の Service マニフェストを適用すると、自動的にパブリック IP アドレスが割り当てられて外部からのアクセスが可能になります。
一方で、オンプレミス環境ではそのような仕組みが用意されておらず、type: LoadBalancer の Service を使用しても、外部からアクセスできる IP アドレスを自動的に割り当てることはできません。
そこで、MetalLB は Service をクラスタ外に公開するために、DHCP で LAN 内のアドレスプールからプライベート IP を払い出します。 その上で外部ネットワークとも接続する場合は、対象のプライベート IP アドレスを NAT して外向きに公開します。
MetalLB には IP アドレスを Service に割り当ててネットワーク上に通知する際に、L2 モードと BGP モードの 2 つの動作モードがあります。
L2 モード
L2 モードを利用した負荷分散については、一部 こちら のブログでも紹介しています。
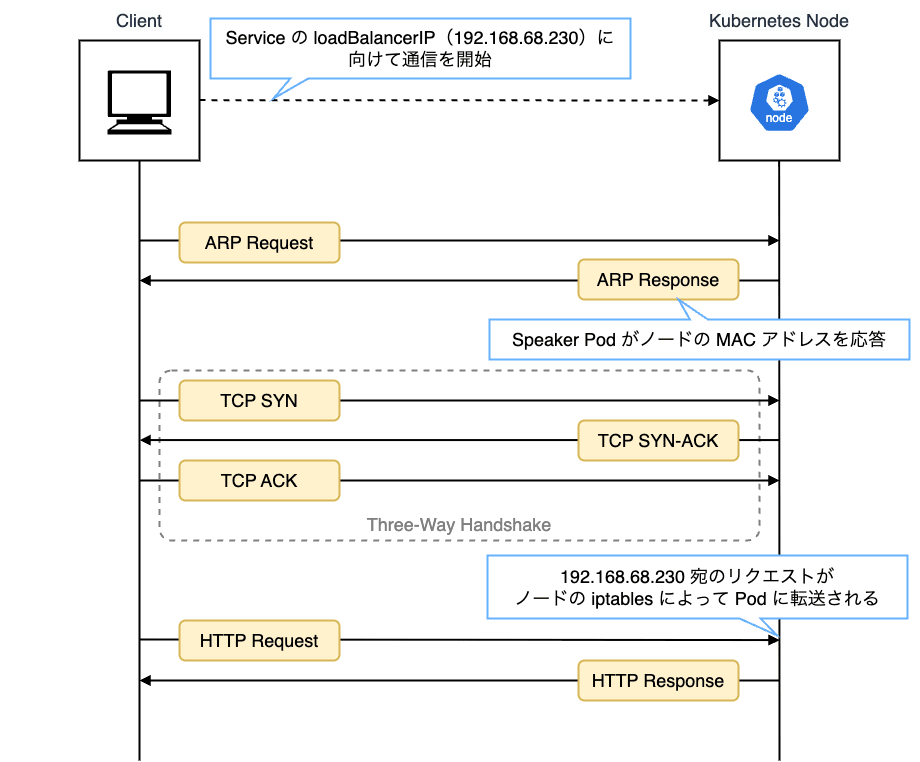
L2 モード は MetalLB で一般に利用される負荷分散方式で、到達性の確保に ARP(Address Resolution Protocol) または NDP(Neighbor Discovery Protocol) を使用し、ローカルネットワーク上に対象の IP アドレスをどのノードが持っているかを通知します。
これにより、MetalLB は同一 LAN 上で IP アドレスの所有者をエミュレーションし、クラスタ内のノードが外部から直接アクセス可能な LoadBalancer IP を仮想的に持つことができます。
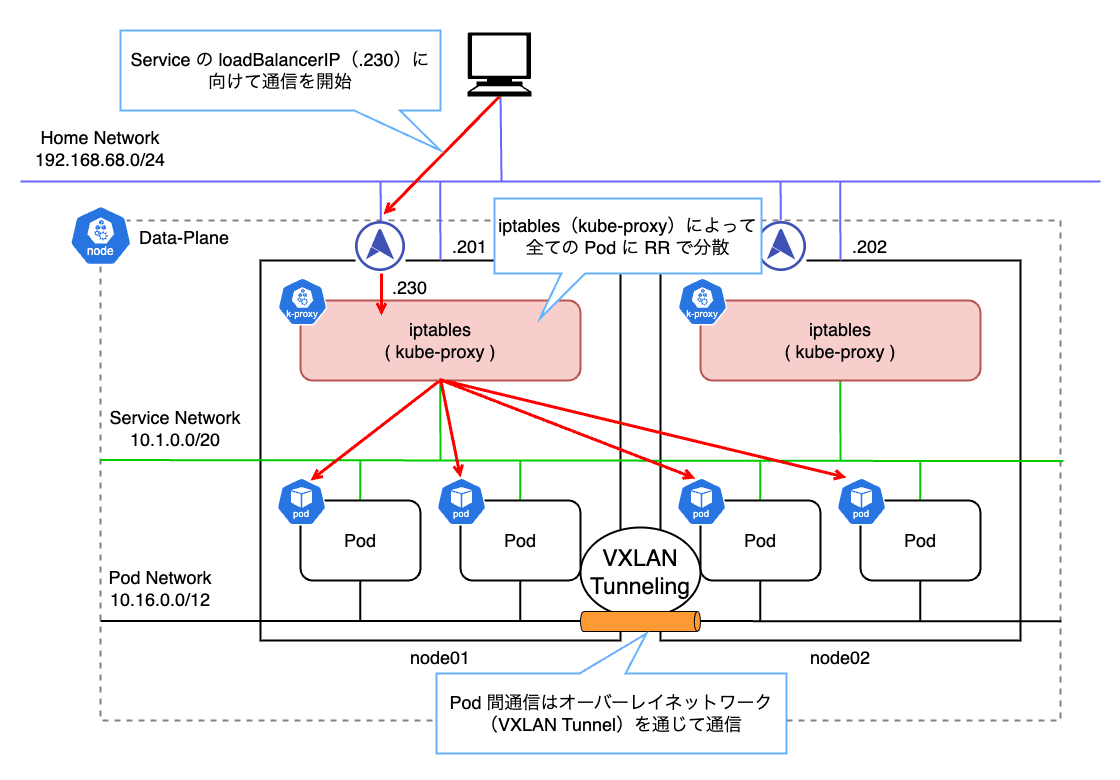
上の例では 192.168.68.230 という IP アドレスを持つ LoadBalancer に対して通信を開始すると、ARP によって node01 の MAC アドレスが返されます。
このように、同一ネットワーク上に存在しない IP アドレスから MAC アドレスを解決する特別な ARP を Proxy ARP と呼びます。
Proxy ARP による L2 通信で、一度 node01 がリクエストを受け取り、その後 kube-proxy が iptables によって背後の Pod に転送します。
ここで、実際に ARP レスポンスを返しているのは各ノードで起動する Speaker という MetalLB の Data-Plane コンポーネントです。
Speaker Pod のログを見てみると ARP リクエストを受け付けたログが確認できます。
また、node01 を確認すると以下のような Chain が追加されていることも確認できます。
それぞれ次のような Chain が追加されます。
KUBE-SERVICES
Kubernetes Services Chain は、サービス全体(ClusterIP / NodePort / LoadBalancer)のトラフィックを処理します。
外部からのリクエスト、もしくは Pod 内 / ノード上からのトラフィックが最初にマッチするトップレベルの Chain で、全てのリクエストに対して適用されます。 その後、Service IP(ClusterIP)や External IP、NodePort 等に対応した各個別の Chain へジャンプします。
KUBE-EXT-xxx
Kubernetes External Chain は、主に External IP(NodePort / LoadBalancer IP)を利用する Service へのトラフィックを処理します。
xxx の部分には Service 毎に一意なハッシュ識別子が付与され、該当するトラフィックに対してのみ適用されます。
主に、SNAT をマークして、対応する内部 Chain KUBE-SVC-xxx にジャンプします。
KUBE-SVC-xxx
