Go Context で実装する Graceful Shutdown
はじめに
こちらのブログ では Kubernetes における Pod の終了プロセスについて紹介しました。
Kubernetes では、コンテナへの停止指示とネットワークトラフィックの遮断が非同期に進行します。 Kubernetes のアーキテクチャ特有の挙動を考慮せずに実装を行うと、サービス停止時にリクエストのエラーや欠損を引き起こす原因となります。
今回のブログでは、Go 言語での停止処理において中心的な役割を担う context パッケージの内部挙動と、net/http や gRPC サーバを安全に停止させるための具体的なコード実装について紹介したいと思います。
Go Context の挙動
Go 言語における並行処理やタイムアウト制御の実装では、context パッケージを利用したキャンセル処理が標準的な手法として定着しています。
特に Graceful Shutdown のようなシステム全体の停止を扱う場面においても、context は停止シグナルの伝播手段として頻繁に利用されます。
効率的で安全な停止処理を実装するには、context 利用時に Go ランタイムの内部で何が起きているのかを理解しておくことが重要です。
Context の役割
context.Context は、API の境界やプロセス間を超えて、以下の情報を伝播させるための標準的な仕組みです。
- キャンセルシグナル:処理の中断を要求する合図
- デッドライン:処理完了までの時間制限やタイムアウトを制御
- リクエストスコープの値:分散トレーシングにおける Trace ID やユーザ認証情報の伝搬
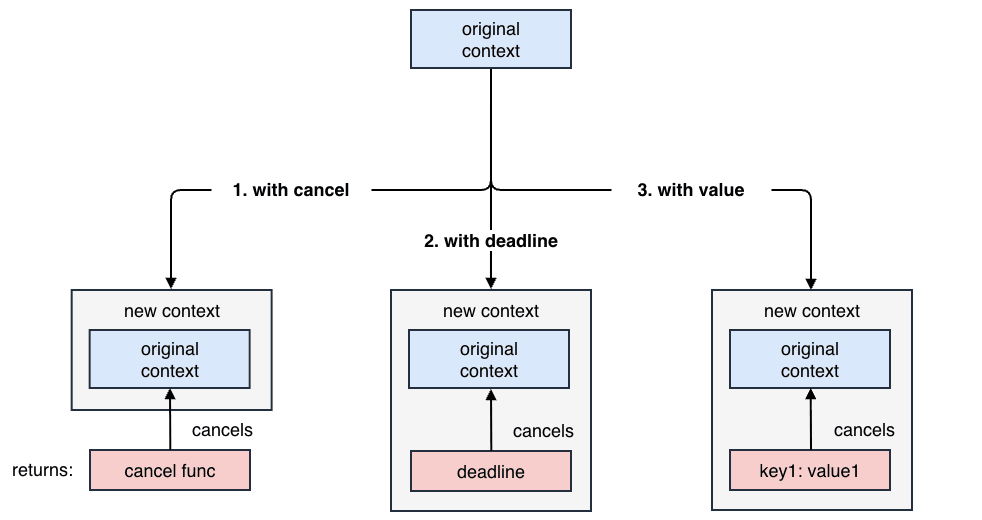
Graceful Shutdown においては、特に「1. キャンセルシグナル」と「2. デッドライン」が重要になります。
Context の親子関係とキャンセラ
Context のキャンセルとは、処理を途中でやめる合図を関連する Goroutine へ伝達することです。 Context は親子関係を持っており、親の Context がキャンセルされると、子および孫の Context も連鎖的にすべてキャンセルされます。
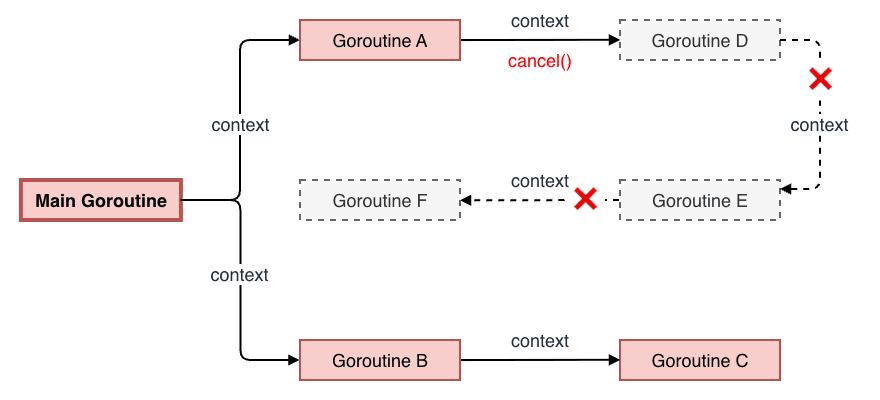
Context の伝播の仕組みにより、メイン関数でシャットダウンを開始、すなわち親 Context のキャンセルをトリガするだけで、HTTP サーバ、DB クライアント、バックグラウンドワーカーといった該当の Context を受け取っている全ての Goroutine に対して一斉に停止命令を送ることができます。
キャンセル処理の内部挙動
Context がキャンセルされた際、内部的に何が起きているのかを見てみます。 Context の挙動を理解するためには、Go ランタイムの仕組み(G / M / P)を前提知識として持っておく必要があります。
Go ランタイムの仕組みについては こちらのブログ でも紹介していますが、簡単に説明すると以下の要素が登場します。
| 記号 | 名称 | 概要 |
|---|---|---|
| G | Goroutine | Go ランタイムが管理する軽量スレッド(ユーザスレッド) |
