Pod の Termination プロセスを整理する
はじめに
Web アプリケーションの運用において、デプロイやメンテナンスに伴うプロセスの再起動は避けて通れないイベントです。 この際、実行中のリクエストを強制的に遮断することなく、安全に処理を完了させてから停止する仕組みを Graceful Shutdown と言います。
特に Kubernetes 環境では、デプロイやオートスケーリングによって Pod の破棄と再作成が頻繁に行われます。 そのため、単にアプリケーションコードで終了処理を書くだけでは不十分です。 Kubernetes がどのように Pod をネットワークから切り離し、コンテナを停止させるのかという Termination プロセスについて正しく理解した上で、アプリケーションを安全に停止させる設計が求められます。
今回のブログでは Kubernetes がどのように Pod を停止・削除するのか、その内部プロセスと挙動について整理してみたいと思います。
※ 本ブログは Kubernetes 1.31 を想定して書きますが、バージョンによってデフォルト値や挙動が変更される可能性があるため、併せて公式ドキュメントもご確認ください。
Pod の終了要因
Graceful Shutdown を正しく実装するためには、Kubernetes が Pod を停止・削除させる仕組みについて理解しておく必要があります。 Pod の終了処理は、例えば以下のような要因によって発生します。
- ユーザ操作
kubectl delete podkubectl scale deploymentkubectl rollout restart deployment
- スケール関連のイベント
- HPA によるスケールイン
- VPA によるリソース変更時の再起動
- ノード関連のイベント
- Cluster Autoscaler によるノード削除
- ノードドレイン(メンテナンス時の Pod Eviction)
- スポットインスタンス(Preemptible VM)の回収
- リソース・状態管理のイベント
- Liveness Probe 失敗による再起動
- Eviction(ノードのリソース圧迫による Pod の退避)
これらのイベントが発生すると、Pod のステータスは Running から Terminating に遷移し、終了プロセスがトリガされます。
SIGTERM と SIGKILL
Kubernetes はコンテナを停止させる際、Linux の標準的なプロセス間通信である シグナル を使用します。 Pod の終了処理フローの説明に入る前に、まず主要な 2 つのシグナルについて整理しておきます。
SIGTERM(Signal 15)
SIGTERM は Termination Signal(終了シグナル) を意味し、プロセスに対して正常な終了を要求する役割を持ちます。 プロセスはこのシグナルを受信した後、即座に停止するのではなく、任意の終了処理(Graceful Shutdown)を実行する猶予が与えられます。
Kubernetes が Pod を停止する際、まず最初に送信するのがこの SIGTERM です。 アプリケーションは、このシグナルをトラップすることで、現在処理中のリクエストを完了させたり、DB 接続を閉じたりといったリソースの解放処理を開始します。
SIGKILL(Signal 9)
SIGKILL は Kill Signal(強制終了シグナル) を意味し、プロセスを強制的に停止させる役割を持ちます。 基本的に、アプリケーションはこのシグナルをトラップすることも無視することもできません。 シグナルが送られた瞬間、カーネルによってプロセスは即座に破棄され、メモリ上のデータも解放処理を経ずに消失します。
