コンテナ仮想化技術と Kubernetes の俯瞰図 - 基礎編
はじめに
近年、クラウドネイティブなアプリケーション開発において Kubernetes はデファクトスタンダードとしての地位を確立しつつあります。 今後はインフラエンジニアだけでなく、アプリケーション開発者にとっても、コンテナ上で動作するサービスのライフサイクルやリソース管理を理解することはほぼ必須のスキルになっていくと考えられます。
今回のブログは基礎編と実践編の 2 部に分け、基礎編となる本記事では、Kubernetes がなぜ必要とされているのかについて、背後にあるコンテナ仮想化技術や Linux カーネルの仕組みを交えつつ章立てて紹介したいと思います。
また、実践編 では Pod の詳細なライフサイクル、ネットワークの仕組み、ワークロード管理といった、Kubernetes の実践的な運用について紹介します。
第 1 章:Kubernetes の誕生秘話
皆さんは Kubernetes と聞いて何を思い浮かべますか? 「難しそう」「最近よく耳にする」「結局何なのかよく分からない」「コンテナを管理するものらしいけど」「Docker とは何が違う?」
もしそう感じていたとしても、それはごく自然なことだと思います。 実際、Kubernetes は構成要素も多く、学習コストが高い技術であることは間違いありません。 なぜなら、これまでの多くの技術を詰め込んでいるだけに、アプリケーション開発だけでなく、基本的なコンピュータサイエンスについても理解している必要があるからです。
本章では Kubernetes の技術的な詳細に入る前に、なぜこのシステムが生まれ、どのように発展してきたのか、歴史的背景を少しだけ覗いてみたいと思います。
1.1 Borg
Kubernetes は元々、Google が管理する複雑なインフラを効率的に動作させるために提案されました。
当初、Borg と呼ばれる Google の内部プロジェクトによって発足し、大規模なクラスタ管理システムとして 2003 年頃から開発が進められました。 Borg は、Google のサービスやジョブを数千台以上のマシンで効率的に実行し、スケジューリング、ロードバランシング、障害復旧の自動化といった機能を提供しました。
2014 年になると Google Cloud は、Google の社内で使われているツール類が分散コンテナ実行基盤上で動作していることを明らかにし、毎週 20 億台のコンテナを起動 していると発表しました。 今日、我々が利用する Google のソリューション(Gmail / Google Search / YouTube 等)は、そのほとんどがコンテナによって提供されています。
Borg のアーキテクチャ:Kubernetes の原点
Google が 2015 年に公開した論文『Large-scale cluster management at Google with Borg』を見てみると Borg のアーキテクチャは 現在の Kubernetes とよく似ていることが分かります。
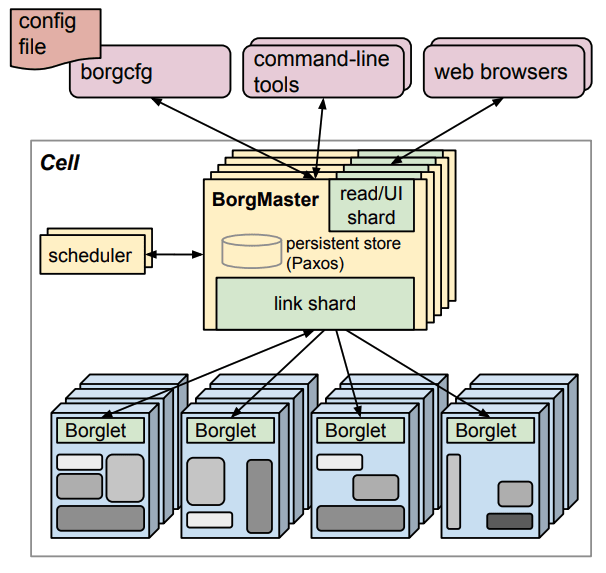
- BorgMaster:Kubernetes の Control-Plane に相当し、Paxos と呼ばれるアルゴリズムを用いて 5 つのレプリカでステートを管理
- Borglet:Kubernetes の kubelet に相当し、各マシンでタスクを起動・監視
- Alloc:Kubernetes の Pod に相当し、複数のプロセス(タスク)がリソースを共有する単位
Kubernetes は Go で書かれていますが、Borg は C++ で書かれていたようです。
1.2 オープンソース化と CNCF
Borg の成功を受け、Google はそのアーキテクチャやアイデアをベースにしたオープンソースのプロジェクトを開発し、これが今日我々が Kubernetes と呼んでいるものです。
2014 年に Google は Kubernetes を公式に発表し、Apache 2.0 ライセンスの下でオープンソースとしてリリースしました。 Kubernetes は Borg のアーキテクチャや概念を引き継ぎながら、クラウド環境でのコンテナ化されたアプリケーションの管理を容易にするよう拡張されました。
Kubernetes は 2015 年 7 月に version 1.0 として GA(General Availability)を迎える とともに、Google は Linux Foundation と共同で CNCF(Cloud Native Computing Foundation)を設立し、Kubernetes を主となる技術として提供しました。 現在では、CNCF がオープンソースとして Kubernetes を管理しており、業界全体での開発と普及が促進しています。
