Raspberry Pi で構築する Bare-Metal Kubernetes - 構築編
はじめに
このブログは『RaspberryPi で構築する Bare-Metal Kubernetes』の構築編です。 準備編では、機器類の準備、セットアップ、各種 OSS の選定と全体設計について紹介しました。
構築編では、セットアップした Raspberry Pi に Kubernetes をインストールして Control-Plane 1 台、Data-Plane 3 台のクラスタを構築し、アプリケーションをデプロイして公開してみます。 本記事では MetalLB の仕組みについても簡単に紹介します。
前回のブログは こちら から読めます。
全体の流れ
以下の流れで作業します。
【準備編】準備・設計
- 機器類の準備: Raspberry Pi 等の必要機器を準備します。
- 技術選定:主に CRI / CNI / LB を選定します。
- ネットワーク設計:ネットワーク構成と IP アドレスレンジを決定します。
- Raspberry Pi の初期設定:OS のインストールとホストマシンの基礎設定をします。
【構築編】クラスタ構築 ⭐️ 本ブログ ⭐️
- Kubernetes のインストール:依存パッケージの追加とカーネルパラメータを設定します。
- Kubernetes の初期設定:Control-Plane / Data-Plane を構築します。
- アプリケーションのデプロイ:アプリケーションを追加して MetaLB で公開します。
- 【番外編】MetalLB の仕組み:MetalLB の仕組みについて紹介します。
【エコシステム編】エコシステム整備
- モニタリング基盤の整備:クラスタメトリクスを収集して監視基盤を構築します。
- GitOps の整備:GitHub とベアメタル Kubernetes を接続します。
1. Kubernetes のインストール
Raspberry Pi の基本的な設定ができたら Kubernetes をインストールしていきます。

使用するバージョンは以下の通りです。
| ソフトウェア | バージョン |
|---|---|
| Kubernetes(kubeadm) | v1.31.5 |
| KVS(etcd) | v3.5.15 |
| CRI(containerd) | v1.7.25 |
| CNI(flannel) | v0.26.3 |
ここから先は こちら のコードを参考に説明します。
パッケージ追加
はじめに依存パッケージをインストールします。
kubelet / kubectl / kubeadm のインストール
次に Kubernetes v1.31.5 をインストールします。 主に kubelet / kubectl / kubeadm の 3 つのコンポーネントを追加します。参考