Kubernetes では、SIGTERM 送信後、terminationGracePeriodSeconds(後述)で定義された猶予期間が経過してもプロセスが終了しない場合に、最終手段として SIGKILL を送信します。
つまり、Graceful Shutdown とはいきなり SIGKILL で強制終了されるのを防ぎ、SIGTERM を受け取って自発的に安全に終了する ことを指します。
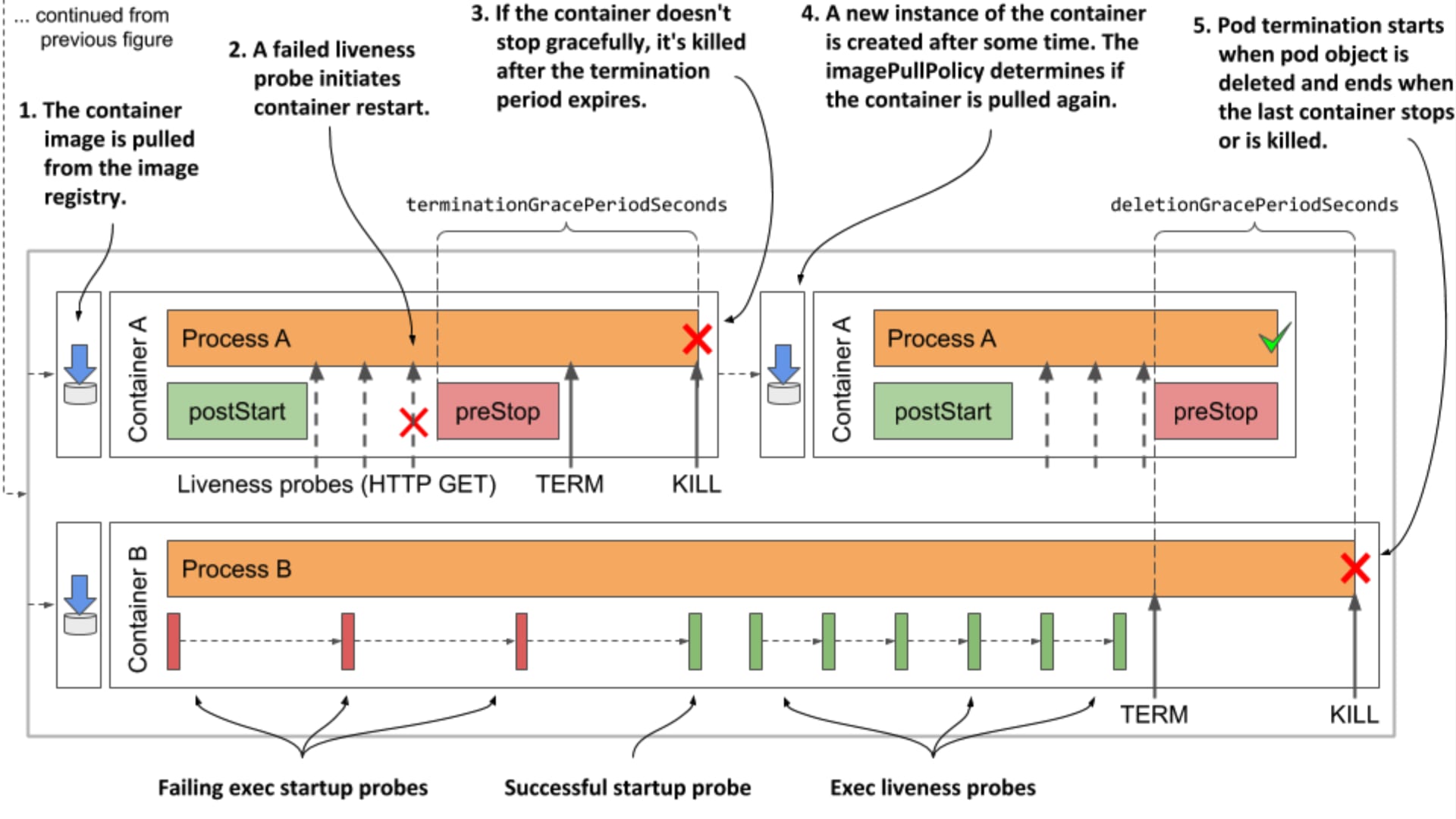
Pod が終了する過程
前述の操作によって Pod の終了イベントが発生すると、Kubernetes は以下のようなフローに従って Pod を削除します。

ここで、2 の 3 つの処理は、それぞれを担当するコンポーネントが独立して実行します。 従って、「サービスアウトしてからシャットダウンする」といったような互いに依存関係を持った制御が行われないことに注意する必要があります。
1. 終了予定時刻を Pod に設定

ユーザ操作または Kubernetes 自体によって Pod の停止・削除イベントが発生すると、Kubernetes の API Server(以後、kube-apiserver)は対象の Pod に対して、削除処理のためのメタデータを設定します。
具体的には、.spec.terminationGracePeriodSeconds(またはコマンドで指定された値)を元に .metadata.deletionGracePeriodSeconds を確定させ、それに基づいて計算された削除期限を .metadata.deletionTimestamp に記録します。
terminationGracePeriodSeconds と deletionGracePeriodSeconds の違いは「誰が設定する値か」と「いつ使われる値か」という点にあります。
-
.spec.terminationGracePeriodSeconds-
ユーザが定義する理想的な猶予時間(設計値)
-
Pod マニフェストの
.specに記述し、「このアプリケーションは終了に最大 30 秒要する」と宣言するもの
-
-
.metadata.deletionGracePeriodSeconds- kube-apiserver が決定した実際の削除タイマ(実行値)
- Pod の削除処理が始まった瞬間に
.metadataに書き込まれる - 通常は
terminationGracePeriodSecondsの値がそのままコピーされるが、kubectl delete pod --grace-period=10のようにコマンド実行時にオーバーライドされた場合は、その値が優先してセットされる
| terminationGracePeriodSeconds | deletionGracePeriodSeconds | |
|---|---|---|
| 概要 | ユーザ定義のデフォルト値 | 実際の削除時に適用される確定値 |
| 設定場所 | .spec | .metadata |
| タイミング | Pod 作成時 | Pod 削除開始時 |
| 挙動 | 基本的に不変 | コマンドでオーバーライド可能 |
kube-apiserver は、削除リクエストを受け取ると即座に Pod を消すのではなく、まず .metadata.deletionGracePeriodSeconds(デフォルトは .spec の値と同じ)で指定された猶予時間を現在時刻に加算し、その結果を「削除予定時刻」として .metadata.deletionTimestamp に記録します。
例えば、12:00:00 に kubectl delete pod を実行し、猶予期間が 30 秒だった場合、以下のようになります。