| M | Machine | OS が管理する実際のスレッド(カーネルスレッド) |
| P | Processor | G を M 上で実行するためのリソースコンテキスト |
Go Channel
Go では Channel と呼ばれる仕組みによって Goroutine 間でデータをやり取りすることができます。 基本的に Channel は双方向通信であるため、Goroutine は同じ Channel を介してデータを送受信します。
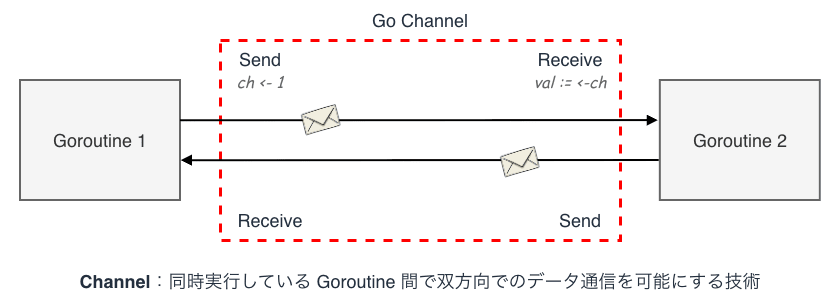
Go の Channel は Unix のパイプやソケットのようなファイルディスクリプタを持つカーネルオブジェクトとは異なり、ユーザ空間で動作する Go ランタイムによって管理されるメモリ上のデータ構造 です。
Linux カーネルの視点から見ると、Go の Channel は単なるヒープ領域に確保された hchan という構造体になります。
ここで、Channel は複数の Goroutine 間で共有されることが前提のデータ構造であり、作成された関数のスコープを超えて(エスケープして)利用されるため、スタックではなくヒープ領域に確保されます。
例えば、前述のコードのように ch := make(chan int) で Channel を作成すると、コンパイラは make 呼び出しを runtime.makechan 関数の呼び出しに変換します。
この関数内部で hchan 構造体のサイズ計算やメモリ確保(mallocgc)が行われ、初期化された構造体へのポインタが返されます。
このため、変数として扱っている ch は hchan へのポインタとなります。
- カーネルから見えるもの
- メモリのアドレス空間(データの読み書き)
- M の状態遷移(Running や Sleeping)
- futex によるスレッドの待機や再開を行うシステムコール
- カーネルから見えないもの
- Channel という概念そのもの
- G の存在
futex は Linux カーネルが提供するシステムコールの一つで、ユーザ空間での高速なロック機構を実現するために設計されています。
従来のシステムコール(例:
select,poll)は呼び出すたびに必ずカーネルモードへの切り替えコストが発生していましたが、futex は 競合が発生していない(ロックが取れる)場合はユーザ空間のメモリ操作だけで完了し、カーネルを呼び出さない という特性を持ちます。Go ランタイムは futex の仕組みを利用して Channel 操作や Goroutine のスケジューリングにおいて、実際にカーネルスレッドの停止・再開が必要になるまでカーネルへのコンテキストスイッチを回避しています。(Go の並行処理が軽量である理由の一つ)
Done Channel による通知
Context のキャンセルは、ctx.Done() メソッドが返す Channel の close によって通知されます。
net/http や database/sql といった Go の多くの標準ライブラリは、内部で Context が持つ Done() Channel を監視しており、Context がキャンセルされると即座に処理を中断してリソースを解放するように実装されています。