インストールが終わったら確認します。
スワップの無効化
Kubernetes は物理メモリをベースにスケジューリングを行うため、スワップが有効になっているとパフォーマンスの低下や OOM 対応の不整合を引き起こす可能性があります。
Control-Plane(kube-apiserver, kube-scheduler, kube-controller-manager, etcd)は Data-Plane(kubelet)のリアルタイム性やリソースの予測可能性を前提に Pod をスケジュールします。 kubelet はホストシステムと Pod が要求するリソースを評価する必要がありますが、スワップが有効になっていると、現在の状態を正確に把握することが困難になります。
そのため、以下のコマンドでスワップを無効化しておきます。
カーネルパラメータの変更
Linux カーネルの overlay モジュールと br_netfilter モジュールを有効化します。参考
- overlay
overlay は、OverlayFS(Overlay Filesystem)を提供するカーネルモジュールです。 Kubernetes では、コンテナランタイム(containerd)がコンテナイメージを効率的に管理するために利用されます。 特に、レイヤ構造で管理されるコンテナイメージのファイルシステムを実現するために必要となります。
- br_netfilter
br_netfilter は、ネットワークブリッジを介してパケットをフィルタリングするためのカーネルモジュールです。 Kubernetes では、Pod 間通信やネットワークポリシの実装において適切にパケットをルーティングまたはフィルタリングするために利用されます。
次に、ブリッジインターフェースを通過する IP トラフィックを iptables で処理できるように設定します。 クラスタネットワークでは、常にブリッジインターフェースを経由して通信するため、トラフィックが iptables に渡らなければ、ネットワークポリシやルーティングの適用、Service のロードバランシングが正しく動作しません。
また、カーネルのトラフィックルーティングを許可することで、ノード間または Pod 間でパケットを転送することができます。 例えば、あるノード内の Pod から他のノード内の Pod への通信や、ノードの外部ネットワークへのルーティングが利用されます。 この設定が無効(0)となっている場合、カーネルは受け取ったパケットを転送しないため、通信が失敗します。
※ 公式ドキュメント に沿って設定していますが、今回 IPv6 は使用しません。
Cgroup の変更
Linux では Cgroup(Control Groups) と呼ばれるカーネルの機能によってプロセスに割り当てられるリソースを制限・管理しています。