Kubernetes Service Chain は、特定の ClusterIP に対応するトラフィックを処理します。
xxx の部分には Service 毎に一意なハッシュ識別子が付与され、該当するトラフィックに対してのみ適用されます。
特定の Service IP / Port に対するバックエンド Pod へのルーティングを、ランダムもしくはラウンドロビンによって決定します。
この時、条件によって SNAT が必要か確認し、必要なら KUBE-MARK-MASQ にジャンプします。
KUBE-SEP-xxx
Kubernetes Service End-Point Chain は、トラフィックを特定の Pod IP / Port に DNAT します。
xxx の部分には Service 毎に一意なハッシュ識別子が付与され、該当するトラフィックに対してのみ適用されます。
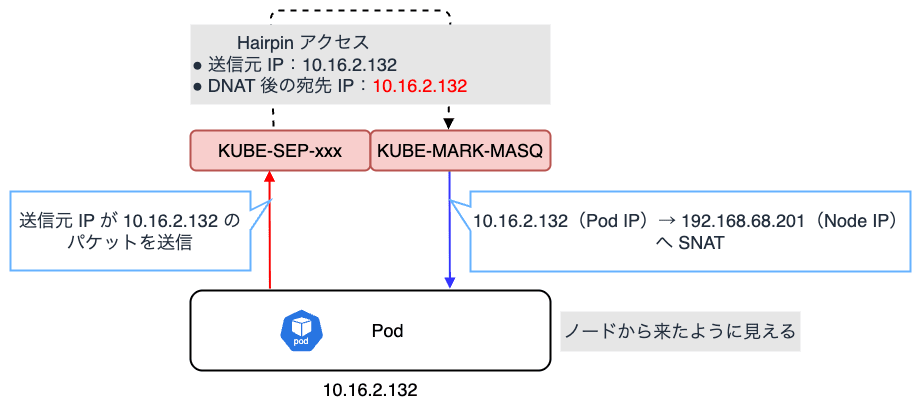
また、Hairpin アクセス検出時の SNAT にも対応します。
Hairpin(U-Turn)アクセス とは、Pod が自分自身と同じノード上の Service(ClusterIP や LoadBalancer IP)にアクセスし、再び同じノード内の同じ Pod に戻るようなアクセス形態を指します。
例えば、パケットの送信元 IP アドレスが Pod IP(10.16.2.132)の場合に KUBE-SVC-xxx で DNAT されると、場合によっては宛先として自身の Pod IP(10.16.2.132)が選出される可能性があります。
この場合、送信元も宛先も同じ IP アドレスのパケットになります。
これにより、カーネルのネットワークスタックが混乱し、正常に TCP コネクションが確立できなくなったり、パケットがループ・破棄されたりすることがあります。
kube-proxy はこの問題を認識しており、Hairpin アクセスの場合は SNAT によって送信元 IP をノードの IP アドレスに変換します。 これにより、あたかも外部からリクエストが来たかのように見せかけることで、前述の問題を解決します。参考
KUBE-MARK-MASQ
Kubernetes Mark-for-Masquerade Chain は、マークを利用して後続の Chain で SNAT を指示します。
具体的には、Postrouting で使用するマーク(0x4000)を付与します。
後続の処理でこのマークが付いたトラフィックのみが SNAT の対象となります。
KUBE-POSTROUTING
Kubernetes Postrouting Chain は、NAT テーブルの Postrouting Chain で、KUBE-MARK-MASQ でマーク(0x4000)が付与された Egress 通信を SNAT します。
マークが無い場合は、そのままトラフィックを通過させます。
FLANNEL-POSTRTG
Flannel Postrouting Chain は、Flannel が追加する Postrouting Chain で、トラフィックを SNAT します。

Flannel は、クラスタ内の Pod ネットワークを構築するための CNI(Container Network Interface) プラグラインで、Pod 間での VXLAN ベースのオーバーレイネットワーク通信を可能にします。 これにより、異なるノード間の Pod が直接通信できるようになります。
このルールは kube-proxy が生成した Chain の評価を終えた後、SNAT が必要な場合のみ、Postrouting で処理します。
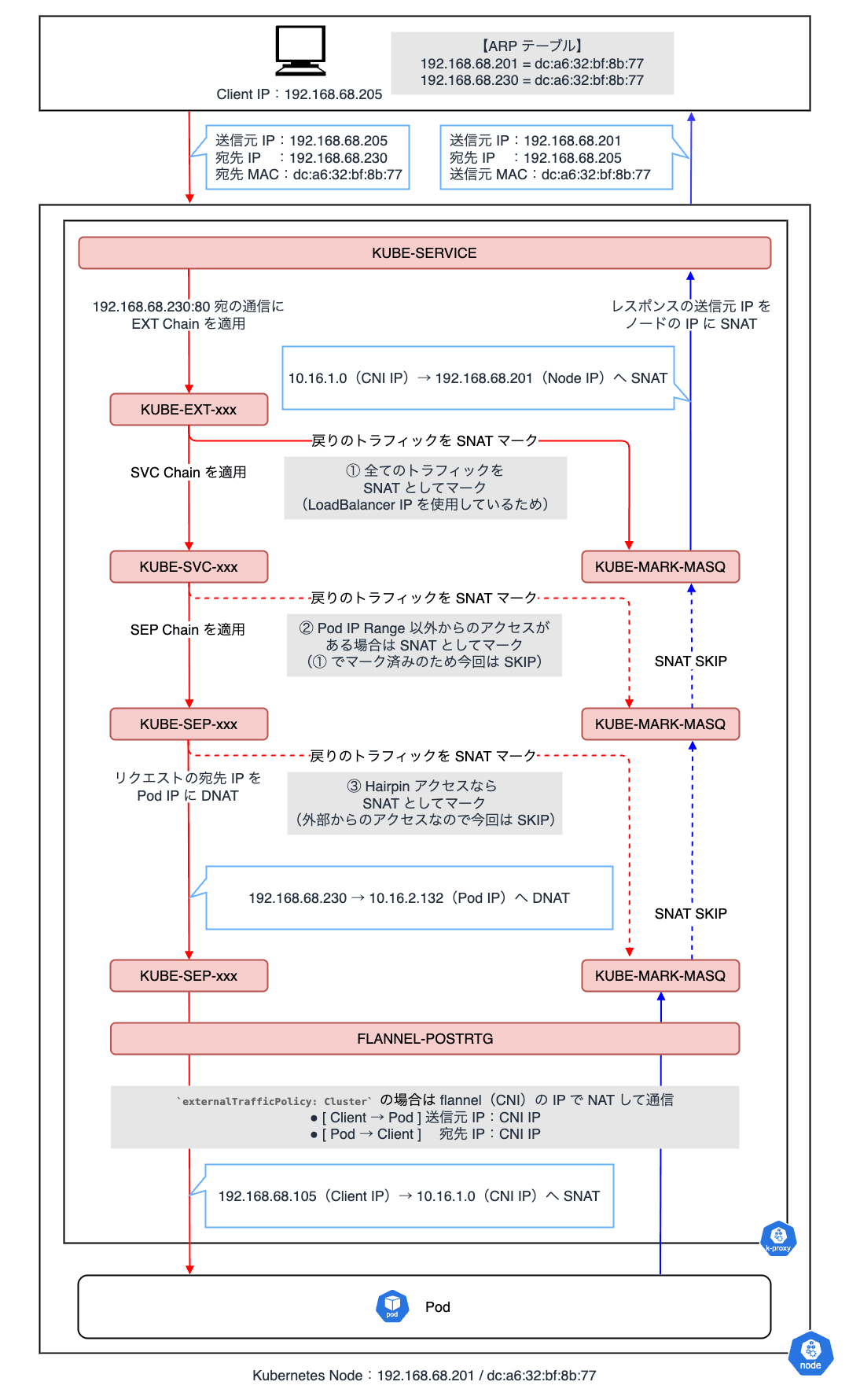
externalTrafficPolicy: Cluster(デフォルト)の場合- 各ノードに到達したパケットが kube-proxy の iptables で DNAT された後、Flannel の NIC IP で SNAT して Pod に転送される