さらに、近年では Google Cloud、AWS、Azure 等のパブリッククラウドがマネージド Kubernetes エンジンとして、それぞれ GKE(Google Kubernetes Engine)、EKS(Elastic Kubernetes Service)、AKS(Azure Kubernetes Service)を提供しています。 パブリッククラウドのサービスでは Kubernetes の複雑な仕組み(特に Control-Plane の管理)が抽象化されているため、ユーザは容易に扱うことができます。
1.3 「Kubernetes」の由来

そもそも「Kubernetes」という名称は、ギリシャ語で「操舵手(Helmsman)」や「操縦士(Pilot)」を意味する言葉に由来します。 ここには、コンテナという積み荷を積んだ巨大な船を、変化し続ける外洋(クラウドの海)の中で、目的地まで安全かつ自律的に導く存在であるという哲学が込められています。
Kubernetes 関連のツールやエコシステム(Helm / Istio / Argo / Flux / Autopilot 等)に船舶や航海、宇宙探査に纏わる名前が付けられるのも、ここから来ていると思われます。 Pod という単語も「クジラの群れ(Pod of Whales)」を意味しており、Kubernetes において 1 つまたは複数のコンテナグループを表します。
また、「Kubernetes」という単語は「サイバネティクス(Cybernetics)」の語源でもあります。 常にシステムの現状を監視し、あるべき状態へと自動的に補正し続ける Kubernetes のアーキテクチャは、制御理論そのものを体現していると言えます。
ちなみにロゴマークのホイールにある 7 本のスポークは、Google 内部で命名された当初の開発コードネーム「Seven of Nine」へのオマージュとして残されているようです。
Kubernetes は "K8s" と略されますが、これは "K" と "s" の間に 8 文字 あることに由来しています。
第 2 章:コンテナ仮想化技術と Docker
本章では、Kubernetes を理解する上で避けては通れない「コンテナ仮想化」の基礎概念と、デファクトスタンダードである Docker について紹介します。
2.1 アプリケーションデプロイの進化とコンテナ仮想化
なぜ今、コンテナ技術がこれほどまでに注目されているのでしょうか。 その理由を理解するために、アプリケーションのデプロイ環境がどのように進化してきたのかを振り返ってみます。
デプロイの変遷:3 つの時代
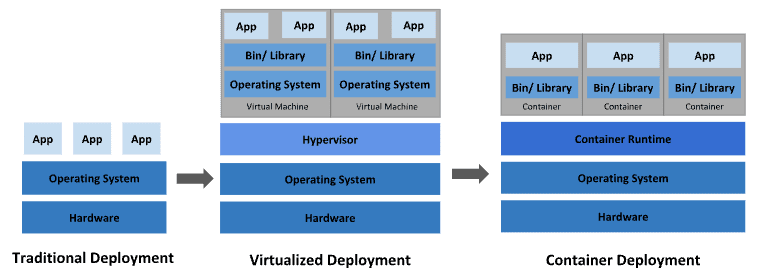
1. 物理サーバの時代
元来、組織はアプリケーションを物理サーバ上で直接実行していました。
しかし、物理サーバ上のリソース(CPU やメモリ)の境界をアプリケーション毎に定義する方法がなかったため、リソース割り当ての問題が発生しました。
例えば、複数のアプリケーションを 1 台の物理サーバで実行すると、あるアプリケーションがリソースの大半を消費してしまい、他のアプリケーションのパフォーマンスが低下することがあります。 これを避けるには、アプリケーション毎に異なる物理サーバを用意する必要がありましたが、リソースの使用率が低くなるためコストが嵩み、多数の物理サーバを維持・管理する手間も膨大になりました。
2. 仮想化の時代
この問題を解決するために導入されたのが「サーバ仮想化技術」です。 仮想化技術により、単一の物理サーバの CPU 上で複数の仮想マシン(VM)を実行できるようになりました。 仮想化はアプリケーションを VM 毎に隔離するため、あるアプリケーションの情報に他のアプリケーションから自由にアクセスさせないことで強固なセキュリティを実現します。
仮想化により、物理サーバのリソースをより効率的に活用でき、スケーラビリティも向上しました。 これは、アプリケーションの追加や更新が容易になり、ハードウェアコストを削減できるためです。
また、各 VM は仮想化されたハードウェア上で、独自の OS を含むすべてのコンポーネントを実行するマシンとなり、VM 間の隔離性が高いことが特徴です。
3. コンテナの時代
コンテナは VM に似ていますが、アプリケーション間で OS(カーネル)を共有するため隔離特性が緩和され、VM よりも軽量とされています。
VM と同様に、コンテナは独自のファイルシステム、CPU のシェア、メモリ、プロセス空間を持ちます。 基礎となるインフラから分離されているため、クラウドや OS ディストリビューションを問わず移植可能です。 これを Portability(可搬性)と呼んだりします。
仮想マシンとコンテナアーキテクチャの違い
従来の VMware や KVM といったハイパバイザ型の仮想化と、コンテナ仮想化の最大の違いはゲスト OS の有無にあります。