net/http:Shutdown 時の待機ループ
net/http パッケージの Shutdown メソッドでは、処理中のリクエストがなくなるのを待機するループの中で ctx.Done() を監視しています。
database/sql:コネクション取得時のチェック
database/sql パッケージでは、クエリを実行するためにコネクションプールから接続を取得する conn メソッドの冒頭で Context の状態を確認しています。
Go ランタイムの挙動
context のキャンセル処理は非常に軽量かつ高速に動作するように設計されており、数千・数万規模の Goroutine が同時に走る状況下でも、システム全体へ瞬時に停止命令を伝搬させることが可能になっています。
1. ユーザ空間でのフラグ操作
cancel() 関数が呼ばれた瞬間に行われるのはメモリ上のデータ書き換えのみです。
cancel() 関数が実行されると、内部で close(done) が呼ばれ、Go ランタイムの runtime.closechan 関数が実行されます。
この関数は、ヒープ上にある hchan 構造体の lock(mutex)を取得し、closed フィールドを 1 に書き換えるだけの単純なメモリ操作を行います。
この一連の処理は、カーネルの介入なしにユーザ空間のみで完結するため、システムコールのような高負荷な処理は発生せず、非常に高速に完了します。
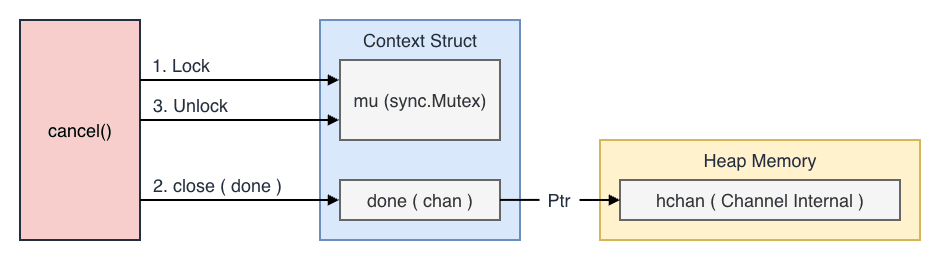
2. スケジューラによるステート変更
Go では <-ctx.Done() のように Channel の受信待ちをしている Goroutine は、まだデータが来ていないため一時的に停止状態(Waiting)になっています。
close(done) が実行されると、Go ランタイムスケジューラは即座にこれらの Goroutine を「待機中」から「実行待ち(Runnable)」の状態へ変更し、実行キューに積みます。
この操作もすべて Go ランタイム内のメモリ操作であり、カーネルスレッドを生成したり切り替えたりするような高コストな処理は発生しません。

3. 必要最小限のシステムコール
2 で実行待ちキュー(Run Queue)に積まれた Goroutine を実際に処理するには、カーネルスレッド(M)が必要です。 Go ランタイムは、現在稼働しているスレッドだけで処理が追いつかない、あるいはスレッドが寝ている(Sleeping)場合にのみ、futex を発行してカーネルスレッドを叩き起こします。
従って、「1(フラグ操作)」と「2(ステート変更)」は全てユーザ空間で完結し、実際に物理リソースが必要になった瞬間、初めてカーネルを呼び出す設計になっています。 OS シグナルのようにプロセス全体に無条件で割り込みをかける高コストな処理とは異なり、Go の Context キャンセルは 必要な時だけ最小限のシステムコールを発行する ため、無駄なリソース消費を抑えることができるわけです。
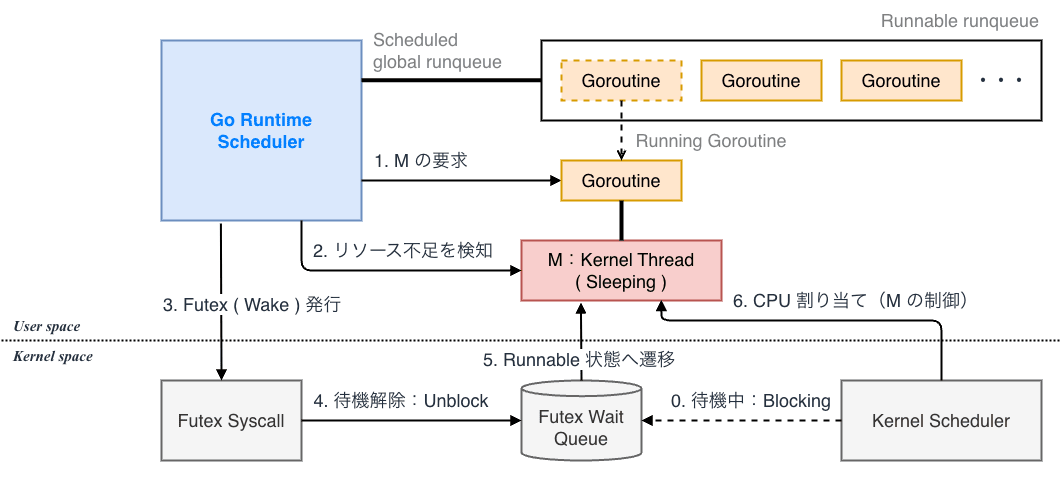