externalTrafficPolicy: Localの場合- 各ノードに到達したパケットが kube-proxy の iptables で DNAT された後、SNAT することなく、そのノード上の Pod に直接転送される
- LoadBalancer からのリクエストはローカルノードの Pod のみにしかルーティングされないため SNAT が不要になり、Pod からクライアントの送信元 IP を確認することができる
今回の場合は、node01(192.168.68.201)がリクエストを受け取り、kube-proxy によって対象 Pod(10.16.2.132)に宛先 IP アドレスを DNAT しています。
また、対象 Pod は node02(192.168.68.202)に存在するため、Flannel CNI の IP アドレス(10.16.1.0)で SNAT した後、VXLAN オーバーレイネットワークを介して node02 の Pod に転送される挙動となります。
実際に、externalTrafficPolicy: Cluster の Service を利用する Pod の受信パケットを確認すると、送信元 IP アドレスが Flannel の NIC IP アドレス(10.16.1.0)で SNAT されていることが分かります。
これらのフローを図に起こすと次のようになり、クライアントからのリクエストは、クラスタネットワーク内で適切な IP アドレスに変換され、最終的に Pod に到達します。
L2 モードの注意点
前述の動作から察する通り、L2 モードはロードバランサと言いつつも、Service の IP を持ったノードがダウンした場合に、別のノードに切り替えるフェールオーバで冗長化しています。 L2 モード利用時は、常に単一ノードにトラフィックが集中するため単一障害点(SPOF:Single Point of Failure)とりなり、負荷分散の観点であまり効果的ではありません。
また、実際に負荷分散しているのは MetalLB ではなく kube-proxy(iptables)ということになります。
BGP モード
BGP モード は各ノードがクラスタの前段に配置されたネットワーク上のルータと BGP ピアリングを組み、対象 Pod が存在するノードを広報することで到達性を確保します。
BGP モードでは、ECMP(Equal Cost Multi-Path)ルーティング で複数のノードにリクエストを分散するクラスタワイドな負荷分散となります。 このため、単一ノードがリクエストを受け取る L2 モードと比較して、ノード間での負荷分散が可能なため、冗長性・分散性が高く、柔軟な制御も可能になります。
負荷分散の正確な動作は BGP ルータによって異なりますが、基本的にはパケットハッシュによって通信毎に特定のノードに振り分けます。 パケットハッシュとは、ネットワーク上を流れるパケットの属性を元に、ハッシュ関数を使って値を割り当てる仕組みです。
BGP の ECMP では、パケットのフィールドの一部をシード(キー)として使用し、接続先を決定します。 シードが同じ値であれば接続先も同じになります。
3 タプルハッシュ
- 「プロトコル」「送信元 IP」「宛先 IP」をシードとして使用
- 2 つの一意の IP 間の全てのパケットが同じノードに送信される
5 タプルハッシュ
- 「プロトコル」「送信元 IP」「送信元ポート」「宛先 IP」「宛先ポート」をシードとして使用
- 単一クライアントから送信される異なるリクエストをクラスタ全体に分散する
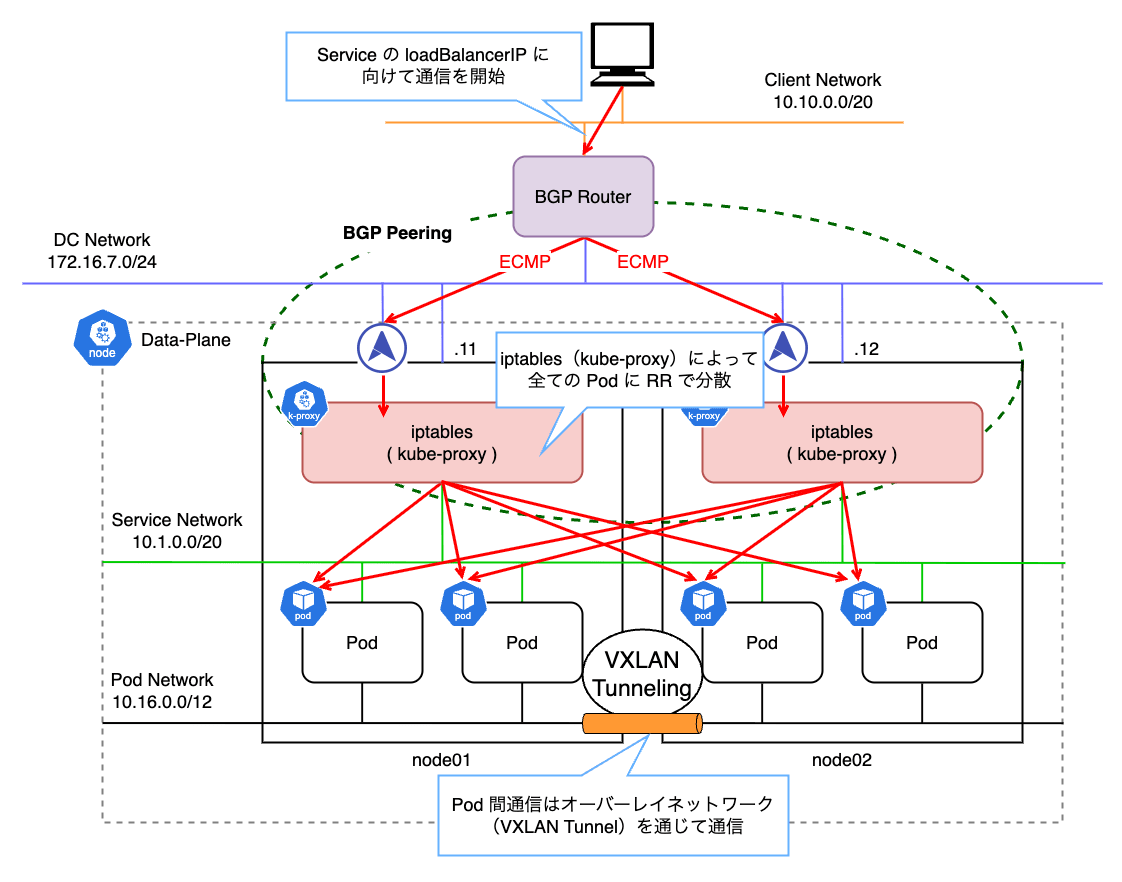
BGP ルータが、宛先 IP に対して各ノードを Next Hop として指定することで負荷分散を実現しています。
上の例では、172.16.7.0/24 ネットワーク上に存在するノードが Next Hop となり、パケットハッシュに基づいて ECMP で順に振り分けられます。