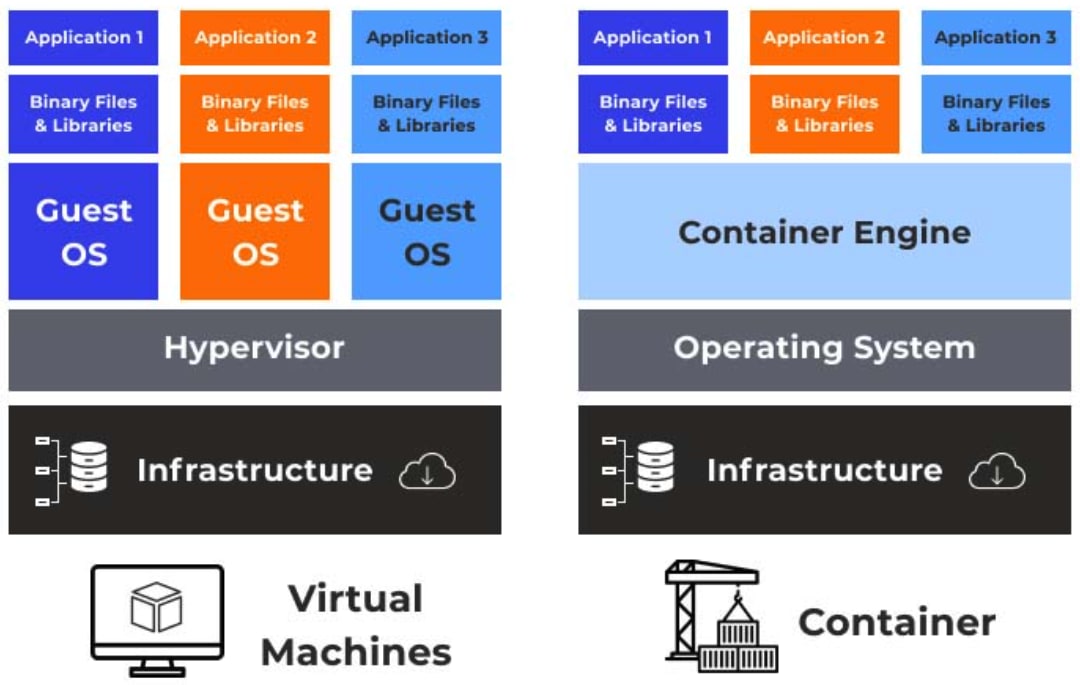
-
ハイパバイザ型(VM)
- ハードウェアを仮想化
- 各 VM は完全なゲスト OS(カーネル空間 + ユーザ空間)を持つ
- メリット:強固な隔離 / 異なる OS(Windows on Linux)の実行が可能
- デメリット:OS 起動に数分かかる / メモリ消費が大きい(GB 単位)
-
コンテナ型
- OS(カーネル空間)を仮想化・共有
- コンテナ内にはアプリケーションと最小限のユーザ空間(bin / lib)しか持たない
- メリット:起動がミリ秒単位 / メモリ消費が極小(プロセス分のみ)/ 移植性が高い
- デメリット:ホストとカーネルを共有するため、カーネルパニックがホストに波及するリスクがある
従来のサーバ仮想化技術については こちらのブログ でも紹介しています。
なぜコンテナが必要なのか
端的に述べると「あるマシンでは動いたのに、別のマシンでは動かない」という可搬性の問題を解決するためです。
従来の開発では、開発環境、テスト環境、本番環境で、OS のバージョンやインストールされているライブラリの微妙な差異により、予期せぬバグが発生していました。 コンテナは「実行環境そのもの」をパッケージングするため、どこで動かしても同じ動作を保証できます。 これを Immutable Infrastructure(不変的インフラ) と呼んだりします。
さらに、以下のような利点により、コンテナは人気を博しています。
- アジャイルなアプリケーション作成とデプロイ:VM イメージと比較してコンテナイメージの作成は容易
- 継続的な開発 / インテグレーション / デプロイ:イメージの不変性(イミュータビリティ)により、信頼性の高い頻繁なビルドとデプロイが可能になり、ロールバックも迅速に行える
- Dev と Ops の関心の分離:デプロイ時ではなくビルド / リリース時にアプリケーションコンテナイメージを作成することでアプリケーションとインフラを分離できる
- 環境の一貫性:ローカル環境でもクラウド上でも同じように動作することが保証される
- リソースの隔離と利用効率:アプリケーションのパフォーマンスを予測可能にし、高効率かつ高密度なリソース利用を実現する
2.2 Docker の歴史と進化
Docker は、2013 年に dotCloud 社(現 Docker, Inc.)の CTO である Solomon Hykes 氏によって PyCon で初めて発表されました。 元々は Docker 社の内製ツールでしたが、以下の革命的な機能により爆発的に普及しました。
- Docker Image:アプリケーションの配布形式を統一
- Dockerfile:インフラ構築手順をコード化(IaC)
- Docker Hub:巨大なエコシステムとレジストリ
OCI(Open Container Initiative)による標準化
当初、Docker は独自の仕様で動いていましたが、コンテナ技術の普及に伴い、標準化団体の OCI(Open Container Initiative) が設立されました。 現在、Docker や Kubernetes は以下の OCI 標準に準拠しています。
- runtime-spec:コンテナのライフサイクルや実行環境の仕様
- image-spec:コンテナイメージのフォーマット仕様
- distribution-spec:コンテナイメージの配布仕様
2.3 Docker のアーキテクチャ
Docker はクライアントサーバ型のアーキテクチャを採用しています。
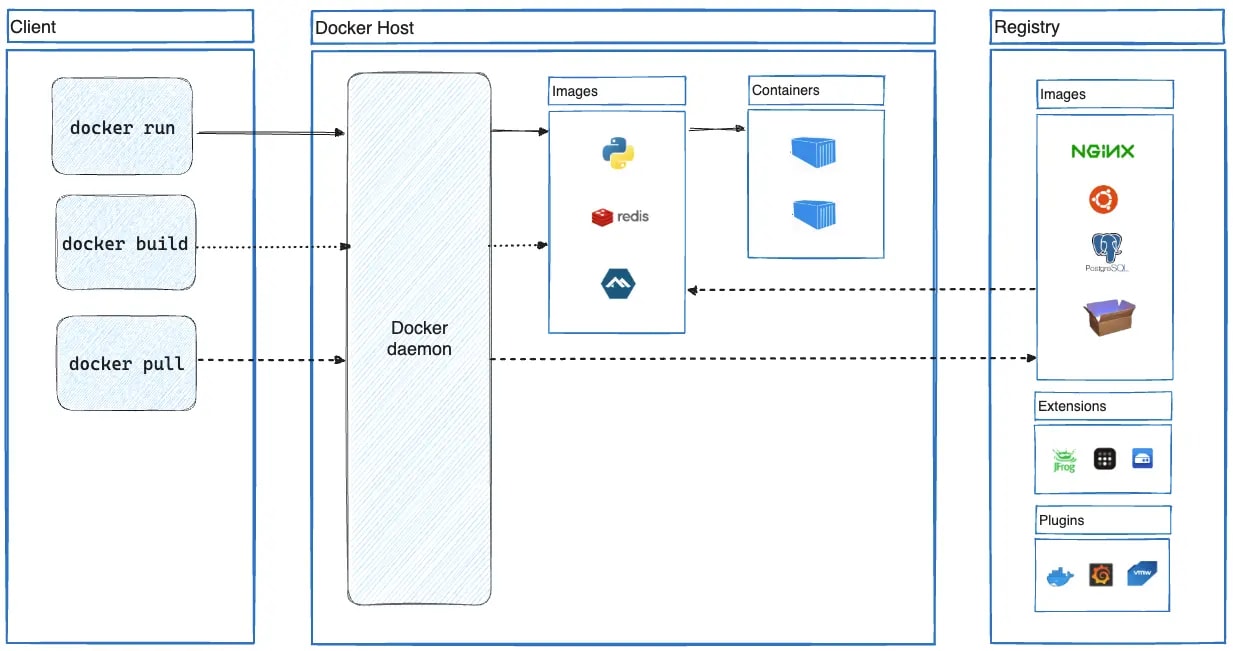
-
Docker CLI(クライアント)
- ユーザが叩く
docker runやdocker buildコマンド - REST API を通じて Docker Daemon に命令を送る
- ユーザが叩く
-
Docker Daemon(dockerd)
- ホスト上で常駐するバックグラウンドプロセス
- API リクエストを受け付け、イメージ、コンテナ、ネットワーク、ボリュームを管理する
-
containerd
- 元々は Docker の一部だったが、高レベルランタイムとして CNCF に寄贈された
- dockerd からコンテナ実行の責務を委譲され、イメージの Pull やコンテナの管理を行う
-
runc
- OCI 準拠の低レベルランタイム
- 実際に Linux カーネルの機能(Namespace, cgroups)を操作してコンテナプロセスを生成する
2.4 Docker イメージの仕組み
Docker イメージはバイナリファイルではなく、レイヤ(Layer) と呼ばれる差分ファイルの積み重ねで構成されており、その構造は OCI Image Specification で厳密に定義されています。