このように Go の Context キャンセルは メモリ操作によるフラグの伝播 として振る舞うことで、処理負荷の高いカーネル操作を最小限に抑えています。 この仕組みにより、Graceful Shutdown 時に停止処理そのもので CPU を占有することなく、リクエストの完了処理やリソース解放にフルに充てることができます。
Graceful Shutdown の実装
Context の仕組みについて理解したところで、実際に Go アプリケーションにおける Graceful Shutdown の実装に踏み込みます。
ここでは、標準パッケージ net/http と、マイクロサービスで広く利用される gRPC サーバを例に、Graceful Shutdown の実装について紹介します。
標準パッケージの仕様
net/http 自体は Graceful Shutdown の機能を備えていますが、正しく使うにはいくつかのポイントがあります。
http.Server.Shutdown の内部挙動
srv.Shutdown(ctx) を呼び出した際、内部では具体的に以下の処理が行われます。
ここでは net/http を例に説明しますが、gRPC の GracefulStop も新規リクエスト(RPC)の拒否と処理中リクエストの完了待機という基本的な流れは共通しています。
-
ln.Close()でリスナーを閉鎖即座に TCP ポートの Listen を停止し、OS レベルで SYN パケットによる新規接続を拒否します。参考
-
アイドル接続の閉鎖とアクティブ接続の待機
リスナーを閉じた後は、ポーリングループに入ります。 このループ内で
closeIdleConns()を呼び出すことで、以下の 2 つの処理を同時に行います。- アイドル接続のクローズ:HTTP Keep-Alive で維持されているが、現在リクエストを処理していない接続を即座に閉じる
- アクティブ接続の監視:ハンドラが実行中の接続(アクティブ接続)が残っているかを確認する
アクティブな接続が残っている場合、
closeIdleConns()はfalseを返し、次のポーリングまで待機します。 すべての接続がアイドル状態(または終了済み)になるとtrueを返し、シャットダウン処理が完了します。参考 -
コンテキストの監視
引数で渡された
ctxは、SIGTERM 受信後に設定された待機時間の制限(Grace Period)を意味します。 まだ処理中のリクエストが残っていたとしても、このctxがタイムアウト(DeadlineExceeded)すれば、Shutdownは待機を諦めてエラーを返します。参考これにより、一部のリクエストがハングしてもアプリケーション全体が永遠に終了しないという事態を防ぎ、Kubernetes 側の
terminationGracePeriodSeconds(強制停止までの猶予)を超過する前に、自発的にプロセスを終了させる制御が可能になります。
HTTP/2 と gRPC の場合
Go の net/http はデフォルトで HTTP/2 をサポートします。
Starting with Go 1.6, the http package has transparent support for the HTTP/2 protocol when using HTTPS.