BGP モードの注意点
BGP モードを選択すると標準のルータを使用できるメリットがありますが、接続先のノードや Pod が停止した際に、全ての接続が切断される点に注意が必要です。
BGP ルータはハッシュを用いてステートレスに負荷分散しますが、クラスタからノードを削除したり、ノードアップグレード等の度に再起動したりするとハッシュが更新されるため、既存のコネクションは全て切断されます。
対応策としては以下のような方法があります。
- BGP ルータで安定した ECMP ハッシュアルゴリズム(resilient ECMP または resilient LAG)を利用する
- 既存コネクションへの影響を最小限に抑える
- 戦略的なノードアップグレードの実施
- ノードを停止する場合は夜間に行う
- 起動する Kubernetes の Servie と Pod を別の IP で起動して DNS を用いて向き先を変更し、流入が無くなったノードから停止する
- Service を Ingress Controller の背後に配置する
- L7 LB を利用する場合は、ルータ → Ingress → Service とすることで、Ingress に変更が無ければコネクション切断は発生しない
また、BGP モードは MetalLB 単体で動作するわけではないため、必ず BGP を喋れるルータが必要になります。 このため、BGP のピア設定や経路制御等、Kubernetes とは別でネットワーク領域の知識が必要になります。
管理・運用・制御の観点では L2 モードを遥かに上回る複雑さがあるため導入難易度は高いと言えます。
External Traffic Policy
External Traffic Policy は、Service に到達したトラフィックを、どのノードや Pod に転送するかを制御する機能です。
Service のデフォルトの External Traffic Policy は Cluster となっているため、どのような方法で負荷分散したとしても最終的には kube-proxy(iptables)によって Pod 間の負荷分散が発生します。
その結果、リクエスト元の IP アドレスが常に SNAT されることになり、Pod に到達したパケットからはクライアントの送信元 IP アドレスを確認することができません。
クライアント IP アドレスを取得するには、External Traffic Policy を Local に設定します。
これにより、kube-proxy による負荷分散の際に SNAT されないため、Pod に着信したパケットからクライアントの送信元 IP アドレスを確認することができます。
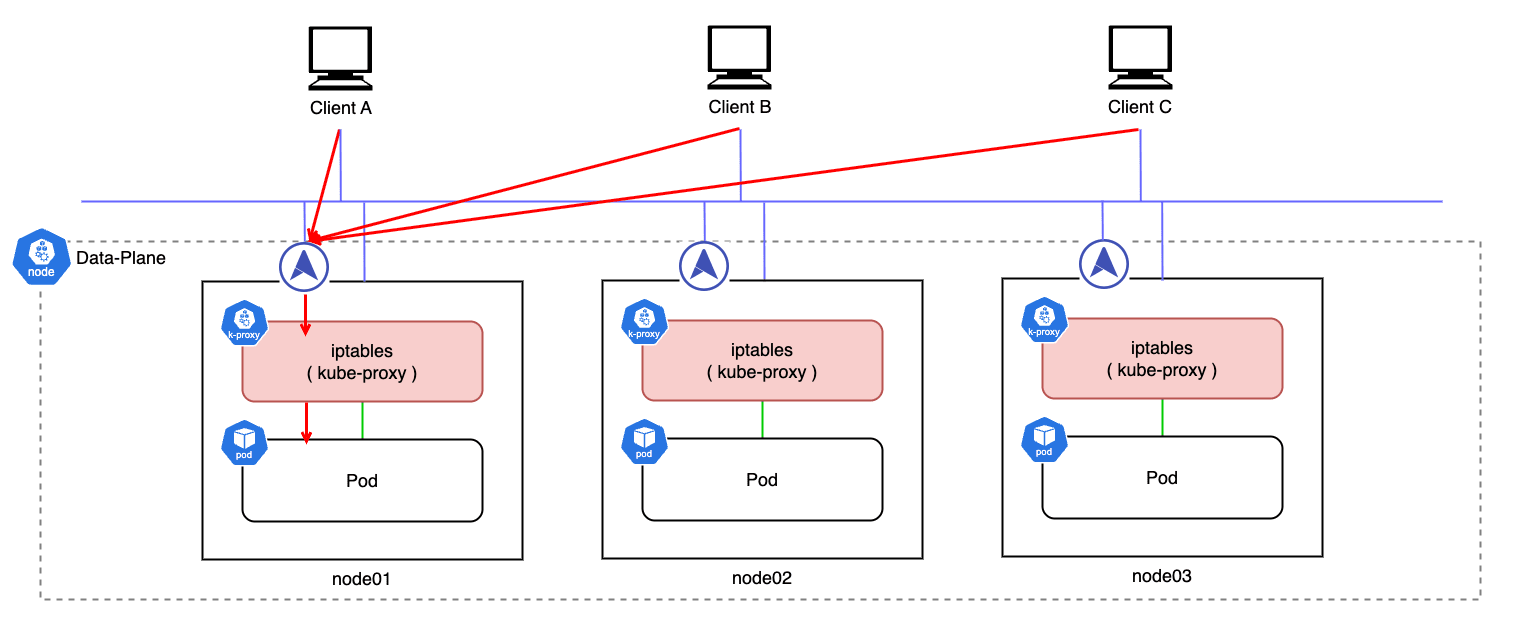
L2 モードの課題
L2 モードで External Traffic Policy Local を使用すると、一つのノードで全てのトラフィックを処理しなければならず、単一障害点を抱えるため可用性の観点で課題があります。
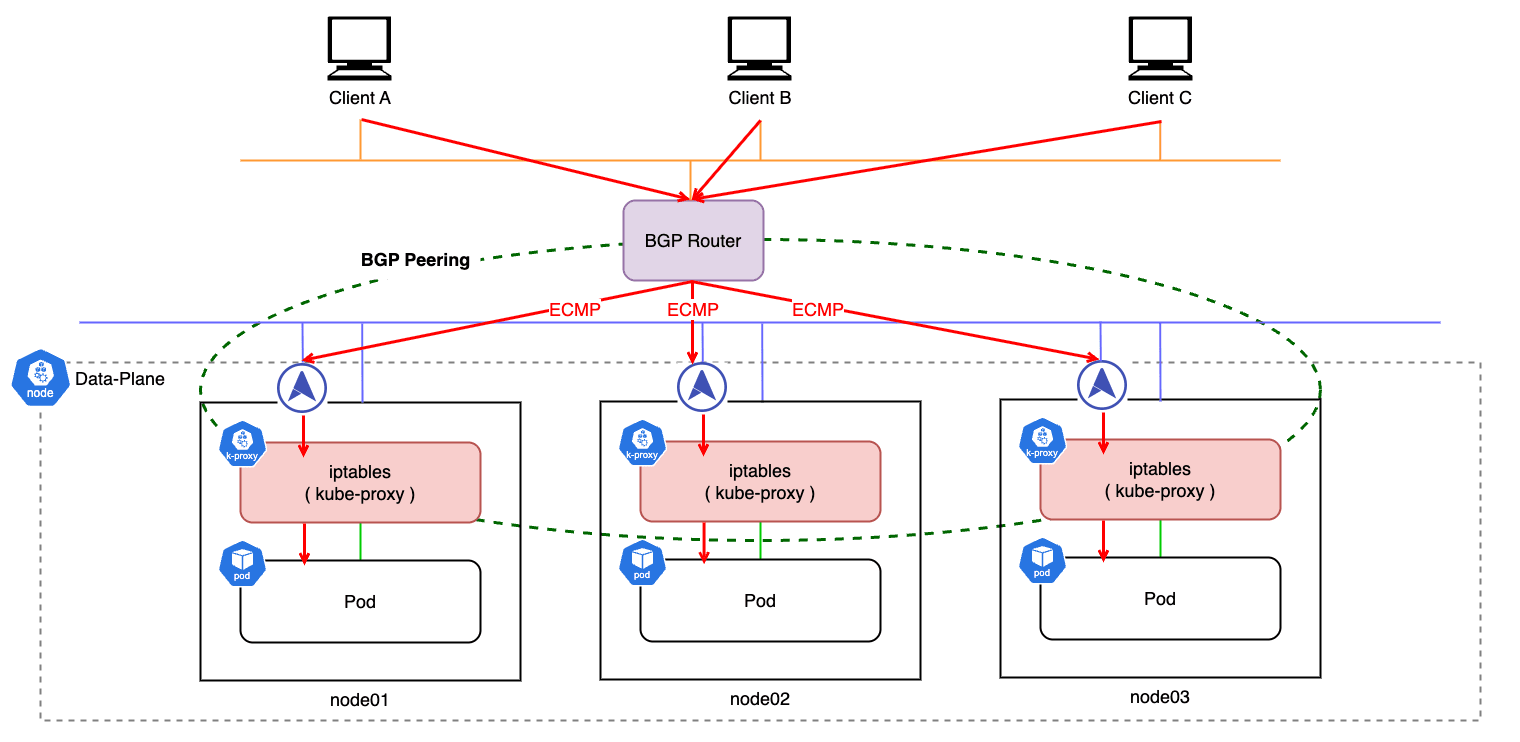
BGP モードの利点
BGP モードはパケットハッシュに基づき、各ノードに ECMP でトラフィックを分散させます。
つまり External Traffic Policy を Local に設定した場合も、ノードレベルの負荷分散が効いているため、単一障害点を回避しつつクラスタ内の Pod に均等に負荷分散することが可能です。
これにより、高度な負荷分散と可用性の機能を維持しつつ、クライアントの送信元 IP アドレスも保持することが可能 です。
BGP-ECMP を利用した負荷分散
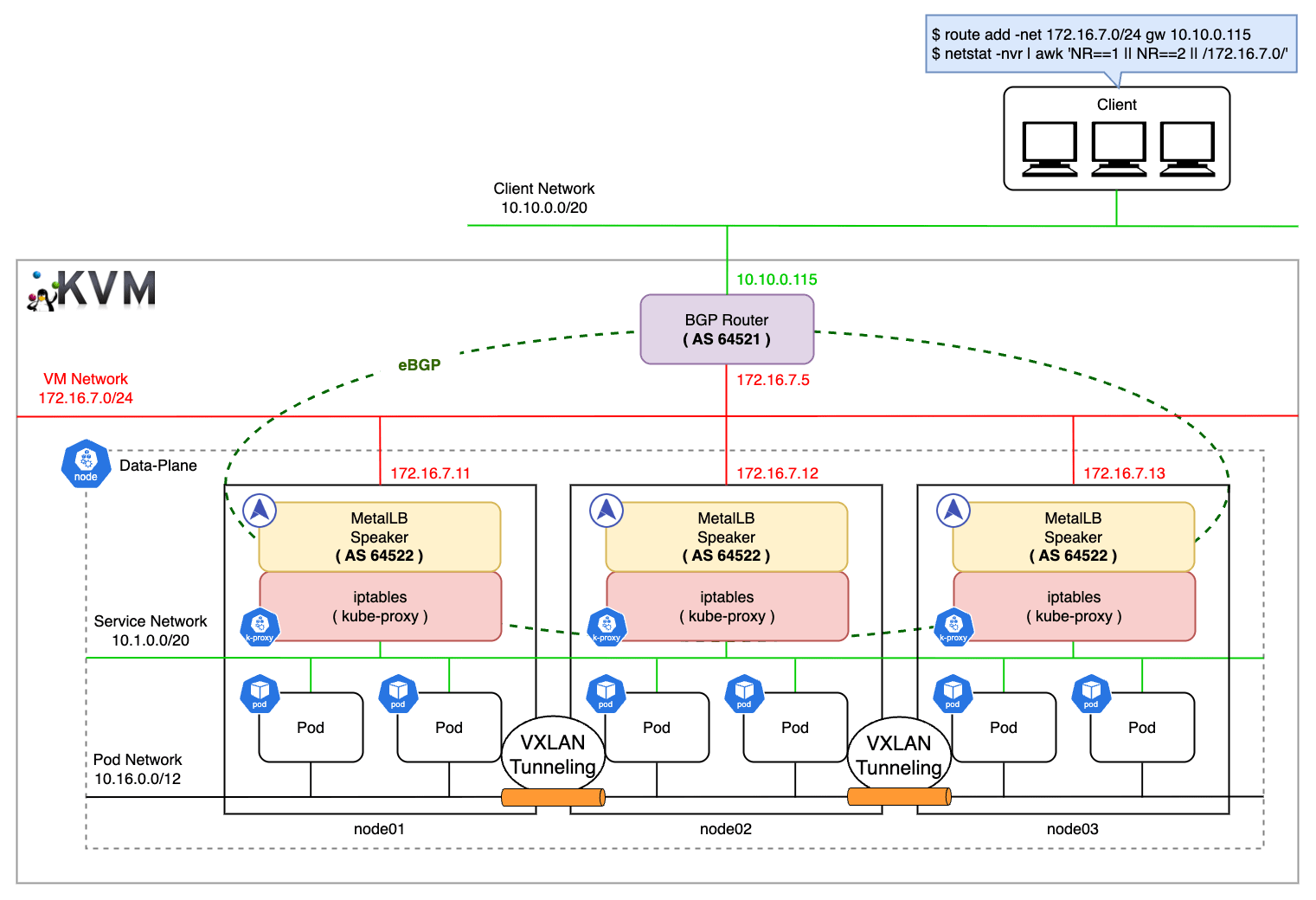
MetalLB BGP モードを利用して負荷分散を検証してみます。