Image Manifests と Config
docker inspect <image> コマンドを叩くと、JSON 形式のメタデータが表示されますが、その裏側には主に 2 つの重要なファイルが存在します。
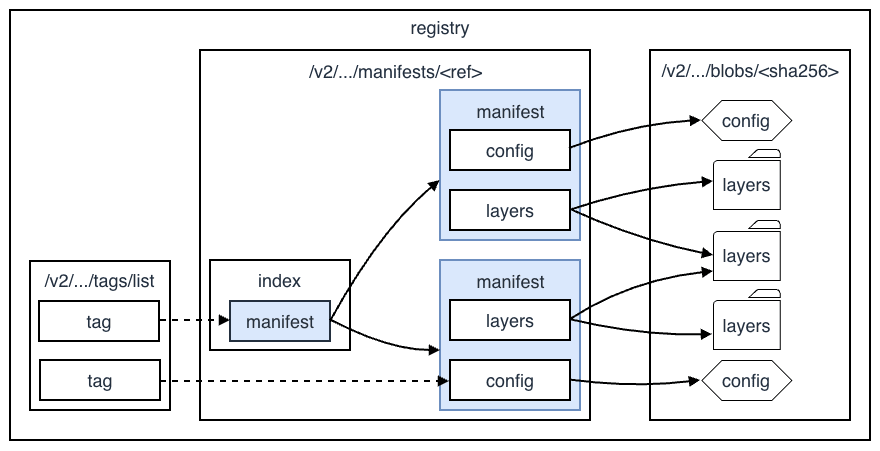
-
Manifest(
manifest.json)- イメージを構成するレイヤ(blobs)のリストと設定ファイルへの参照を持つ
- コンテンツアドレス可能な識別子(SHA256 ハッシュ)で各レイヤを特定することで異なるイメージ間でも、内容が同じレイヤ(例:同じバージョンの
ubuntu:20.04ベース)であれば物理的なディスク容量を共有できる
-
Image Config(JSON)
- コンテナ起動時のデフォルト設定(例:
CMD/ENTRYPOINT/ENV/USER) やビルド履歴(HISTORY)が記述される docker historyコマンドは、このファイルを解析して表示する
- コンテナ起動時のデフォルト設定(例:
UnionFS
Docker は UnionFS(Union File System)と呼ばれる仕組みを利用して、複数の読み取り専用レイヤを 1 つの統合されたファイルシステムに見せかけます。
UnionFS は、複数のディレクトリ(ブランチ)を透過的に重ね合わせる技術の総称です。 初期の Docker では aufs(advanced multi-layered unification filesystem) が使われていましたが、現在は Linux カーネル標準機能として取り込まれ、より高速で安定している OverlayFS(Docker では overlay2)が標準的に使用されています。
Overlay2 の構造
Linux の /var/lib/docker/overlay2 配下には、各コンテナとイメージの実体が保存されています。
Overlay2 は以下の 4 つのディレクトリで構成されています。
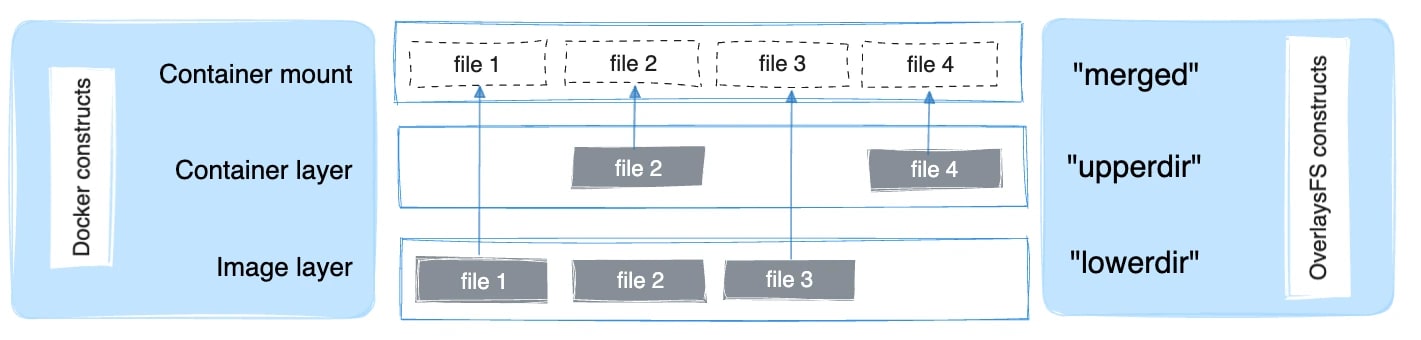
- LowerDir
- イメージの各レイヤ
- 読み取り専用(Read-Only)
- 複数層積み重なる
- UpperDir
- コンテナの変更差分を保存するレイヤ
- 書き込み可能(Read-Write)
- WorkDir
- OverlayFS が内部処理(アトミックなコピー等)に使用する作業用ディレクトリ
- Merged
- アプリケーションから見える、これらを統合したビュー(マウントポイント)
Copy-on-Write(CoW)
Copy-on-Write(CoW) とはリソースを複製する際に、即座に物理的なコピーを行わず、最初は参照(ポインタ)のみを渡すことでリソースを共有する戦略のことです。 そして、実際に書き込みが発生した瞬間に初めてコピーを行います。
コンテナ内のプロセスがファイルに書き込みを行う際、カーネルレベルで以下の動作が発生します。
- 検索:ファイルが
UpperDirに存在するかを確認する - コピー:存在しない場合(
LowerDirにしか無い場合)、LowerDirからUpperDirへファイル全体をコピーする(copy-up 動作) - 書き込み:
UpperDirにあるコピーに対して書き込みを行う - 削除(Whiteout):
LowerDirにあるファイルを削除する場合、UpperDirに Whiteout ファイル(キャラクタデバイス 0:0 等)を作成して下層のファイルを隠蔽する
この仕組みにより、数 GB あるベースイメージを瞬時にコピーして新しいコンテナを作成(実際にはポインタ参照のみ)することができ、ストレージ効率と起動速度が劇的に向上します。
しかし、頻繁に書き換えられる巨大なデータベースファイル等をコンテナレイヤ(CoW)上に置くと、copy-up のオーバーヘッドでパフォーマンスが著しく低下するため、必ず Volume を使用すべきです。 これは、Volume を利用することで Docker 管理下にあるホスト側のファイルシステム領域にデータを保存できるため、UnionFS の仕組みをバイパスしてネイティブなディスク I/O 速度で読み書きが可能になるからです。
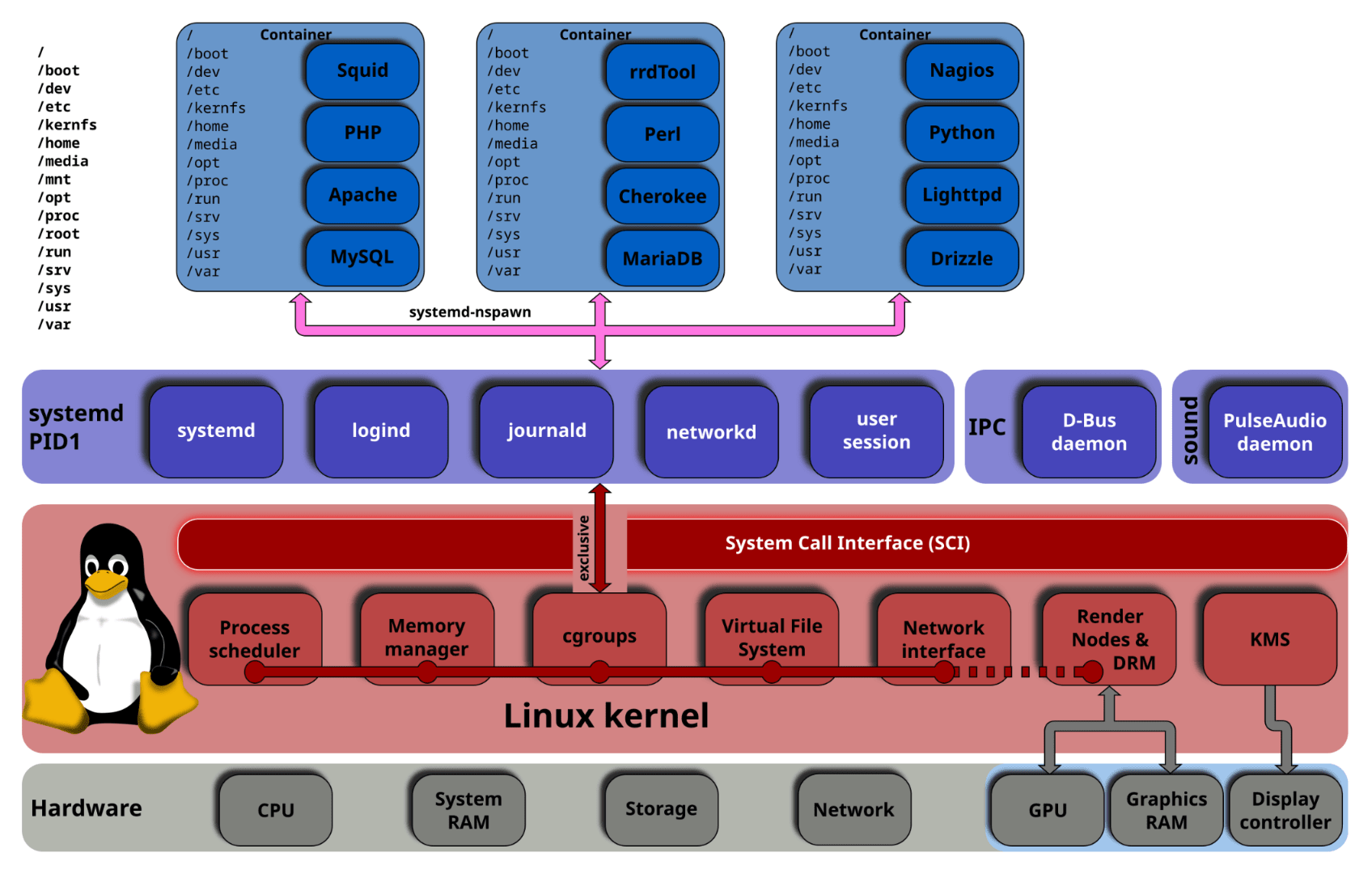
第 3 章:コンテナと Linux カーネルの機能
本章では、Docker や Kubernetes を支える根幹技術である Linux カーネルの機能について掘り下げてみます。 「コンテナがなぜ隔離されるのか」「なぜリソース制限ができるのか」という原理をカーネルの仕組みから理解することは、Kubernetes のトラブルシューティングにおいても武器となります。
3.1 "コンテナ" という技術は存在しない
"コンテナ" という技術は存在しない?