Kubernetes では、Pod の CPU やメモリの Request / Limit によるリソース管理を強制します。 kubelet と CRI(containerd)は cgroup をインターフェースとして接続することで、ワークロードへのリソース割り当てを Kubernetes で制御できるようになります。
次のコマンドで containerd の cgroup ドライバを systemd に変更することで、Kubernetes と CRI の互換性を確保します。 Kubernetes はネイティブに systemd を使用するため、cgroup ドライバを統一しておくことでプロセスやリソース管理の一貫性を保ちます。
次に cgroup の設定を永続化します。 Kubernetes v1.25 以降および Linux Kernel v5.8 以降(Debian12)では、cgroup v2 を利用することができます。参考
詳細は省きますが、cgroup v2 は Linux API の次世代バージョンで、従来の cgroup と比べてリソース管理機能を強化した統合制御システムが提供されています。
cgroup v2 は、cgroup v1(従来)に比べて次のような改善が施されています。
- よりシンプルな設計(個別の Cgroup 階層ではなく 1 つの統一階層に基づく)
- マルチリソースの制限や制御を組み合わせた強力な機能
- 従来の cgroup v1 よりも高いパフォーマンスと柔軟性
一部の Kubernetes では、リソース管理と分離を強化するために cgroup v2 のみを使用します。 例えば、メモリ QoS を改善するための Memory QoS 機能は cgroup v2 でのみサポートされています。
この作業を 4 台分行います。
2. Kubernetes の初期設定
Raspberry Pi に Kubernetes がインストールできたら kubeadm でクラスタを構築していきます。
kubeadm は Kubernetes クラスタを作成する方法として kubeadm init と kubeadm join というコマンドを提供します。
Control-Plane(master)を init して、Data-Plane(node01, node02, node03)を join させます。
Control-Plane のデプロイ
kubeadm init では主に次のプロセスを実行します。
- init 前のチェック(Preflight checks)
- kubelet 起動
- 各種証明書の作成
- Control-Plane 用の構成ファイルを作成(kubeconfig, manifest)
- etcd 用の構成ファイル作成(manifest)
- Control-Plane の起動を待機
- kubeadm, kubelet のコンフィグをアップロード