BGP モードを利用する場合、別途 BGP ルータを準備する必要がありますが、今回は SOHO(Small Office / Home Office)ネットワークで検証するため仮想環境を構築し、ソフトウェアルータとして VyOS を利用します。

VyOS は OSS として公開されている NOS(Network Operating System)で、商用ルータやファイアウォールアプライアンスと同等の機能を Linux 環境上で実現できます。
また、仮想マシンイメージ も用意されているため、KVM を利用して容易に環境構築をすることができます。
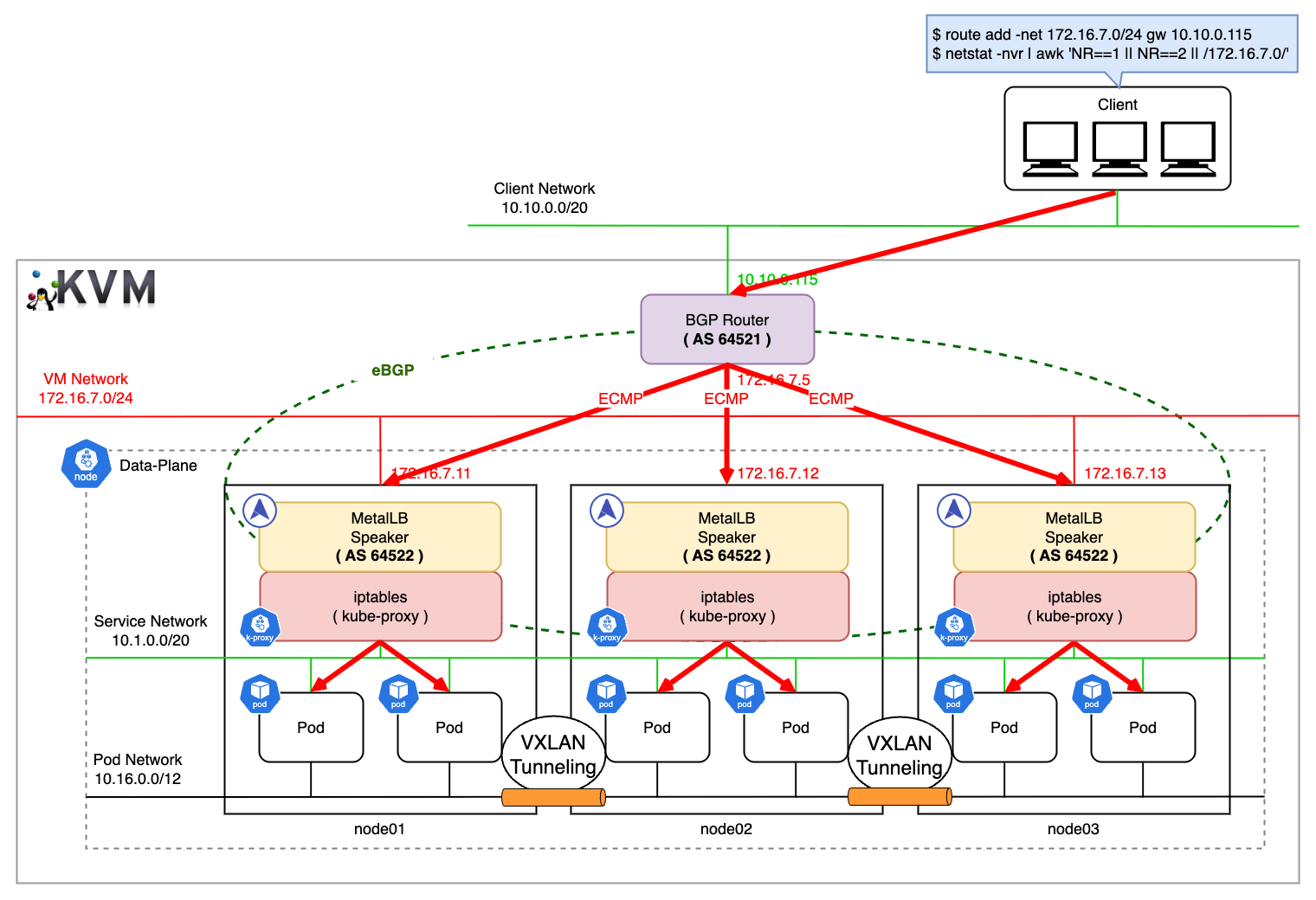
検証環境
Kubernetes クラスタと VyOS は Vagrant を利用して KVM 上に構築します。
実際に BGP を利用する場合、クラスタが接続する BGP ルータと、その対向ルータを準備して各々でピアリングを組みますが、今回は VyOS とクラスタの間にのみピアリングを設定し、クライアントからのリクエストが VyOS の外部インターフェースに向くようにスタティックルートを構成することで、擬似的に経路広報を再現します。
仮想マシン
- Control Plane(Master Node 1 台)
| スペック | |
|---|---|
| 仮想マシン | Vagrant v2.2.19 / libvirt v8.0.0 / qemu v6.2.0 |
| OS | Ubuntu 20.04.6 (Focal Fossa) 64 bit |
| CPU | Intel(R) i9-11900K @3.50GHz 8cores 16threads |
| アーキテクチャ | amd64 |
| RAM | 32 GiB DDR4-3200 |
- Data Plane(Worker Node 3 台)
| スペック | |
|---|---|
| 仮想マシン | Vagrant v2.2.19 / libvirt v8.0.0 / qemu v6.2.0 |
| OS | Ubuntu 20.04.6 (Focal Fossa) 64 bit |
| CPU | Intel(R) i9-13900 @5.60GHz 24cores 32threads |
| アーキテクチャ | amd64 |
| RAM | 24 GiB DDR4-3200 |
- BGP Router
| スペック | |
|---|---|
| 仮想マシン | Vagrant v2.2.19 / libvirt v8.0.0 / qemu v6.2.0 |
| OS | VyOS 1.5 (Circinus) 64 bit |
| CPU | Intel(R) i9-11900K @3.50GHz 8cores 8threads |
| アーキテクチャ | amd64 |
| RAM | 4 GiB DDR4-3200 |
ネットワーク構成
| 設定内容 | |
|---|---|
| Peer ネットワークアドレス | 10.10.0.0/20 |
| BGP ルータの IP | 172.16.7.5 |
| BGP ルータの外部 IP | 10.10.0.115 |
| BGP ルータの AS 番号 | 64512 |
| BGP ルータの ID | 1.1.1.1 |
| 設定内容 | |
|---|---|
| ネットワークアドレス | 172.16.7.0/24 |
| Service IP 範囲 | 172.16.7.192/26 (62 個確保) |
| node01 の IP | 172.16.7.11 |
| node01 MetalLB の AS 番号 | 64522 |
| node02 の IP | 172.16.7.12 |
| node02 MetalLB の AS 番号 | 64522 |
| node03 の IP | 172.16.7.13 |
| node03 MetalLB の AS 番号 | 64522 |
仮想マシンの構築
事前に Vagrant プラグインをホストマシンにインストールしておきます。