HTTP/2 の場合、Graceful Shutdown 時に GOAWAY フレーム が送信されます。 GOAWAY フレームとは、サーバがこれ以上新しいストリーム、すなわちリクエストを受け付けないことをクライアントに通知する仕組みです。 クライアントはこれを受け取ると、既存のストリームは継続しつつ、別の Pod への新しい TCP 接続を使おうとします。
google.golang.org/grpc パッケージの gRPC サーバも同様に、GracefulStop() が呼ばれると GOAWAY フレームを送信して新規 RPC を拒否しつつ、既存の RPC が完了するのを待ちます。
Drain メソッドが呼び出されると、controlBuf 経由で goAway イベントが発行され、最終的に outgoingGoAwayHandler 内で WriteGoAway が実行されて GOAWAY フレームが送信されます。
GOAWAY フレームの構造は RFC7540 で定義されています。
ただし、後述するように GracefulStop() はコンテキストを受け取らないため、タイムアウト制御の実装方法が異なります。
実装パターンとベストプラクティス
HTTP サーバの場合
以下に、プロダクションレベルで推奨される実装パターンを紹介します。
ここでは RegisterOnShutdown も活用し、HTTP サーバ以外のリソース解放も組み込んでいます。
2. gRPC サーバの場合
gRPC サーバの場合、標準で提供されている GracefulStop() メソッドは context を引数に受け取りません。
これが net/http の Shutdown(ctx) との大きな違いであり、実装上の注意点となります。
GracefulStop() は、全てのアクティブな RPC 通信が完了するまで無期限にブロックします。
そのため、これだけを使用すると、特定のクライアントが切断しない場合に Pod がいつまでも終了できず、最終的に Kubernetes の terminationGracePeriodSeconds 超過による SIGKILL を待つことになってしまいます。
そこで、net/http と同様に制限時間付きの Graceful Shutdown を実現するには、以下のように select 文を用いて自前でタイムアウト制御と強制停止(Stop())のロジックを実装する必要があります。
実装のポイントと注意点
標準の Shutdown メソッドや Context を利用する上で、いくつか押さえておくべきポイントと注意点があります。
Context タイプの選定
Shutdown メソッドに渡す Context の選定は、停止処理の安全性を左右します。
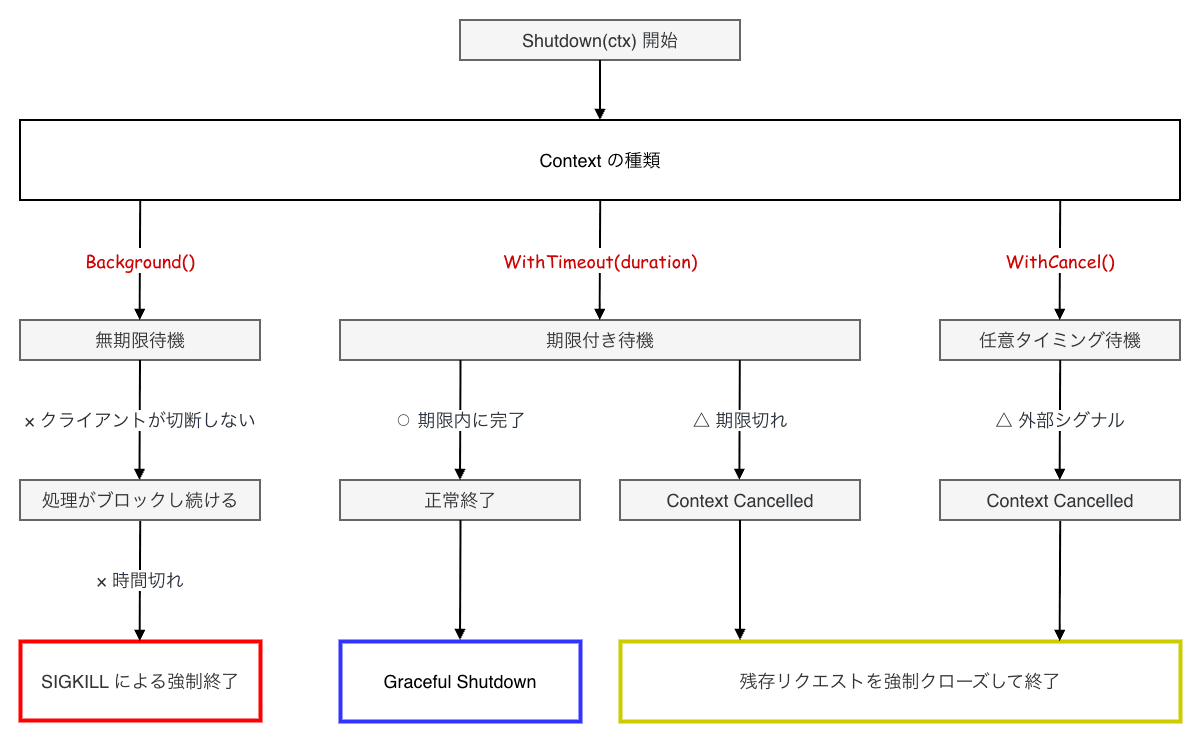
-
context.Background():非推奨これはアンチパターンです。 タイムアウトが設定されていないため、アクティブな接続が終了しない場合(例:クライアントがハングアップしている)、
Shutdownは永遠にブロックし続けます。 その結果、Kubernetes のterminationGracePeriodSecondsに達して SIGKILL されるまで、ログも出力されずにプロセスが固まることになります。 -
context.WithTimeout:推奨アプリケーションが終了処理にかけられる猶予期間を明示します。 Kubernetes の
terminationGracePeriodSecondsから preStop の時間を引いた値よりも少し短めに設定するのが一般的です。 -
context.WithCancel:条件付き外部要因(例:別の管理 API からの停止指示)で即座にシャットダウンを中断・強制終了したい場合に使用しますが、通常の Graceful Shutdown では