deletionGracePeriodSecondsに30がセットされるdeletionTimestampに12:00:30がセットされる
このタイムスタンプがセットされた瞬間、Pod は Terminating 状態 となります。 kubelet 等の各コンポーネントはこの時刻を監視しており、「12:00:30 までは正常に終了するための猶予を与えるが、それを過ぎたら強制的に削除(SIGKILL)する」という動作を開始します。
2-a. kubelet によるプロセスのシャットダウン

kubelet が .metadata.deletionTimestamp の設定を検知すると、Pod 内の各コンテナに対して以下の手順で停止処理を実行します。
-
preStop フックの実行(同期処理)
- マニフェストに
.spec.containers[].lifecycle.preStopが設定されている場合、まず preStop フックを実行 - このフックが完了するまで次のステップ(SIGTERM)には進まない
- ただし、全体の制限時間(
terminationGracePeriodSeconds)を超えた場合は、フックの実行途中でも強制的に中断される(SIGKILL)
- マニフェストに
-
SIGTERM の送信
- preStop が完了した(またはタイムアウトした)時点で、コンテナのメインプロセス(PID 1)に SIGTERM シグナルが送信される
- アプリケーションはこのシグナルを受け取って、Graceful Shutdown(例:新規受付の停止、処理中のリクエスト完了、リソース開放)を開始する
-
SIGKILL による強制終了
terminationGracePeriodSecondsの期限が来た時点で、プロセスがまだ動いている場合は SIGKILL が送信され、強制終了される
ここで重要なのは、terminationGracePeriodSeconds(デフォルト 30 秒)は preStop と SIGTERM の合計時間である という点です。
例えば、terminationGracePeriodSeconds: 30 の設定で preStop に 20 秒かかった場合:
| 経過時刻 | 処理内容 |
|---|---|
| 0 秒 | 停止指示。preStop 開始。 |
| 20 秒 | preStop 完了。SIGTERM 送信。 |
| 残り 10 秒 | アプリケーションが SIGTERM を受けて終了処理を行える時間は 10 秒しかない。 |
逆に、preStop が 30 秒を超えてしまった場合(例えば 40 秒かかる処理だった場合):
| 経過時刻 | 処理内容 |
|---|---|
| 0 秒 | 停止指示。preStop 開始。 |
| 30 秒 | タイムアウト発生。preStop は中断される。 |
| 30 秒 | すぐに SIGTERM が送られるが、猶予時間は既に使い切っているため、2 秒後 に SIGKILL が送られる。 (※ 猶予を使い切った場合でも、Kubernetes は最低 2 秒間の猶予を与えます。) |
このように、preStop を利用する場合は、その実行時間を考慮して terminationGracePeriodSeconds を十分に長く設定する必要があります。
2-b. Endpoints Controller と kube-proxy によるサービスアウト

deletionTimestamp が設定されると、Pod の IP アドレスを Service のルーティング対象から除外するサービスアウト処理が実行されます。
この処理は主に Endpoints Controller と kube-proxy によって行われます。