以下の Vagrantfile でゲスト VM を起動し、クラスタを構築します。
Vagrantfile
※ クラスタ自体の構築手順は省きます。
BGP ルータの設定
次に、VyOS に接続します。
以下のコマンドを順に実行して BGP ルータおよび AS(Autonomous System) を構成します。 AS は BGP ルーティングにおける個々の独立したネットワーク単位で、各 AS にはグローバルネットワークにおける識別子として一意な ASN(Autonomous System Number) が付与されます。
今回は、VyOS の ASN に 64512 を、各ノードの ASN に 64522 を指定して BGP ピアリングを構成しています。 64512 や 64522 はインターネット上でグローバルにルーティングされない プライベート ASN として予約されています。
これらの設定は、下記の vbash(vyatta-bash) スクリプトを実行することで CaC として管理することもできます。
router-config.sh
VyOS は設定内容を /config/config.boot に保存します。
この時点では、全ての BGP ピア(各ノード)との接続状態が Active ですが、BGP セッションは未だ確立されていない(never)ことが分かります。
BGP で受信したネットワークプレフィックスの一覧を確認します。
最初の段階では、自ルータが保有する 10.10.0.0/20 のみを外部に広報している状態です。 VyOS による経路広報先は各ノードに DaemonSet でデプロイされた Speaker Pod になります。
これらの情報は show bgp neighbors で詳細に確認することもできます。
MetalLB の設定
次に、クラスタに MetalLB をインストールして BGP モードを構成します。
MetalLB 自体のインストールは Bitnami の Helm Chart を使用しました。
以下のカスタムリソースを適用することで、MetalLB の BGP モードを有効化し、前で設定した VyOS と BGP ピアリングを組みます。参考
IPAddressPool は、MetalLB が LoadBalancer Service に割り当てる IP アドレスプールを定義します。
BGPPeer は、MetalLB が BGP 経路上のピアとして接続する近隣の BGP ルータ(VyOS)を定義します。
今回は、ノードから見た時にグローバル IP アドレスとして見えるように VyOS の外部 IP アドレス(10.10.0.115)を指定します。
BGPAdvertisement は、指定した IP アドレスプールを、どのピアに向けて、どのように広報するかを定義します。
今回は Service に割り当てるアドレスプールとして 172.16.7.192/26 を予約しているため、この範囲から払い出された IP アドレスが BGP ルータへ広報されます。
ArgoCD をデプロイするとコンポーネント一覧を視覚的に把握することができます。
- ワークロード
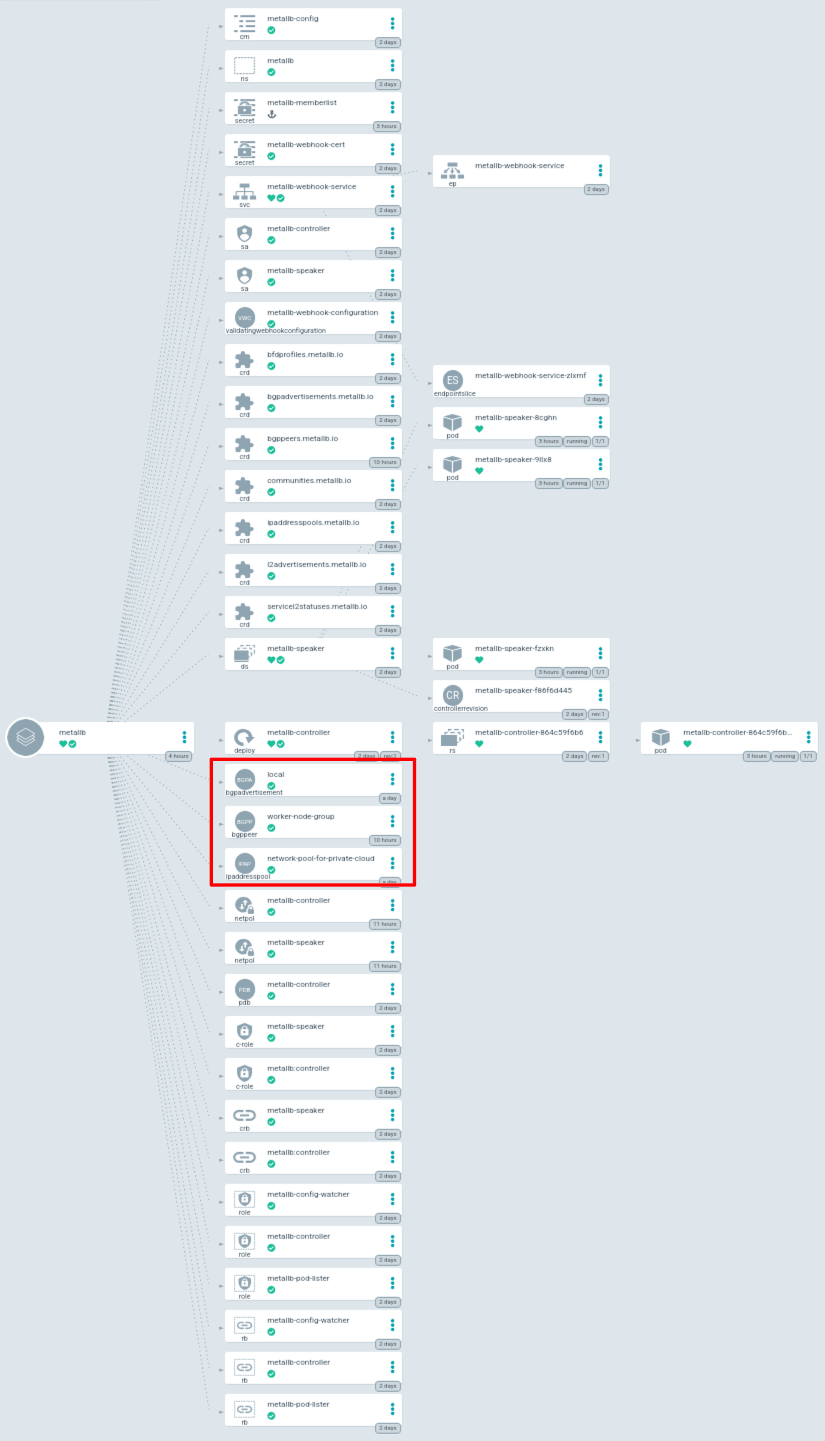
- ネットワークリソース
スタティックルートの追加
検証環境では VM のプライベートネットワークを利用しており、対向ルータがクライアントネットワークに存在しないため、クライアントマシンは 172.16.7.0/24 のネットワーク情報を知りません。 そのため、172.16.7.0/24 への通信は VyOS の外側の IP アドレス(10.10.0.115)を経由するようにスタティックルートを追加することで、この IP 範囲対する通信が BGP ルータを通過するように構成します。
同様に、各ノードに対してもクライアントネットワーク側に BGP ルータを経由して到達できるようにスタティックルートを追加します。 これにより、戻りのトラフィックが VM ネットワーク内の他のルートに吸われることなく、常に BGP ルータを経由するようになります。