WithTimeoutで十分な場合が多いです。
Idle Connection と Keep-Alive
Shutdown メソッドが呼ばれると、Keep-Alive で維持されているアイドル状態の接続は即座に閉じられます。
もし http.Server における IdleTimeout の設定値が長すぎる場合(デフォルトは ReadTimeout に依存、または設定なし)通常時でもアイドルコネクションが長く残ります。
Shutdown 時にこれらが一斉に切断されると、クライアント側(別のマイクロサービス等)で再接続のスパイクが発生する可能性があります。
Graceful Shutdown の観点からは、IdleTimeout はロードバランサのアイドルタイムアウトより少し長く、かつ長すぎない値に設定します。
WebSocket と Hijacked Connection
net/http の Shutdown メソッドは、WebSocket や Hijack された接続に対しては自動的な切断や終了待機を行いません。
これは、WebSocket 通信開始時(ハンドシェイク完了後)に、接続の管理権限が http.Server からアプリケーションまたは WebSocket ライブラリに移譲されるためです。
net/http ではこれを Hijacked Connection と呼んでいます。
Shutdown does not attempt to close nor wait for hijacked connections such as WebSockets. The caller of Shutdown should separately notify such long-lived connections of shutdown and wait for them to close, if desired.
結果として、これらの接続は Shutdown が監視するアクティブな接続リストから除外されるため、自前で終了処理を実装しない限り、サーバ停止時も接続が維持され続けてしまいます。
WebSocket を多用するアプリケーションの場合、シャットダウンシグナルを受け取ったタイミングで、アプリケーション側から能動的に Close Frame を送信して接続を閉じるロジックを別途実装する必要があります。
前述の通り、標準の Shutdown メソッドはこれらの接続を関知しないため、アプリケーション側で現在どのクライアントが接続しているかを管理し、停止時にはそれらに対して個別に終了処理を行う必要があります。
Go の WebSocket 実装として有名な gorilla/websocket の Chat Example では、この接続管理の役割を持つ構造体を Hub という名称で実装するパターンが用いられます。
Hub は全クライアントの登録・削除と、メッセージのブロードキャストを一元管理します。
Graceful Shutdown を実装する場合、この Hub に全クライアントを切断するためのメソッド(例:Stop() や Close())を追加し、メインのシャットダウンフローから呼び出す形になります。
- Hub 構造体に Stop メソッドを追加する実装例
ここで指定している websocket.CloseGoingAway(値は 1001)は、RFC6455 で定義された標準のステータスコードです。
1001 indicates that an endpoint is "going away", such as a server going down or a browser having navigated away from a page.