-
Endpoints Controller(Control-Plane)
- Endpoints Controller が、対象 Pod の状態変化(Terminating)を検知する
- 当該 Service に紐づく Endpoints リソースから対象 Pod のエントリを削除もしくは
ready: falseに更新する
-
kube-proxy(Data-Plane)
- 各ノード上で起動する kube-proxy は kube-apiserver 経由で Endpoints の変更を監視する
- 変更通知を受け取ると、ノード上のパケット転送ルール(iptables や IPVS)を即座に更新して対象 Pod への新規トラフィックの転送を停止する
この仕組みにより、削除中の Pod に新しいリクエストが振り分けられることを防ぎます。 ただし、Endpoints の更新から各ノードの iptables / IPVS 反映までには数ミリ秒〜数秒程度のタイムラグが発生するため、後述する Race Condition(競合状態)への対策を考慮する必要があります。
2-c. Owner リソースによる管理からの除外

Kubernetes の ReplicaSet Controller は、常に指定された数(replicas)の Pod が稼働していることを保証する責務を持っています。
ここで、deletionTimestamp が付与された Pod は終了予定とみなされ、将来的に稼働し続けるリソースとしては扱われません。
ReplicaSet Controller は 古い Pod の停止完了を待つことなく、即座に新しい Pod の作成を開始 します。 つまり、Pod の停止処理と新規作成処理は依存関係を持たず、非同期に並行して進行することになります。
具体的な動作ロジックは以下の通りです。
-
管理対象からの除外
- Pod に
deletionTimestampが設定されると、ReplicaSet Controller はその Pod を「稼働中の Pod 数(Ready Replicas)」のカウントから除外する
- Pod に
-
Pod 数の不整合と補充
カウントから除外されたことで、Controller は稼働中の Pod 数が設定値(
replicas)より 1 つ足りないことを認識する -
新規 Pod の作成
不足した 1 つ分を補うため、Controller は即座に新しい Pod の作成処理を開始する
このため、ローリングアップデートや Pod 削除の期間中は、一時的に replicas + 1 個(終了処理中の Pod + 新規起動中の Pod)の Pod がクラスタ上に共存します。
終了プロセスにおける Race Condition と回避策
Pod の終了時には「kubelet によるコンテナ停止(シャットダウン)」や「Endpoints Controller による切り離し(サービスアウト)」といった複数の処理が同時に進行します。
これらの 終了プロセスは互いに完了を待つことなく非同期に進行する ため、タイミングによっては処理間の競合状態(Race Condition)に起因した問題が発生する可能性があります。
At the same time as the kubelet is starting graceful shutdown of the Pod, the control plane evaluates whether to remove that shutting-down Pod from EndpointSlice objects, where those objects represent a Service with a configured selector.