※ 実際の運用では、近隣ルータ間で BGP ピアリングによる経路交換を設定することが殆どなので、スタティックルートを追加する必要はありません。
BGP セッションの確認
以上の構成により、クラスタと VyOS の間は eBGP でピアリングが組まれた状態となります。
Speaker Pod が起動し、VyOS との BGP ピアリングが組まれると、BGP セッションが確立されます。
送信元 IP アドレスを保持した負荷分散
MetalLB BGP モードを利用した ECMP による負荷分散を確認します。
今回は、クライアントの情報を Pod で確認するために、こちら で準備したカスタムの Nginx イメージを利用します。
server.js
カスタムイメージは、Express で簡単なエコーサーバを起動し、アクセス元のクライアント情報、サーバ情報、ヘッダ等を整形してレスポンスとして返す簡易的なものです。
以下のマニフェストを適用して Nginx Pod をデプロイします。
nginx.yaml
Service の External Traffic Policy を Local に設定することで、ECMP で負荷分散された後はローカルノード内の Pod にルーティングするようにします。
これにより、送信元 IP アドレスを維持しつつ、クラスタワイドな負荷分散を実現します。
クライアントからアクセスしてみると、送信元 IP アドレスが保持されていることが確認できます。
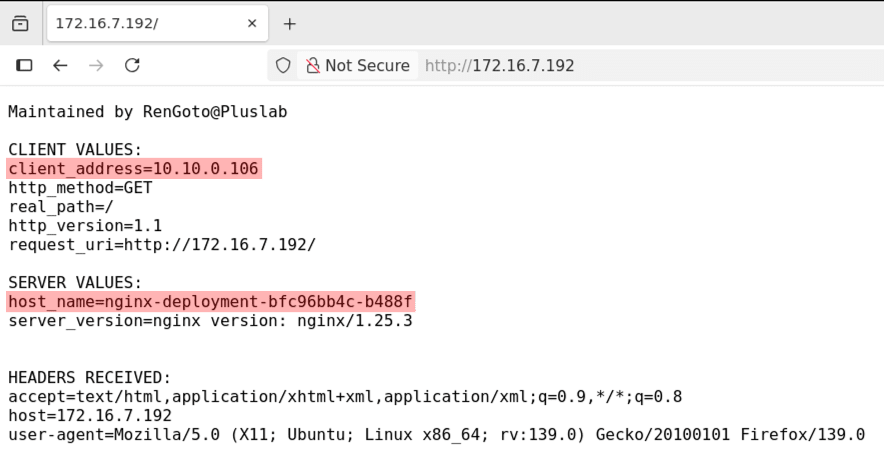
また、実際にリクエストを返したのは node03 にデプロイされた nginx-deployment-bfc96bb4c-b488f という Pod であることが分かります。
BGP ルータを確認すると 172.16.7.192/32 というプレフィックスに対して、各ノードへの経路が学習されており、ECMP 構成になっていることが分かります。
また、現在のベストパスは node03 となっており、これによってクライアントからのリクエストが node03 の Pod にルーティングされたことが分かります。
172.16.7.192/32 というプレフィックスの経路広報は Speaker Pod(ASN:64522)によって行われています。
node03 の Speaker Pod のログを確認してみます。
次に、複数のクライアントマシンを準備してリクエストを送ってみます。
Vagrantfile
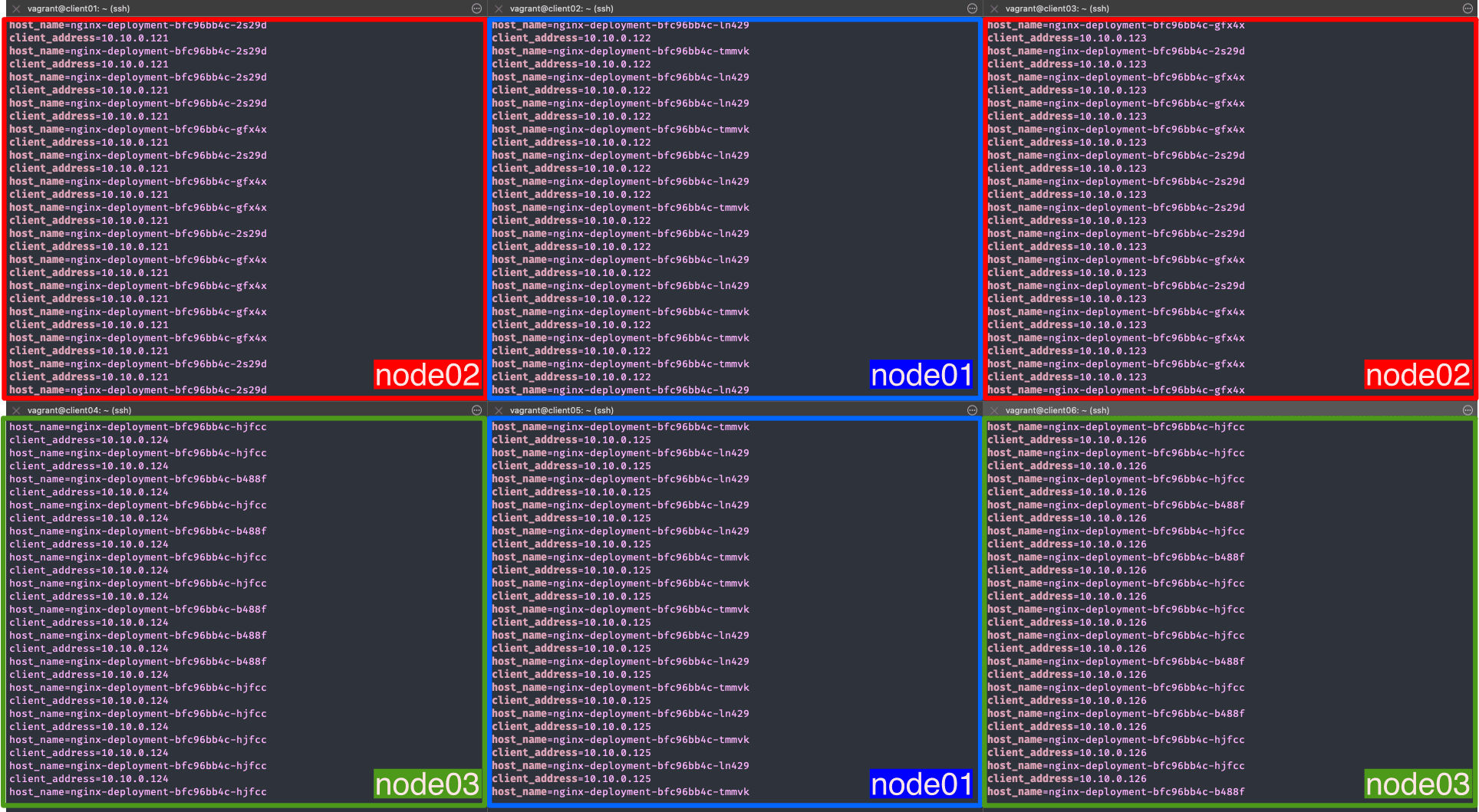
6 台のクライアントのリクエストは次のように分散されたことが分かります。
- client02 と client05 → node01 の Pod
nginx-deployment-bfc96bb4c-tmmvknginx-deployment-bfc96bb4c-ln429
- client01 と client03 → node02 の Pod
nginx-deployment-bfc96bb4c-gfx4xnginx-deployment-bfc96bb4c-2s29d
- client04 と client06 → node03 の Pod
nginx-deployment-bfc96bb4c-hjfccnginx-deployment-bfc96bb4c-b488f
実際に ECMP でノード間で負荷分散しつつ、Pod に着信したパケットから送信元 IP アドレスも保持できていることが確認できました。
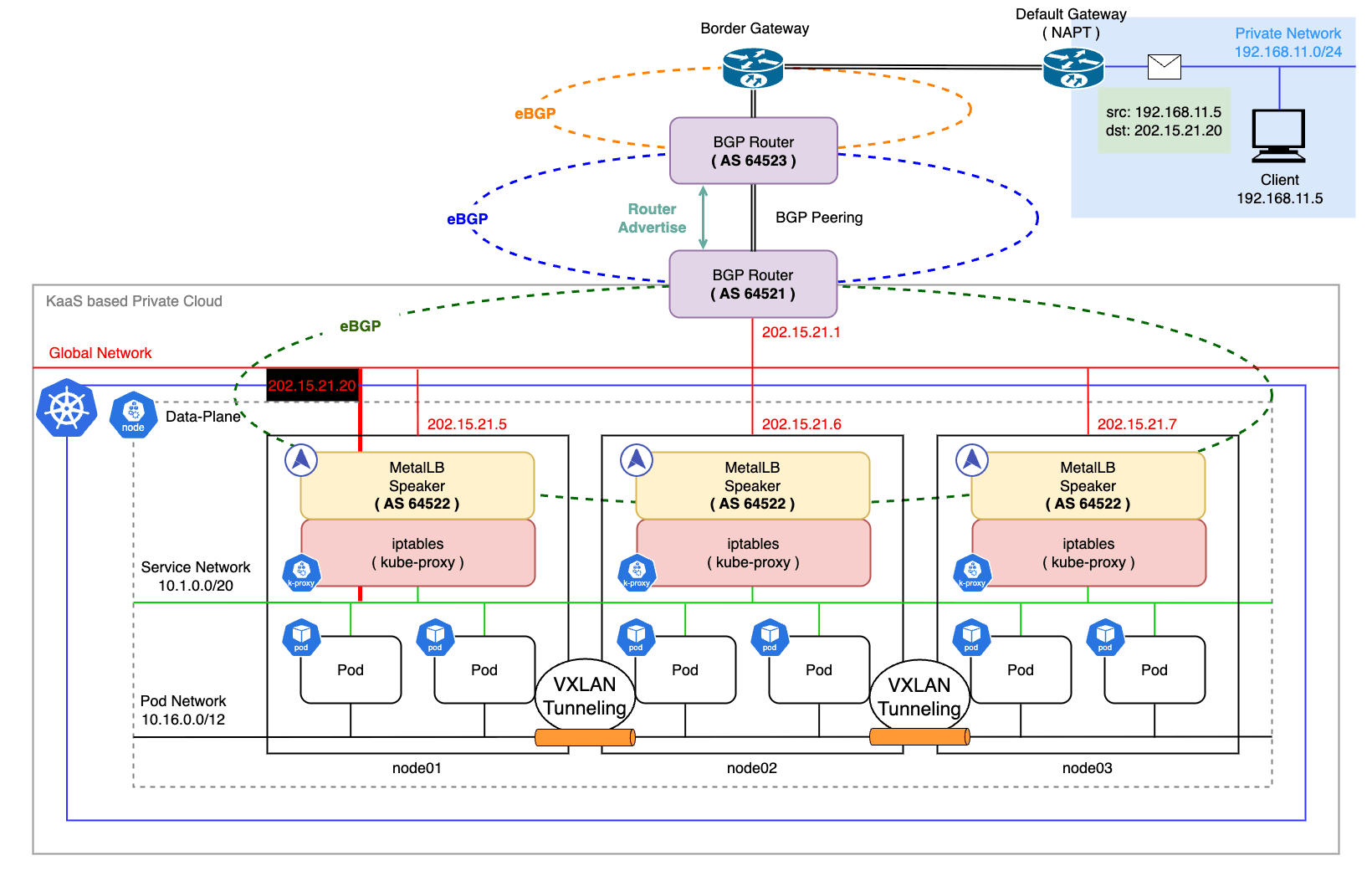
実際の運用環境
検証環境ではノードとクライアントの両方にスタティックルートを追加して BGP ルータを経由するように指示していますが、実際の運用環境では BGP ピアリングを組んだ近隣ルータ間で経路情報を交換します。