そうです。 実は Linux カーネルのソースコードを探しても「Container」という単一の機能やシステムコールは存在しません。
我々が普段「コンテナ」と呼んでいるものは、Linux カーネルが提供する複数の 独立した機能を組み合わせたセット に便利な名前を付けただけに過ぎません。
その構成要素の主要な柱は以下の 3 つです。
- Namespace(名前空間):見える範囲を制限する
- cgroups(Control Groups):使えるリソースを制限する
- UnionFS / OverlayFS:ファイルシステムを階層化する(※ 前述の通り)
ここでコンテナ仮想化技術を深掘るために Linux カーネルの内部実装に目を向けてみます。
3.2 Namespace(名前空間)でリソース隔離
Namespace はグローバルなシステムリソースをラップし、プロセスに対して「自分専用のリソースを持っている」ように見せかける Linux カーネルの機能です。 これにより、コンテナ内のプロセスは、自分があたかも独立した OS 上で動いているかのように錯覚します。
clone() システムコール
Linux で新しいプロセスを作成する場合、通常は fork() と呼ばれるシステムコールを使いますが、Namespace を作成する場合は clone() システムコールを使用し、引数 flags に特定のビットマスクを渡します。
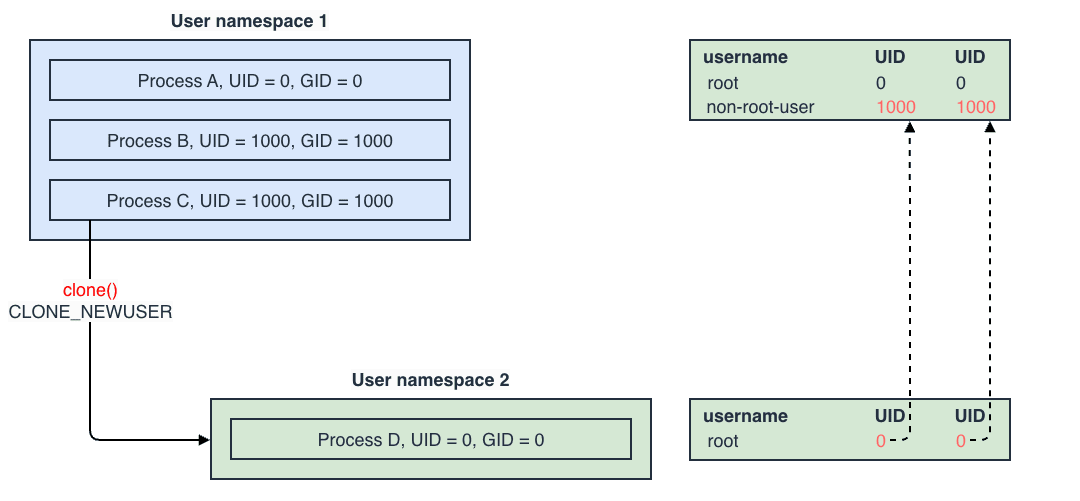
以下は C 言語で Namespace を作成する概念コードの例です。
このように、clone() システムコールの引数として Namespace のフラグ(CLONE_NEW...)を渡すだけで、プロセスは隔離された環境で起動します。
つまり、コンテナの作成とは、カーネルレベルで見れば 特定の Namespace フラグを立ててプロセスを起動する ことと同義になります。
主要な Namespace とその役割
| Namespace | フラグ | 隔離対象 | 詳細解説 |
|---|---|---|---|
| PID | CLONE_NEWPID | プロセス ID | 新しい Namespace 内の最初のプロセスは PID 1。PID 1 は特別な意味(init プロセス)を持ち、シグナル処理や子プロセスの回収(reap)を担当する。コンテナ内からはホストのプロセスは見えない。 |
| Network | CLONE_NEWNET | ネットワークスタック | 独自のネットワークインターフェース(veth)、IP アドレス、ルーティングテーブル、iptables ルール、ソケットを持つ。コンテナ毎の IP アドレス割り当てはこれにより実現される。 |
| Mount | CLONE_NEWNS | マウントポイント | 独自のファイルシステムツリーを持つ。chroot の進化版とも言えるが、マウント情報の伝播(Propagation)等の高度な制御ができる。 |
| UTS | CLONE_NEWUTS | ホスト名 / ドメイン名 | hostname コマンドで設定されるホスト名を独立させる。これにより、コンテナ毎に異なるホスト名を持つことができる。 |
| IPC | CLONE_NEWIPC | IPC リソース | System V IPC オブジェクト(共有メモリ、セマフォ、メッセージキュー)や POSIX メッセージキューを隔離する。 |
| User | CLONE_NEWUSER | UID / GID | ホスト上の一般ユーザ(UID 1000)を、コンテナ内では root(UID 0)にマッピングすることができる。これにより、特権を持たないコンテナのセキュリティを強化できる。 |
| Cgroup | CLONE_NEWCGROUP | Cgroup ルート | プロセスから見える cgroup の階層構造を仮想化する。 |
unshare コマンドで Namespace を触る
Linux の unshare コマンド を使うと、Docker を使わずに Namespace の隔離を直接確認することができます。 実際に手元の Linux 環境で試してみると理解が深まります。
通常の環境では PID 1 は systemd や init ですが、ここでは bash が PID 1 になっていることが分かります。
これがコンテナの原始的な姿になります。
ホスト OS の他のプロセスは一切見えません。
3.3 cgroups(Control Groups)でリソース管理
Namespace が「視界を遮る壁」だとすると、cgroups は物理的なリソースを配給制限する「蛇口」のようなものです。 cgroups がなければ、あるコンテナが CPU を 100% 使い切ったり、メモリリークを起こしたりすると、ホスト OS 全体を道連れにクラッシュさせることになります。
cgroups の階層構造とコントローラ
cgroups はファイルシステム(通常は /sys/fs/cgroup)として実装されています。
実際に /sys/fs/cgroup の中を覗いてみると、プロセスがファイルシステムとして表現されていることがわかります。
ここにディレクトリを作成すると、それが新しい cgroup となり、その中に PID を書き込むことでプロセスをグループに所属させることができます。
主なサブシステムは以下の通りです。
- cpu
cpu.cfs_quota_us / cpu.cfs_period_us パラメータで、CFS(Completely Fair Scheduler)の帯域制限を行います。
Kubernetes の limits.cpu はこのパラメータにマッピングされます。
例えば 100000(quota)/ 100000(period)なら 1 CPU 分(100%)、50000 なら 0.5 CPU 分として扱われます。
この制限を超えるとプロセスはスロットリングされ、CPU を使用できなくなります。
また、cpu.shares により CPU 時間の配分割合(重み付け)を制御します。
Kubernetes の requests.cpu はここにマッピングされ、CPU リソースが競合した場合の優先度決定に使用されます。
- memory
memory.limit_in_bytes パラメータによりメモリ使用量の上限を設定します。
これを超えるとカーネルの OOM Killer が発動し、グループ内のプロセスが強制終了されます。
Kubernetes の limits.memory はここに対応します。
例えば Java アプリケーションでヒープサイズ(-Xmx)を適切に設定していない場合に、コンテナごと突然死する原因の多くはこれに起因します。
- blkio
ブロックデバイスへの I/O 帯域(IOPS / Throughput)を制限します。 特定のコンテナがディスクを占有することで他のコンテナのパフォーマンスが低下する、いわゆるノイジーネイバー問題を防ぐために利用されます。
- pids
cgroup 内で作成できるプロセス数の上限を設定します。 pids の設定は Fork Bomb(無限にプロセスを増殖させる攻撃)への対策として有効です。
cgroups v2 と Rootless Containers
Linux kernel 4.5 から導入された cgroups v2 は、cgroups v1 の階層構造の複雑さを解消し、単一の階層(Unified Hierarchy)でリソースを管理します。 これにより、より安全な Rootless Containers(一般ユーザ権限でのコンテナ実行)の実装が容易になりました。
Docker v20.10 以降や最新の Kubernetes では cgroups v2 が標準でサポートされており、セキュリティとリソース管理の精度が向上しています。
cgroup v1: change the default runtime to io.containerd.runc.v2. Requires containerd v1.3.0 or later.
3.4 Capabilities と Seccomp でセキュリティ対策
Namespace と cgroups だけでは、特権(root)プロセスが悪意を持った場合にホストへの攻撃を防ぎきれない場合があります。 そこで Capabilities と Seccomp といった Linux カーネルの機能を利用することでコンテナプロセスを脅威から保護します。
1. Capabilities:特権の分割
伝統的な UNIX では、root(UID 0)は神権限を持っていましたが、Linux では特権を細かな単位(Capability)に分割しています。
Docker はデフォルトで CAP_SYS_TIME(時刻変更)や CAP_SYS_BOOT(再起動)等の危険な権限をドロップしてコンテナを起動します。
| Capability | スコープ |
|---|---|
CAP_CHOWN | ファイル所有者の変更 |
CAP_NET_BIND_SERVICE | 1024 番以下のポートへのバインド |
CAP_SYS_ADMIN | 最も強力な権限でマウント操作やデバッグ等が可能 |
2. Seccomp:Secure Computing Mode
Seccomp は、プロセスが発行できるシステムコールをホワイトリスト形式で制限する機能になります。
Docker のデフォルトプロファイルでは、reboot や mount 等、約 44 個のシステムコールがブロックされています。
The default seccomp profile provides a sane default for running containers with seccomp and disables around 44 system calls out of 300+.