プロセス A:コンテナの停止命令
こちらは「2-a」に該当し、kubelet が主導するプロセスです。
- preStop フックの実行 → SIGTERM の送信 → 最終的な SIGKILL
という順序でアプリケーションの停止を試みます。
重要なのは、後述する「プロセス B」の完了(トラフィックの完全な遮断)を待ってから「プロセス A」が始まるわけではない、ということです。 これらはあくまで並行して進行します。
プロセス B:ネットワークトラフィックの遮断命令
こちらは「2-b」に該当し、Endpoints Controller や kube-proxy が主導するプロセスです。
kube-apiserver からの通知を受けた各コンポーネント(例:Endpoints Controller, kube-proxy, Ingress Controller)が、それぞれのタイミングでルーティングテーブルを更新します。
preStop フックで SIGTERM を遅らせる
上記の通り「プロセス A」と「プロセス B」は並行して走るため、タイミングによっては「コンテナは既に終了処理(SIGTERM)を開始しているのに、ネットワーク経路(iptables)にはまだ古いルールが残っている」といった状態が発生し、通信エラー(502 Bad Gateway)の主原因となることがあります。
この問題を解決する方法は、アプリケーションが SIGTERM を受け取るタイミングを遅らせることです。
具体的には、preStop フックで sleep を実行し、アプリケーションを生かしたまま、ネットワーク経路が遮断されるのを待機 します。
これにより、サービスアウト処理(iptables の更新と伝播)が完了し、新規リクエストが完全に遮断されてからアプリケーションの停止プロセス(SIGTERM 受信)を開始することができます。
この例では、sleep 10(10 秒間待機)の間に、Endpoints Controller と kube-proxy がサービスアウト処理を実行し、iptables の更新が全ノードに伝播するのを待ちます。
preStop フックの待機時間の設計
サービスアウトの時間は、クラスタ規模やネットワークプラグイン(CNI)、利用している Ingress Controller や Cloud Load Balancer の仕様によって異なります。
preStop フックの待機時間は、以下の要素を考慮して環境毎に適切な値を検証する必要があります。
-
iptables / IPVS の伝播遅延
大規模なクラスタでは、Endpoints の更新が全ノードの iptables に反映されるまでに数秒〜十数秒の遅延が発生することがあります。
-
ロードバランサの登録解除遅延(Deregistration Delay)
AWS ALB 等のクラウドロードバランサを使用している場合、ターゲットグループからの登録解除が完了するまでの待機時間も考慮する必要があります。 例えば ALB のデフォルトの登録解除遅延は 300 秒ですが、これを適切に(Pod の終了時間に合わせて)短縮設定していないと、不要なエラーの原因になります。
基本的に sleep 5 〜 10 秒程度から開始し、負荷試験ツール(k6 や hey 等)を用いて、Pod 削除中に 502 エラーが発生しないかを確認しながら値を調整することが推奨されます。
terminationGracePeriodSeconds の設計
preStop を導入する場合、全体の猶予時間(terminationGracePeriodSeconds)も調整が必要です。
具体的には、terminationGracePeriodSeconds の値が preStop の sleep 時間にアプリケーション自体の Graceful Shutdown の最大所要時間を加算した値になるように設定します。
例えば preStop: 10s + アプリケーションの終了処理: 20s = 30s の場合、デフォルトの 30 秒ではタイムアウトのリスクが高いため、安全マージンを取って 45秒 や 60秒 に設定します。
その他の考慮事項
Kubernetes 環境でアプリケーションを終了させる際には、標準的なフロー以外にも注意すべき点がいくつかあります。
PID 1 の扱い
コンテナ環境におけるシグナルハンドリングにおいて、注意すべき重要な仕様として PID 1 問題 があります。
通常、Linux では systemd 等の init プロセスが PID 1 として動作しますが、Docker をはじめとするコンテナ技術は、Linux カーネルの機能である PID Namespace を利用してプロセスを隔離します。
これにより、コンテナ内部からはホスト上の他のプロセスが見えなくなり、コンテナ内で最初に起動したプロセス(ENTRYPOINT や CMD で指定されたコマンド)に、そのコンテナ固有の PID 1 が割り当てられます。
詳しくは こちらのブログ でも紹介しています。