- Control-Plane をラベリング
- TLS Bootstrap
- Addon のインストール(CoreDNS, kube-proxy)
Control-Plane の構築が終わると、次のステップの実行コマンドが提示されるので順次実行します。
Control-Plane のワークロードは以下のコマンドで確認できます。
※ コマンドが失敗する、もしくはコンテナが起動しないといった場合、前述の設定が正しくない可能性があります。
次に、こちら のマニフェストで flannel をデプロイして CNI を追加します。
今回は Kustomize + Helm を用いますが、直接 マニフェスト を適用することも可能です。
これにより、Data-Plane が Control-Plane と疎通できるようになります。
ノードの状態を確認して、master のステータスが Ready となっていればデプロイ完了です。
Data-Plane のデプロイ
次にクラスタに Data-Plane を追加していきます。
先ほど、kubeadm init した際に join コマンドが提示されていますが、以下のコマンドでも確認できます。
ノードをクラスタに追加します。
node01, node02, node03 で実行した後、再度クラスタのステータスを確認します。
全てのコンポーネントのステータスが Ready となっていればクラスタの構築は完了です。
クラスタ情報の更新
デフォルトだと kubernetes-admin@kubernetes というクラスタ名が付与されているため、kubeadm-orenge-cloud-playground としておきます。
別のマシンから接続
構築したクラスタに別の PC から接続する方法について紹介します。
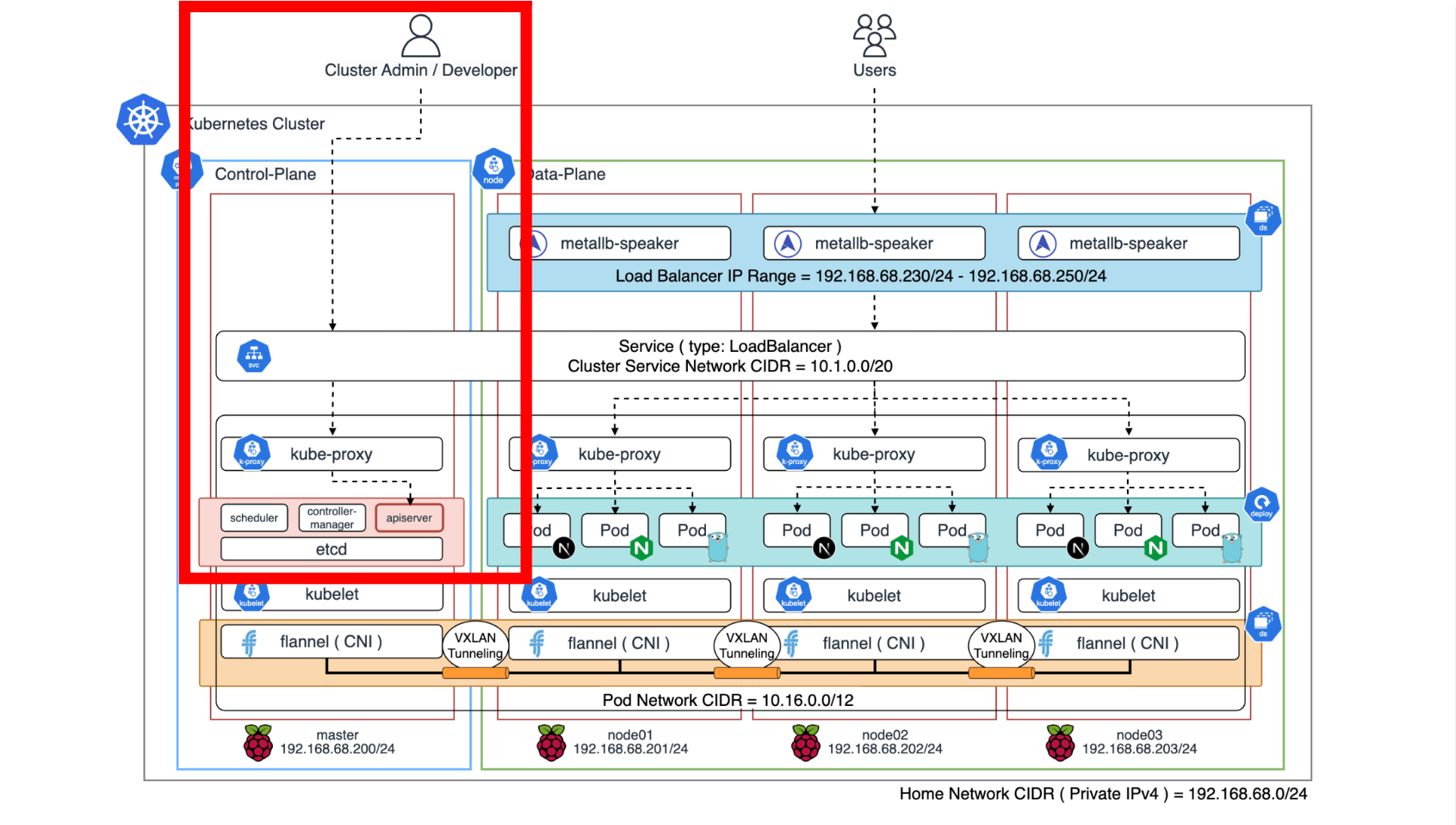
基本的に Control-Plane に API リクエストを送信することでクラスタに対してマニフェストを適用します。 その際に認証情報を用いますが、この情報を別の PC に渡しておくことで、master(RaspberryPi)以外の別のホストからクラスタを制御できます。
認証情報は以下のコマンドで確認できます。
構成情報を管理用 PC(macOS)に登録します。
macOS の場合は ~/.kube/config です。


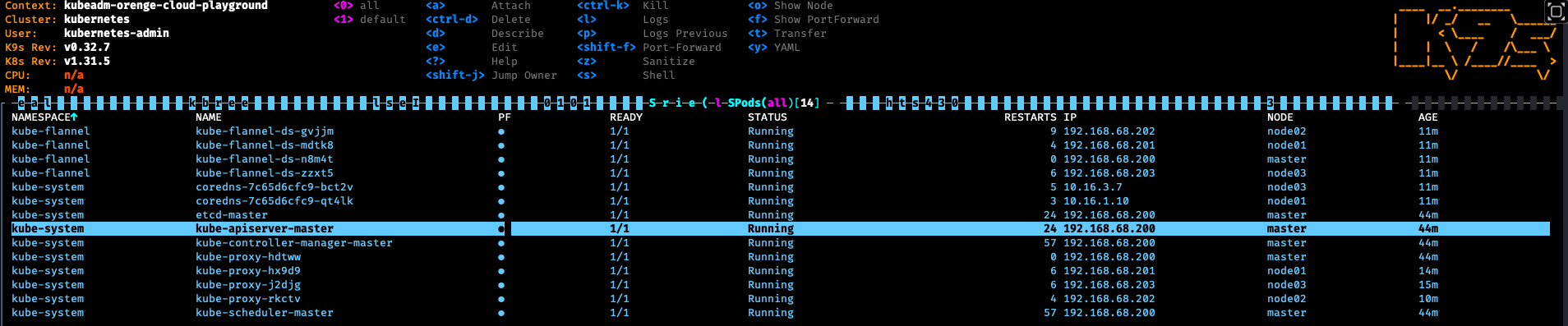
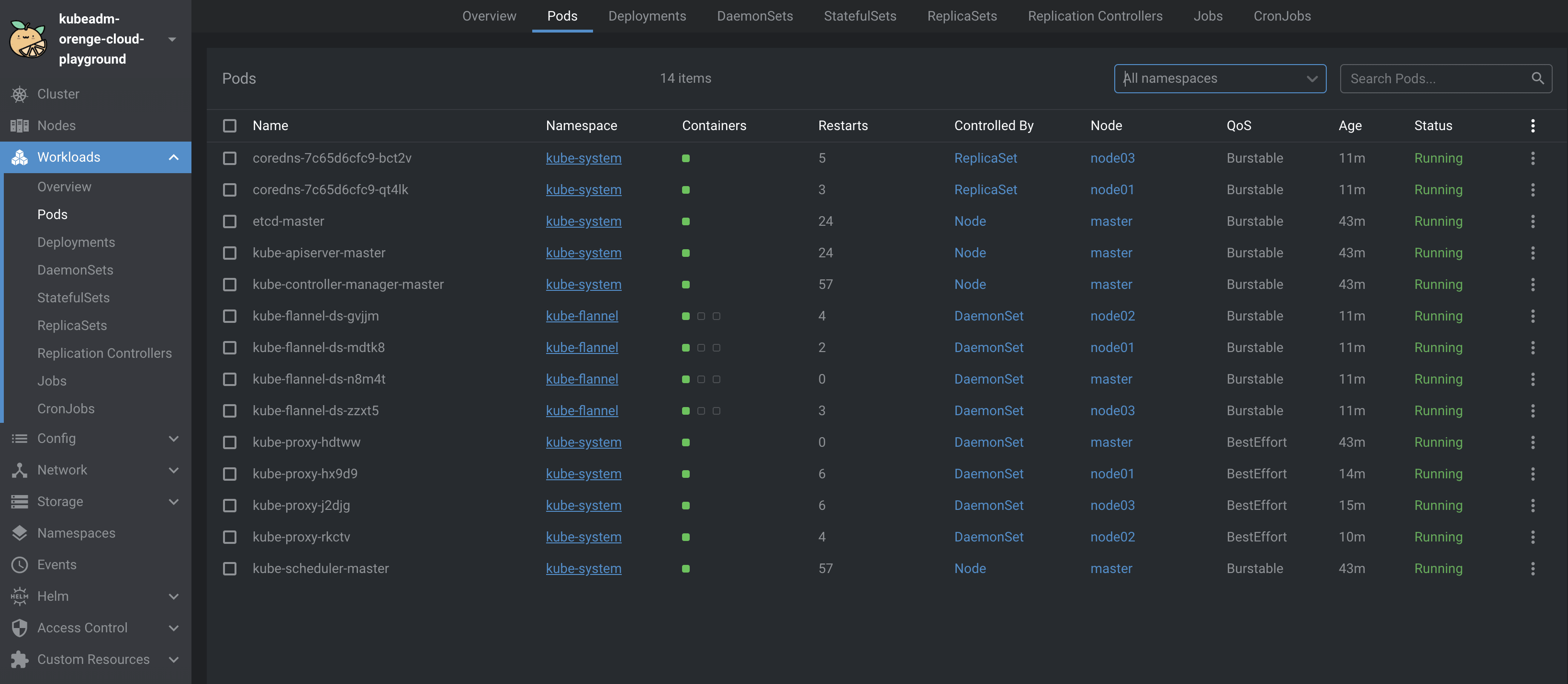
接続できたら Kubernetes クラスタの構築は完了です。
※ 注意
認証情報を不用意に第三者に渡してしまうと、クラスタとネットワーク疎通が取れる限り自由にアクセスできてしまいます。 RBAC で制御する等、セキュリティ面には注意してください。