これにより、万が一コンテナ内のアプリケーションが乗っ取られても、カーネルを直接攻撃するようなシステムコール発行を阻止できるようになっています。
3. AppArmor / SELinux
ファイルパスやネットワークリソースへのアクセスを 強制アクセス制御(MAC:Mandatory Access Control) で制限します。
これにより、例えば Nginx コンテナは /etc/nginx と /var/www 以外書き込めないといったポリシを OS レベルで強制することができます。
第 4 章:Docker プラクティス
Kubernetes を知る前に、構成要素である Docker(コンテナ)の操作とプラクティスを理解する必要があります。
4.1 Dockerfile の命令と最適化
Dockerfile は、インフラ構成をコード化(IaC)するための設計図になります。 記述される各命令はそれぞれ重要な意味を持ち、適切に使い分けることで効率的で安全なイメージを作成できます。
まずは基本的な Dockerfile の構造を見てみましょう。
FROM
ベースイメージを指定します。 特に本番環境では、セキュリティリスクの低減とイメージサイズの最小化を目的として、alpine や distroless といった軽量なディストリビューションを選択するのが鉄則です。 これには OS の脆弱性を減らし、デプロイ速度を向上させる効果があります。
RUN
アプリケーションのビルドやパッケージのインストールに使用します。 この命令は実行結果を新しいレイヤとしてコミットさせます。
注意点として、apt-get update と install を別の RUN 命令に分けて記述してしまうと、予期せぬパッケージインストールエラーが発生することがあります。
これは Docker のレイヤキャッシュが効いてしまうためです。
一度ビルドされて update のレイヤがキャッシュされると、たとえ時間が経過してもキャッシュが再利用されるため、install のレイヤで参照されるパッケージインデックスが古くなってしまう(=最新のパッケージが見つからない)わけです。
また、前述した CoW の特性上、一度コミットされたレイヤのファイルは後のレイヤで削除しても容量は減りません(見えなくなるだけです)。
そのため、インストール後に不要となるキャッシュファイルの削除(rm -rf /var/lib/apt/lists/*)も含めて、全てを 1 つの RUN 行で完結させるのがベストプラクティスです。
CMD/ENTRYPOINT
コンテナ起動時のプロセスを指定します。
CMD にはデフォルトの実行コマンドを定義します。
docker run 実行時に引数を渡すと、この CMD の内容は上書きされます。
ENTRYPOINT にはコンテナ起動時に必ず実行されるコマンドを定義します。
docker run の引数は ENTRYPOINT で指定したコマンドへの引数として渡されます。
コンテナを実行ファイル(バイナリ)のように扱いたい場合や、必ず特定のラップスクリプトを通したい場合は ENTRYPOINT を活用すると便利です。
COPY/ADD
ホストマシンのファイルをコンテナ内に配置します。
COPYは単純にローカルファイルをコンテナ内にコピーします。
基本的にはこちらを使用します。
ADD はコピー機能に加え、tar ファイルの解凍や、リモート URL からのファイルダウンロード機能を持っています。
ADD は多機能ですが、意図せずアーカイブが解凍されてしまう等の予期せぬ挙動を招く恐れがあるため、明確な理由がない限りは COPY 命令を利用することが推奨されます。
WORKDIR
作業ディレクトリを変更します。
RUN cd /app のようなシェルコマンドによる移動は、その RUN 命令(レイヤ)内でしか効果が持続せず、次の命令では元のディレクトリに戻ってしまいます。
そのため、以降の命令の実行場所を永続的に変更したい場合は WORKDIR を使用してコンテキストを切り替えます。
マルチステージビルド
本番環境用のイメージには、ビルドツール(GCC, Go, Maven)は不要です。 これらを含めるとイメージサイズが肥大化し、脆弱性のリスクも増えます。
ここで、マルチステージビルド と呼ばれるビルド戦略を使うことで、ビルド環境と実行環境を分離することができます。
マルチステージビルドの過程で、数百 MB のイメージを数 MB(バイナリのみ)にまで圧縮することができます。
4.2 コンテナのライフサイクル
コンテナは「プロセス」であるため、明確なライフサイクルを持ちます。 これを理解しておくことは、コンテナを扱う上で非常に重要になります。
- Created:コンテナリソースは確保されたが、プロセスはまだ起動していない状態
- Running:プロセスが起動し、実行中の状態
- Paused:プロセスが一時停止(SIGSTOP)されている状態(メモリ状態は保持される)
- Exited(Stopped):プロセスが終了した状態(正常終了と異常終了がある)
- ※ コンテナ内のデータ(書き込みレイヤ)は明示的に
docker rmするまで残る
- ※ コンテナ内のデータ(書き込みレイヤ)は明示的に
- Dead:削除処理中等に発生する異常状態
シグナルハンドリング
docker stop コマンドを実行すると、コンテナ内の PID 1 プロセスに対して SIGTERM シグナルが送信されます。
アプリケーションはこれを受け取り、接続の切断やデータの保存等の終了処理(Graceful Shutdown)を行う猶予が与えられます。
指定期間内に終了しない場合、次に Docker Daemon もしくはコンテナのランタイムから送信される SIGKILL によってコンテナは強制終了されます。
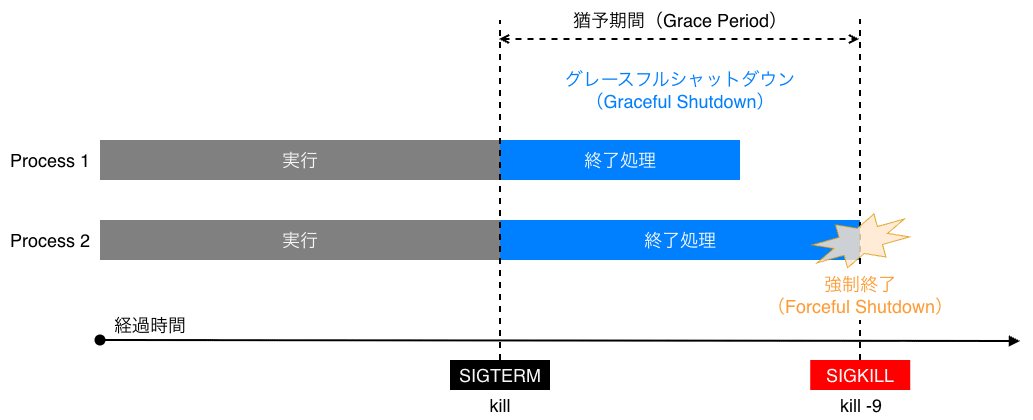
【注意】
Shell Script を ENTRYPOINT にしている場合、exec を使わずにサブプロセスとしてアプリケーションを起動すると、シグナルがアプリケーションに伝播せず、常に強制終了(SIGKILL)待ちになってしまう問題が発生します。
このため Shell Script 内でアプリケーションを起動する際は、必ず exec コマンドを通じて、シェルプロセスをアプリケーションプロセスに置き換える(PID 1 を引き継がせる)必要があります。
4.3 Docker ネットワークの内部実装
例えば、Web サーバを立ち上げたい場合、Docker なら以下のコマンドを実行するだけで完了します。
これだけで、ブラウザから http://localhost にアクセスすると Nginx の画面が表示されます。
しかし、よく考えてみるとこれは不思議なことです。 コンテナは隔離された環境のはずなのに、なぜホストマシンから、いとも簡単にコンテナ内の Web サーバに通信が届くのでしょうか。
実は、この仕組みの裏側では、Linux カーネルが持つ複数のネットワーク機能が複雑に連携しています。
Bridge ネットワーク
Docker のネットワークにおいて、最も基本となり、かつデフォルトで使用されるのが Bridge と呼ばれるネットワークドライバです。
これは、ホストマシンの中に L2 スイッチングハブのような機能をエミュレーションし、そこに各コンテナを接続するようなイメージで実装されています。 この仕組みにより、隔離されたコンテナ同士が通信したり、ホストマシンの外の世界とデータをやり取りしたりすることが可能になります。
具体的にどのようなコンポーネントが関わっているのか、図と共にその構成要素を見てみます。