これを受け取ったクライアントは、サーバがダウンまたは再起動するために切断されたという意図を正確に理解できるため、単なるネットワークエラーと区別して、適切な再接続ロジック(例:少し待ってから再接続する)を実行することが可能になります。
クラウドプロバイダとの整合性
Kubernetes の外側にある Ingress Controller や LoadBalancer を使用する場合、それぞれの切り離し挙動(Deregistration)を考慮する必要があります。
AWS ALB:Amazon Elastic Load Balancer
ALB のターゲット切り離しには Deregistration Delay(デフォルト 300 秒)があります。
Pod が先に終了してしまうと、ALB は 502 Bad Gateway を返します。
preStop を長めに設定するか、ALB の deregistration_delay.timeout_seconds を 30 秒程度まで短くして Pod のライフサイクルに合わせる調整が必要になります。
Nginx Ingress Controller
worker-shutdown-timeout という設定があり、Nginx のワーカープロセスが終了するまでの猶予時間を制御します。
これが短すぎると、リクエスト処理中に Nginx が強制終了する可能性があります。
GCLB:Google Cloud Load Balancer
ヘルスチェックの間隔と Unhealthy 閾値の設定が重要になります。 終了検知までのタイムラグを preStop でカバーするのが基本的な戦略となります。
GCLB のヘルスチェックはクラスタの外部から実行されるため、Pod が停止しても LB がそれを検知して切り離す(Unhealthy と判定する)までにはタイムラグが発生します。
例えば、以下の設定の場合、最悪で約 10 秒間は停止中の Pod にリクエストが転送され続け、502 エラー等の原因になります。
- Check Interval:5 sec
- Unhealthy Threshold:2 times
この切り離し待ち時間を稼ぐために、preStop フックで意図的な待機時間を設けます。
ここで、preStop フックによる待機時間を 15 秒としているのは、5s (interval) * 2 (threshold) = 10s に加え、伝播遅延や SIGTERM 送信までのラグを考慮した上で、安全マージン(+5s)を含めているためです。
アンチパターン
最後に、やりがちな失敗例、いわゆるアンチパターンを紹介しておきます。
os.Exit()を直接呼ぶ
シグナルを受け取ってすぐに os.Exit(0) してしまうと、その瞬間にプロセスが死にます。
これでは、Shutdown() の待機処理が全て無駄になってしまいます。
- エラーを握りつぶす
srv.Shutdown() のエラーをチェックせず、タイムアウトしたのか正常終了したのか分からない状態にするのは危険です。
以下の例では、ログも出ないため、なぜ終了したのか、あるいはタイムアウトしたのかを追跡できません。
- preStop を短くしすぎる
sleep 1 のような短すぎる設定は、大規模クラスタや高負荷時の kube-apiserver 遅延に対応できません。
最低でも 5 秒、可能なら 10 秒程度が推奨されます。
Contextを渡さない
context.Background() をそのまま渡してしまうと、クライアントがハングした場合にサーバが永遠に終了できず、最終的に SIGKILL されるまでゾンビ化します。
WithTimeout を使ってタイムアウトを設定することが推奨されます。
まとめ
Graceful Shutdown は信頼性の高い Web アプリケーションを構築する上で欠かせない要素技術の一つです。
特に Kubernetes 上で動作する Go アプリケーションにおいては、context パッケージによるキャンセル信号の伝播と、net/http や google.golang.org/grpc といった各ライブラリのシャットダウン仕様を正しく理解し、適切に組み合わせる実装力が求められます。
今回のブログでは、hchan や futex といった Go ランタイムの内部挙動から、RegisterOnShutdown や GracefulStop を活用した具体的なコード実装に至るまで、Graceful Shutdown を実現するための技術的な詳細を紹介しました。
Kubernetes 側での preStop フックによるトラフィック遮断待ちと、アプリケーション側での Shutdown(ctx) メソッドによる終了処理の両方が適切に実装されて初めて、リクエストの欠損を防ぐ安全な停止が実現されます。
Kubernetes における Pod の終了プロセスについては こちらのブログ で紹介しています。