Tips:トラブルシューティング
今回は直接 kubeadm コマンドを叩きましたが、詳細な設定項目を記述したマニフェストを用意して kubeadm init することもできます。
構成情報は Control-Plane(master)の /var/lib/kubelet/config.yaml に格納されます。
3. アプリケーションのデプロイ
デプロイと公開
クラスタの構築が完了したので、実際にアプリケーションをデプロイしてみます。 今回は手取り早くデプロイできる Nginx を追加してみます。
上記マニフェストを適用します。
ポートフォワードで接続してみます。
localhost:8080 にアクセスして Nginx の Welcome ページが表示されたらデプロイ完了です。
MetalLB の追加
実際にアプリケーションを運用する際は、ポートフォワードでアクセスすることはありません。 そこで、MetalLB を追加し、L4LB でサービスを公開することで、ローカルネットワークアドレス(Private IP)で接続することにします。
こちら のマニフェストを適用して MetalLB をデプロイします。
MetalLB がデプロイできたら、先ほどの Nginx マニフェストのサービスを以下のように変更します。
ポイントは type を LoadBalancer にしているところです。
loadBalancerIP を指定することで、クラスタが接続しているルータから DHCP でアドレスを払い出します。
IPAddressPool カスタムリソースで 192.168.68.230 - 192.168.68.250 を静的 IP として押さえています。
この IP レンジの中から割り当てるアドレスを選択します。
再度マニフェストを適用します。
デプロイしたら、今度は LAN IP で接続できることを確認します。
192.168.68.0/24 ネットワーク内の他の PC から接続してみます。
Nginx が 200 番を返していれば MetalLB でサービスを公開することができています。
実際に WEB ブラウザからもアクセスできます。

4. 【番外編】MetalLB の仕組み
今回使用した MetalLB の仕組みについて覗いてみたいと思います。
ベアメタル環境のロードバランサ
EKS / GKE 等のマネージド Kubernetes で type: LoadBalancer を使った場合は自動的に IP アドレスが払い出されますが、MetalLB の場合はあらかじめユーザが指定した IP アドレスプール(192.168.68.230 - 192.168.68.250)からの払い出しになります。
そのため、MetalLB を利用したネットワークは、DHCP による LAN の IP 払い出しが利用シーンとして想定されており、クラウドのロードバランサのようにグローバル IP が割り当てられることはありません。