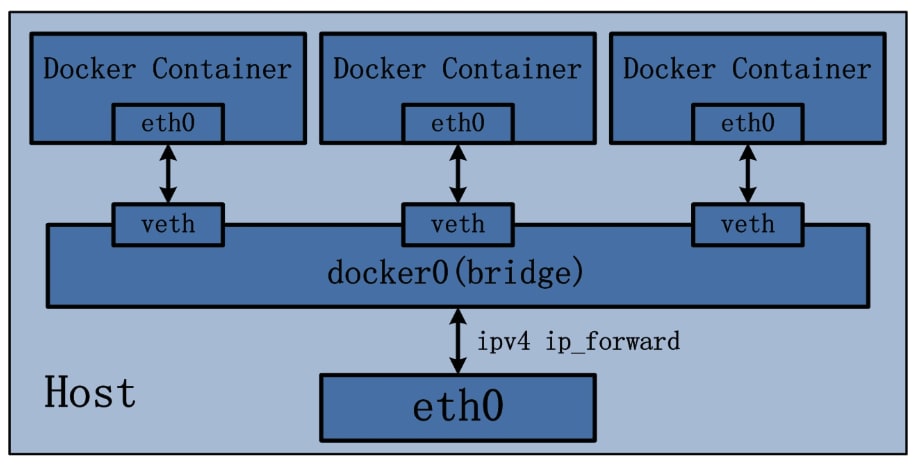
-
仮想ブリッジ(
docker0)- Docker Daemon 起動時に、ホスト上に
docker0という仮想スイッチ(L2 ブリッジ)が作成される - デフォルトで
172.17.0.1/16のような IP が割り当てられる
- Docker Daemon 起動時に、ホスト上に
-
veth(Virtual Ethernet)ペア
- コンテナを起動すると、
vethペアと呼ばれる仮想的な LAN ケーブルが作成される - 片方(
eth0)はコンテナ内の Network Namespace に配置され、もう片方(vethXXXX)はホスト側のdocker0ブリッジに接続される
- コンテナを起動すると、
-
iptables による NAPT
- コンテナから外部への通信(Outbound)は、IP マスカレードによってホストの IP アドレスに変換される(iptables における
POSTROUTINGChain) - 外部からコンテナへの通信(Inbound や ポートフォワーディング)は、DNAT(Destination NAT)によってコンテナの IP アドレスに変換される(iptables における
PREROUTINGChain)
- コンテナから外部への通信(Outbound)は、IP マスカレードによってホストの IP アドレスに変換される(iptables における
その他のネットワークドライバ
- Host
コンテナ独自のネットワーク空間(Network Namespace)を作成せず、ホストマシンのネットワークをそのまま利用します。 Host 指定では、特段の隔離は行わないため非常に高速です。
一方で、80 番をはじめとする Well-Known なポート番号の場合、ホスト上の他のプロセスと競合する可能性があります。
- None
None 指定では、ループバック(lo)以外のインターフェースを持ちません。
完全なオフライン処理を行う場合に使用します。
- Macvlan
コンテナに物理ネットワーク上の MAC アドレスを直接割り当てます。 Macvlan では、DHCP でホストマシンが所属する LAN の IP を直接持たせたい場合等、コンテナに割り当てる IP アドレスを別の機構で管理したい際に使用します。
4.4 データの永続化と Volume の種類
コンテナは 使い捨てが基本 です。
コンテナを削除すると CoW レイヤ(UpperDir)にあるデータは全て消滅します。 データベースのファイルやログ等、永続化が必要なデータには以下のマウントタイプを使い分けます。
1. Volumes
Docker が管理する専用領域(Linux では /var/lib/docker/volumes)にデータを保存します。
-
メリット
- ホストのディレクトリ構造や OS の違い(Windows / Mac / Linux)を隠蔽できる
- 複数のコンテナ間で安全に共有できる
- ボリュームドライバを使用することで、データを S3 や NFS 等のリモートストレージに保存することもできる
-
使用例
2. Bind Mounts
ホスト側のファイルシステムの任意のパスを、コンテナ内に直接マウントします。
-
メリット
- ホスト上のソースコードをエディタで編集し、その変更をコンテナ内に即座に反映させることができる
-
デメリット
- ホストのパス構造に依存するため可搬性が下がる
- Docker Desktop for Mac / Windows では OS 間のファイルシステムブリッジを通るため、ディスク I/O が極端に遅くなる場合がある
-
使用例
3. tmpfs Mounts
ディスクではなく、ホストのメモリ領域をマウントします。
- 用途
- ディスク I/O を発生させたくない高速なキャッシュ領域
- シークレット情報等、ディスクに残したくないデータの一時保存
第 5 章:なぜ Kubernetes が必要なのか
ここまで Docker の基本を見てきましたが、本番環境では コンテナをどのように管理し、稼働させ続けるかという課題 があります。 例えば、コンテナがダウンした場合、別のコンテナを即座に起動する必要があります。 このような振る舞いがシステムによって自動的に処理されれば、運用は劇的に楽になるはずです。
そこで登場するのが今回の本題となる Kubernetes です。
5.1 Docker だけでは解決できない運用の壁
Docker はアプリケーションをコンテナにパッケージングして起動することに関しては非常に特化されたツールです。
一方で、本番環境において実際にリクエストを処理することを想定すると、以下のような課題が生じてきます。
- 単一障害点(SPOF:Single Point of Failure):Docker は通常 1 台のサーバ上で動くため、そのサーバがダウンすれば全サービスが停止する。
- スケーリングの限界:単一サーバのコンピュートリソースには物理的な限界がある。
- デプロイのダウンタイム:コンテナを更新する際、手動で再起動を行うと一時的にサービスが停止する。
- 自己修復(セルフヒーリング)の欠如:アプリケーションがエラーで停止した際、自動的に再起動したり、健全な状態に戻したりする仕組みがない。
5.2 Kubernetes が提供する機能
Kubernetes は、複数のコンピュートリソース(ノード)を束ね、その上でコンテナを継続的かつリソース効率的に動かし続けるための基盤です。 具体的には、以下のような機能を包括的に提供することで、Docker 単体では成し得なかった高度な管理を自動化します。
1. Service discovery and load balancing:サービスディスカバリと負荷分散
- 複数のコンテナに対して、単一のアクセス窓口(IP アドレスや DNS 名)を提供する
- 特定のコンテナへのアクセスが集中した場合、自動的にトラフィックを分散させ、システム全体の安定性・負荷バランスを保つ
2. Storage orchestration:ストレージオーケストレーション
- コンテナが必要とするデータ保存領域(ローカルディスクやクラウドのストレージ)を、自動的にマウントして使えるようにする
3. Automated rollouts and rollbacks:ロールアウトとロールバックの自動化
- 「アプリケーションを v1 から v2 に更新したい」と宣言するだけで、古いコンテナを少しずつ新しいコンテナに入れ替えるローリングアップデートが標準で提供されている
- 万が一、新しいバージョンに不具合があった場合は、自動的に元のバージョンに戻す(ロールバック)こともできる
4. Automatic bin packing:自動ビンパッキング
- 「このコンテナは CPU をこれくらい使う」と指定すると Kubernetes がクラスタ内の空いている場所を自動的に探し出し、最適なノードに配置する
- これにより、サーバリソースを無駄なく使い切ることができる
5. Self-healing:自己修復
- コンテナがクラッシュしたり、応答しなくなったりした場合、自動的に再起動して復旧を試みる
- 正常に動いていると確認できるまでは、そのコンテナにユーザからのアクセスを流さないように制御する
6. Secret and configuration management:シークレットと構成管理
- パスワードや API キーといった機密情報(Secret)や設定ファイル(ConfigMap)を、コンテナイメージから切り出して管理できる
- これにより、セキュリティを高めつつ、設定変更の度にイメージを作り直すトイルが削減できる