本番環境での理想的な構成は、以下のようになります。
Tips
VyOS コマンドライン
用語説明
- ソフト再構成(soft reconfiguration)
- BGP ピアから受信したルート情報を変更を加えずに再評価するための機能
- 通常、BGP では受信したルート情報をルーティングテーブルに保持してルートの変更が発生した場合にのみ再評価する
- ソフト再構成を有効にすると受信したルート情報を変更なしに再評価する
- 指定した BGP ピアで受信ルート情報を再評価するための仕組みを有効にすると、ルート情報の変更をリアルタイムに反映できる
- ネットワークトラブルシューティングや BGP ルート情報の監視等に役立つ
- ルート更新の保存にはメモリが使用される
- 複数の近隣ルータに対してソフト再構成インバウンドを有効にするとメモリ使用量が増大する可能性がある
- BGP ピアから受信したルート情報を変更を加えずに再評価するための機能
- 自律システム(AS:Autonomous System)
- インターネットは多くのネットワークやルーターで構成されており、それぞれが管理や運用を行う独立したネットワーク区域を持っている
- これらの独立したネットワーク区域を AS と呼ぶ
- 一般的に、AS 内では特定の統一されたポリシーや経路選択アルゴリズムが適用され、AS 間では BGP ルーティングポリシが適用される
- ルーティングの判断指標
- AS パス:AS Path Length
- 送信元 AS から宛先 AS までの経路を示すリスト
- このリスト(AS パス)にはデータが通過した AS の番号が含まれており、通常はカンマで区切られて表示される
- AS パスは経路選択プロセスにおいて異なる経路間の優先度を判断する際に使用される
- 一般的に、最もパス長が 最も短い 通信経路が優先される
- ローカルプレフィックス:Local Preference
- BGP 経路選択において使用される優先度を表す値
- 一般的に、最もローカルプレフィックス長が 最も高い 通信経路が優先される
- オリジンコード:Origin Code
i - IGPやe - EGP等の BGP ルータに流入したパケットのオリジン経路を示すコード- BGP 経路のオリジンコードによって、経路の起源がどこから来たかが示される
- 一般的に、IGP よりも EGP が優先され、EGP よりも不完全コード
(? - incomplete)が優先される
- メトリック値(Metric Value)
- 通信経路の選択や優先順位付けに使用される値
- 最適な経路を選択するための指標として使用され、BGP の柔軟性と適応性を高める
- 一般的に、メトリック値が 最も小さい 通信経路が優先される
- AS パス:AS Path Length
まとめ
今回のブログでは、MetalLB の BGP モードを利用して SNAT を回避しつつ、クラスタワイドな負荷分散を実現する構成について紹介しました。
Kubernetes の仕組み上、負荷分散時の SNAT は回避できず、通常であれば Service の External Traffic Policy を Local にすることでこの問題を解決します。
しかし、MetalLB の L2 モードでは一つのノードにトラフィックが集中することで単一障害点になるため、可用性や冗長性の観点で推奨されません。
これに対し、BGP モードではクラスタ前段のルータがトラフィックを ECMP で各ノードに振り分けるため、クラスタワイドな負荷分散が可能です。
このため、BGP モードでは External Traffic Policy を Local に設定しても単一障害点を抱えることなく、スケーラブルなクラスタ運用が実現できます。
BGP モードは L2 モードに比べて構成自体が複雑になりますが、特に大規模なクラスタや高可用性を求める環境、送信元 IP アドレスを保持したいといった特定のケースにも柔軟に対応することが可能です。