外部と接続させたい場合は MetalLB で払い出したプライベート IP アドレスを NAT する仕組みを別で準備する必要があります。
MetalLB のアーキテクチャ
MetalLB をデプロイすると、Speaker と Controller と呼ばれる Pod がノード(Data-Plane)で起動します。
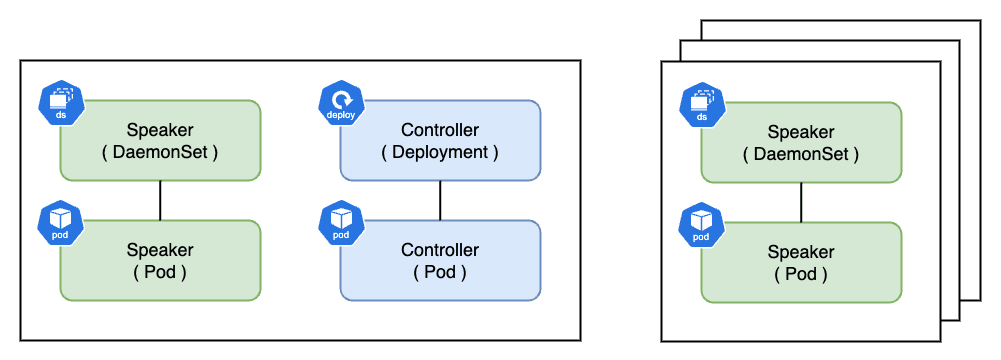
Speaker は DaemonSet で管理されており、すべてのノードで最低 1 Pod 起動し、ノードの IP アドレスを持ちます。 通常、Pod に割り当てられる Cluster IP はクラスタ内でのみ有効であり、クラスタ外のリソースから認識することができません。
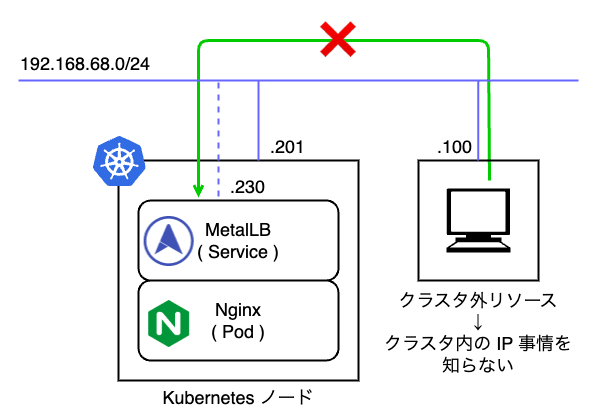
そこで、MetalLB Speaker は ARP(Address Resolution Protocol)、NDP(Neighbor Discovery Protocol)BGP(Border Gateway Protocol)のいずれかを使用してサービスの通信到達性を担保します。
- ARP:IPv4 向け L2 プロトコル
- NDP:IPv6 向け L2 プロトコル(NDP の実体は ICMPv6 なので実際は L3 プロトコルに該当)
- BGP:AS(Autonomous System)間通信向け L3 プロトコル
- より大規模な負荷分散を実現する上で BGP ルータとクラスタ間で経路広報やピアリングを行う際に利用
MetalLB ではこれらのプロトコルを利用して L2 モードと BGP モードの 2 種類の設定が可能です。 今回は IPv4 を使用しているので L2 モード、ARP によってパケットの到達性を保証しています。
一方の Controller は Deployment で管理されており、MetalLB で利用する IP アドレスの管理や払い出しを Kubernetes クラスタを跨って行う制御機能を持ちます。 Controller は Data-Plane のいずれかのノードで 1 Pod 起動し、Cluster IP が割り当てられます。
MetalLB L2 モード
L2 モードの場合は各ノードがサービスを提供する責任を持ちます。 ネットワーク的な観点では以下の図のようにサービスの数だけ NIC に IP アドレスが紐付いているように見えます。 ただし、実際には IP アドレスは UP していないため、ifconfig 等のコマンドを叩いても確認できません。
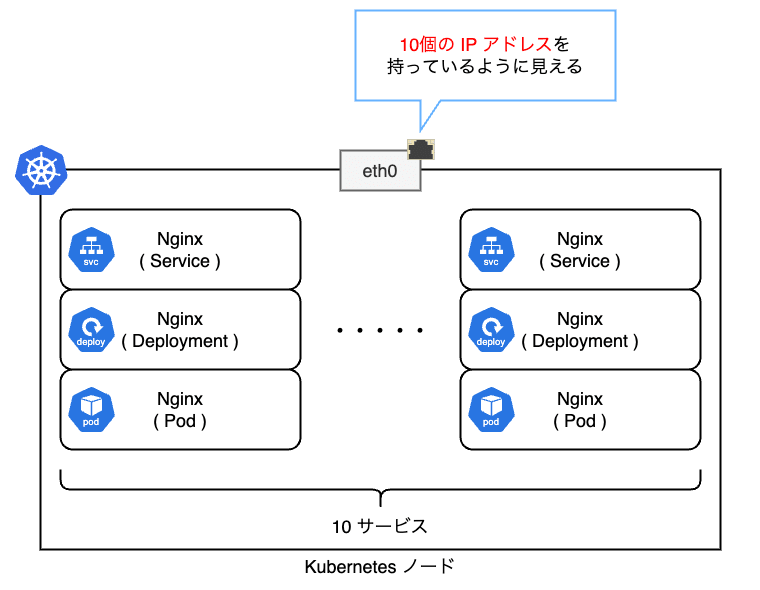