ここで問題となるのが、Linux カーネルの PID 1 のプロセスは、明示的にシグナルハンドラを実装していない限り、デフォルトのシグナル動作が無効化されるという仕様です。 これは本来、重要な init プロセスを誤操作によるシステムクラッシュから保護するための機能ですが、コンテナ環境においては、シグナルハンドリングを実装していないアプリケーションが SIGTERM を無視してしまう原因となります。
その結果、Kubernetes から停止命令が送られても Graceful Shutdown が開始されず、最終的に SIGKILL で強制終了されるまでプロセスが残り続けてしまいます。
Shell 形式 / Exec 形式
Dockerfile で CMD や ENTRYPOINT を記述する際、以下の 2 つの書き方があります。
この違いにより、シグナルがアプリケーションに正しく伝播するかどうかが変わります。
- Shell 形式:
CMD ./app/bin/sh -c ./appとして実行される- PID 1 は
/bin/shになり、アプリケーションはその子プロセスとなる - Shell は受け取ったシグナルを子プロセスに伝搬しない実装になっていることが多いためアプリケーションに SIGTERM が届かない
- Exec 形式:
CMD ["./app"]- アプリケーションが直接 PID 1 として実行される
- アプリケーションがシグナルハンドリングを実装していれば正しく受け取ることができる
対策
-
原則 Exec 形式(
CMD ["./app"])を使用 する -
Shell Script 経由で起動する場合
exec ./appのようにexecコマンドを使ってプロセスを置換する -
もしくは tini や dumb-init 等の軽量な init プロセスを使用する
- これらはシグナルプロキシとして機能し、ゾンビプロセスの回収も行ってくれる
サイドカーコンテナの終了順序
Istio や Linkerd、Cloud SQL Auth Proxy といったサイドカーパターンを利用している場合、Pod 内には複数のコンテナが存在します。
Kubernetes 1.28 以前では、Pod 終了時に全てのコンテナへ同時に SIGTERM が送信され、停止順序も保証されませんでした。 そのため、メインのアプリケーションが終了処理中(例:ログ送信や DB 切断)であるにも関わらず、サイドカーコンテナが先に停止してしまい、通信エラーが発生するケースがあります。
この問題への対策は、利用している Kubernetes のバージョンによって異なります。
Kubernetes 1.29 以降
Kubernetes 1.29 以降では、標準機能となった SidecarContainers(Native Sidecar Support) を利用するのがベストプラクティスです。
これは initContainers 内で restartPolicy: Always を指定することで、そのコンテナをサイドカーとして定義する機能です。
この方法で定義されたサイドカーは、以下のライフサイクルが保証されます。
- 起動時:メインコンテナが起動する 前 に起動完了する
- 終了時:メインコンテナが完全に停止した 後 に停止処理が開始される(LIFO:Last In, First Out)
Kubernetes 1.28 以前
Native Sidecar Support が利用できないバージョンでは、preStop フックを利用したワークアラウンド が必要です。
サイドカーコンテナ(例:Cloud SQL Auth Proxy)の preStop フックに、メインアプリケーションのプロセス(TCP ポート等)が完全に終了するまでループで監視し続けるスクリプトを仕込みます。 これにより、メインアプリケーションが生きている間はサイドカーも強制的に待機させることができます。
まとめ
Kubernetes におけるアプリケーションの安全な停止(Graceful Shutdown)は、単に SIGTERM をキャッチして終了処理を書くだけでは完結しません。
今回のブログで紹介したように、Pod の Termination プロセスは複数のコンポーネントが連携して行われますが、それらは必ずしも同期しているわけではありません。 特に「kubelet によるコンテナ停止(シャットダウン)」と「Endpoints Controller による切り離し(サービスアウト)」が同時に進行するという Kubernetes のアーキテクチャ上の特性は、予期せぬエラーを生む大きな要因となります。
停止時のエラーを低減するためには、こうしたプラットフォーム側の挙動を正しく理解し、マニフェスト(preStop や terminationGracePeriodSeconds)とコンテナイメージ(PID 1 や Sidecar 構成)の両面から適切な設計を行う必要があります。
Pod のライフサイクルやシグナル処理の仕組みを踏まえ、次回のブログでは Go 言語の context パッケージを用いた具体的なコーディングパターンにフォーカスし、アプリケーション自身がどのように Graceful Shutdown を実装すべきかについて紹介したいと思います。