ARP の場合は接続元からの ARP リクエストに対して、接続先ノードの MetalLB Speaker が 192.168.68.201 はノードの MAC アドレスであることを ARP リプライで応答します。
つまり、サービスに割り当てた IP アドレスは、あるノードの MAC アドレスに解決されることになります。 その結果、L2 モードでは払い出された IP に対する全ての通信は 1 台のノードに集約されます。 その後、Data-Plane の kube-proxy によって設定された iptables のルールに従ってトラフィックが各 Pod に分散される仕組みとなっています。
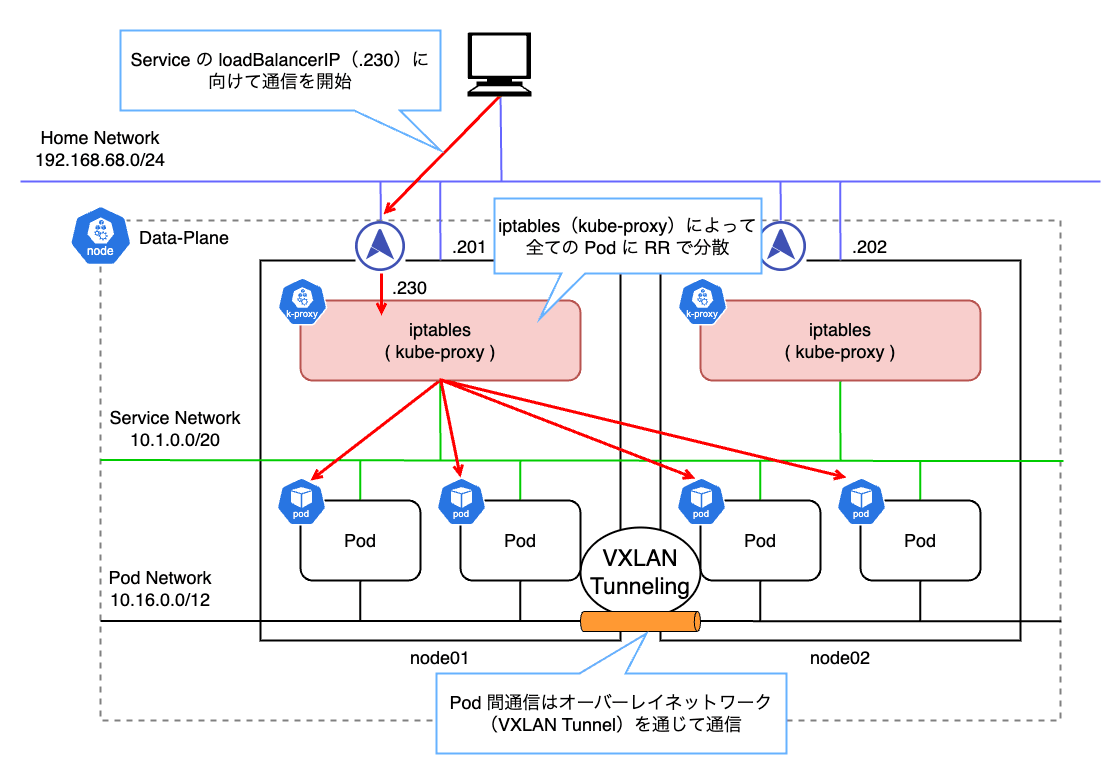
今回の例で確認してみます。 192.168.68.230 を割り当てた Nginx にアクセスした後、ARP テーブルを確認します。
192.168.68.230 という IP アドレスに dc:a6:32:bf:8b:77 という MAC アドレスがマッピングされていることが分かります。
つまり、LAN 内ではこの MAC アドレスに向けて L2 通信をしているということです。
ここで、node01(RaspberryPi)の eth0 I/F の MAC アドレスを確認します。
すると、dc:a6:32:bf:8b:77 が eth0 I/F の MAC アドレスであることが分かります。
つまり、L2 モードでは、例え Pod が複数のノードに分散していたとしても、全てのリクエストは一旦単一のノードに集約されることになります。
L2 モードではロードバランサと言いつつも、実際はサービスの IP を持ったノードがダウンした場合に、別のノードに振り分けるフェールオーバに近い形で冗長化しています。
パフォーマンスの点で注意すべきは、実際のロードバランサは特定のノード内で kube-proxy(iptables)によって行われるということです。 iptables は Chain Rule が増えると性能が著しく劣化します。 これは iptables がすべてのルールを順番に評価しようとするためです。 つまり、ルール数が 個の時、計算量は となります。
回避策としては、IPVS(IP Virtual Server) と呼ばれる別のエンジンを利用することです。 こちらはルールが増加した場合でも計算量は となります。参考
しかし、IPVS においてもまだまだ不具合があるようなので、Production で利用するのはあまりお勧めできません。
MetalLB might work with IPVS mode in kube-proxy, in Kubernetes 1.13 or later. However, it is not explicitly tested yet, so it’s at your own risk. See our tracking bug for details.
L2 モードでの Speaker は払い出された IP をハンドリングするリーダーが用意されます。 以下の図では合計で 3 つの IP が 2 つのノードに払い出されており、各ノードの Speaker がそれぞれのリーダーとなっています。
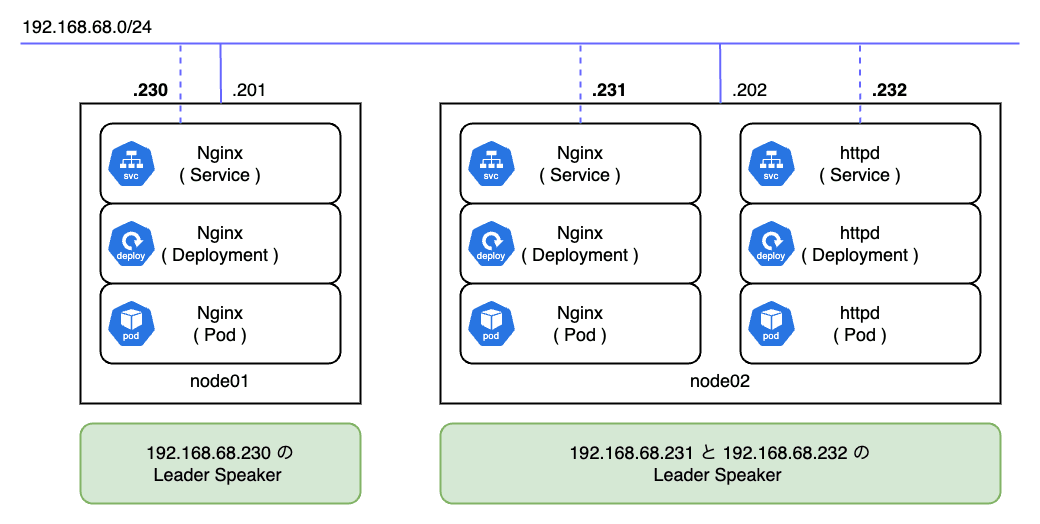
今回は Nginx Pod のレプリカ数が 1 で、node02 に配置されていることが分かります。
つまり、リーダーノードは Pod の配置状況を考慮して選出されるわけではありません。
MetalLB は各ノードのキャパシティ、優先度、および現在の負荷状況を常に監視し、サービスの IP をどのノードがアクティブに保持するかを決定します。 リーダーノードのエレクション責務は MetalLB の Controller Pod が担っています。
L2 モードのフェールオーバ
L2 モードでは何らかの理由でリーダーノード(対象の IP が存在するノード)がダウンした場合に自動でフェールオーバが行われます。 割り当てられた IP アドレスの解放は 10 秒程度 掛かり、その後別のノードがリーダーとなります。
ただし、ノードのダウンは Kubernetes 自体が検知するため、node-monitor-grace-period で設定された時間(デフォルトでは 40 秒)が確定で掛かります。
さらに到達不能になったノード上で稼働している Pod のタイムアウトはデフォルトで 5 分程度です。
結果、フェールオーバによるノードの切り替えは 5 分超 掛かる ため可用性の観点で注意が必要です。
MetalLB はフェールオーバ時に GARP(Gratuitous ARP) によって通信元に IP アドレスと MAC アドレスの紐付けが変更されたことを通知します。 ほとんどのシステムでは GARP を正しく扱うことができるため、キャッシュを更新することでフェールオーバは数秒で終わります。
一方で、従来機器の中にはキャッシュの更新が遅れるバグのあるシステムも存在するようです。 近年の Linux / macOS / Windows では支障ありませんが、一部の古い OS では問題になることがあります。
まとめ

今回のブログでは、RaspberryPi に Kuberetes をインストールしてクラスタを構築する方法について紹介しました。 また、構築したクラスタに Nginx を導入し、MetalLB で LAN IP を払い出してサービスを公開してみました。
Kubernetes の構築に際してはカーネルパラメータを適切に設定する必要があり、Linux に関する基本的な知識が必要となります。
kubeadm init を実行した際に、Control-Plane の構築に失敗する場合は、前提の設定が正しくない可能性があります。
特に cgroup v2 を利用する場合は、従来と大きく異なる点があるので、各種パラメータが適切であるかを確認してください。
また、本記事では MetalLB の仕組みについても紹介しました。 現在では、ベアメタルで Kubernetes をホスティングする際は、L4 のロードバランサとして MetalLB を選定することが多いのではないでしょうか。
MetalLB は L2 モードと BGP モードの 2 つが利用できます。
L2 モードは主に、ARP や NDP 等のアドレス解決プロトコルを利用することで、IP アドレスの問い合わせに対してリーダーノードの MAC アドレスを応答します。 そのため、Pod の負荷を分散できる一方で、単一ノードにトラフィックが集中することによるボトルネックや、iptables(kube-proxy)による Chain Rule の評価やルーティングのオーバーヘッドが少なからず生じます。
また、BGP モードの場合、クラスタと BGP ルータをピアリングして経路広報することで、ノードレベルで負荷分散することができますが、ネットワーク規模が非常に大きくなります。
MetalLB にはまだまだ課題がありますが、ベアメタルで Kubernetes を運用する際には非常に強力なツールとなっています。
次回のブログでは、より本番環境に近い Kubernetes の運用を目指すべく、いくつかエコシステムを整備したいと思います。