7. Batch execution:バッチ実行
- Web サービスのような常駐型プロセスだけでなく、データ集計や機械学習ジョブのような、完了したら終了するバッチ処理(Job / CronJob)を管理できる
8. Horizontal scaling:水平スケーリング
- CPU 使用率等、コンピュートリソースの負荷に応じて、自動的にコンテナの数(レプリカ数)を増減させるオートスケーリングができる
9. IPv4/IPv6 dual-stack:IPv4/IPv6 デュアルスタック
- Pod や Service と呼ばれる Kubernetes のリソースに対して IPv4 / IPv6 の両方のアドレスを割り当てることができる
10. Designed for extensibility:拡張性を考慮した設計
- アップストリームのソースコードを変更することなく、独自の機能(カスタムリソースやコントローラ)を追加してクラスタの仕様を自由に拡張できる
Kubernetes が革新的たる所以
これらは Kubernetes の最も基本的な機能に過ぎませんが、従来の VM 運用と比較すると、革新的であることが分かるかと思います。
運用の自動化
かつての運用では、サーバが 1 台故障すると、エンジニアが夜中に緊急対応を行い、代替サーバの手配、OS のインストール、設定、アプリケーションの再デプロイまでを手動で行う必要がありました。 サーバ一台一台に対してホスト名を付け、個別にメンテナンスを行うこの方法は、管理台数が増えれば増えるほど破綻していきます。
それに対して Kubernetes では、個々のサーバやコンテナを、いつでも交換可能なパーツとして扱います。 例えば「Web サーバのコンテナを常に 3 つ動かしておきたい」と設定しておけば、そのうちの 1 つが物理的な故障で消えても、Kubernetes 自体が即座に検知し、自動的に別の正常なサーバ上で新しいコンテナを起動して「3 つある状態」を復旧させます。 人間が介入することなく、システム自身が状態を維持し続けるため、運用コストを劇的に下げることができます。
リソース・コスト効率性
リソース利用効率の観点でも大きなメリットがあります。 従来はアプリケーション毎に専用の VM を用意するのが一般的でしたが、これでは各 VM の CPU やメモリに無駄が生まれがちです。 Kubernetes は、複数の物理サーバを 1 つの巨大なリソースプールとして扱い、その中にコンテナを高密度に詰め込んで実行します(Bin Packing によるもの)。 これにより、必要なハードウェア台数を削減し、インフラコストを大幅に圧縮・削減することが可能になります。
DevOps の実現
Kubernetes は単なるコンテナ管理ツールではありません。 コンテナ単体では解決できない「ネットワーク接続」「データ保存」「外部公開」といった複雑なインフラ設定もまとめて抽象化します。 これにより、インフラエンジニアとアプリケーションエンジニアの境界線が再定義 され、開発速度と運用安定性を両立する DevOps の実現を後押ししてくれます。
5.3 Kubernetes は PaaS ではない
PaaS(Platform as a Service) はソースコードさえあればアプリケーションを動かせる便利なサービスですが、その便利さの裏にはプラットフォーム側が用意したルールに従わなければならないという制約があります。
Kubernetes は、これらとは一線を画します。 Kubernetes はあくまでコンテナを動かすための土台であり、その上で何を使うかはユーザの裁量に委ねられています。
言語やフレームワークの制限がない
- コンテナ化さえできれば、どんな言語(Go, Rust, Python, Node.js, etc...)でも、どんな種類のアプリケーション(Web サーバ、バッチ処理、データベース...)でも動作する
CI/CD パイプラインを強制しない
- ソースコードをどうやってビルドし、どうやってデプロイするかは開発者の自由
- GitHub Actions, CircleCI, ArgoCD 等、ユーザが選択したツールを組み合わせることができる
「全部入り」ではない
- データベース、メッセージキュー、監視ツール、ログ収集基盤等は標準では含まれていない
- 代わりに、エコシステム(Ecosystem) が充実しており、ユーザが選択したミドルウェアを自由に追加できる Add-on の思想に則っている
Kubernetes はあえて機能を最小限に絞り込み、ユーザが独自のツールやミドルウェアを自由に組み合わせられるように設計されています。 従って、完成された環境を提供する PaaS とは異なり、Kubernetes はインフラを構成するツールを自由に選択し、それら組み合わせることができるという特徴があります。
この点については Kubernetes 公式にも明確に「What Kubernetes is not」セクションで言及されています。
Kubernetes is not a traditional, all-inclusive PaaS (Platform as a Service) system.
この拡張性と自由度の高さこそが、Kubernetes が世界中でデファクトスタンダードとして支持される最大の理由だと思っています。
また、インフラを抽象化しつつ、PaaS ほど制約を課さないという絶妙な立ち位置から、Kubernetes は KaaS(Kubernetes as a Service) と言われたりもします。 OS がハードウェアの違いを吸収してアプリケーションに共通のインターフェースを提供するのと同様に、Kubernetes はプラットフォーム毎の違いを吸収し、どこでも同じようにコンテナを動かせる「クラウド時代の OS」 として機能します。 この点、Kubernetes は「次世代 Linux」と比喩されることもあります。
第 6 章:Kubernetes のアーキテクチャ
Kubernetes のアーキテクチャを理解するためには、まず クラスタ(Cluster) という概念を理解する必要があります。 クラスタとは複数のコンピュータ(サーバ)をネットワークで接続し、あたかも 1 つの巨大なコンピュータのように振る舞わせるシステムのことです。
Kubernetes クラスタは、大きく分けて 2 種類の役割を持つノード群で構成される マスター・ワーカー構成 をとっています。
また、Kubernetes の最大の特徴の一つに 宣言的 API(Declarative API) という設計思想があります。 従来のシステム管理が「何を・どうするか」という手順(命令)を指示するのに対し、Kubernetes では「最終的にどうなっていてほしいか」という あるべき状態 のみを宣言 します。
具体的には、マニフェスト と呼ばれる YAML 形式の設定ファイルを API サーバに送信することで制御します。 ユーザが「コンテナを 3 つ動かしたい」とマニフェストで宣言すると、Kubernetes は現在の状態(0 個)とあるべき状態(3 個)のズレ(Diff)を検知し、自動的にコンテナを起動して差異を解消します。
この仕組みにより、ユーザは複雑な復旧手順を意識することなく、システムの管理を行うことができます。 これを Kubernetes では Reconciliation Loop(調整ループ) と呼びます。
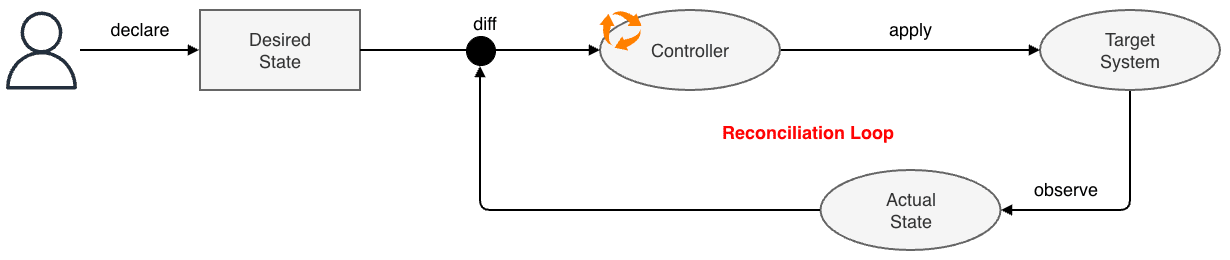
6.1 Kubernetes の全体像
以下の図は Kubernetes の全体像をざっくりと示したものです。
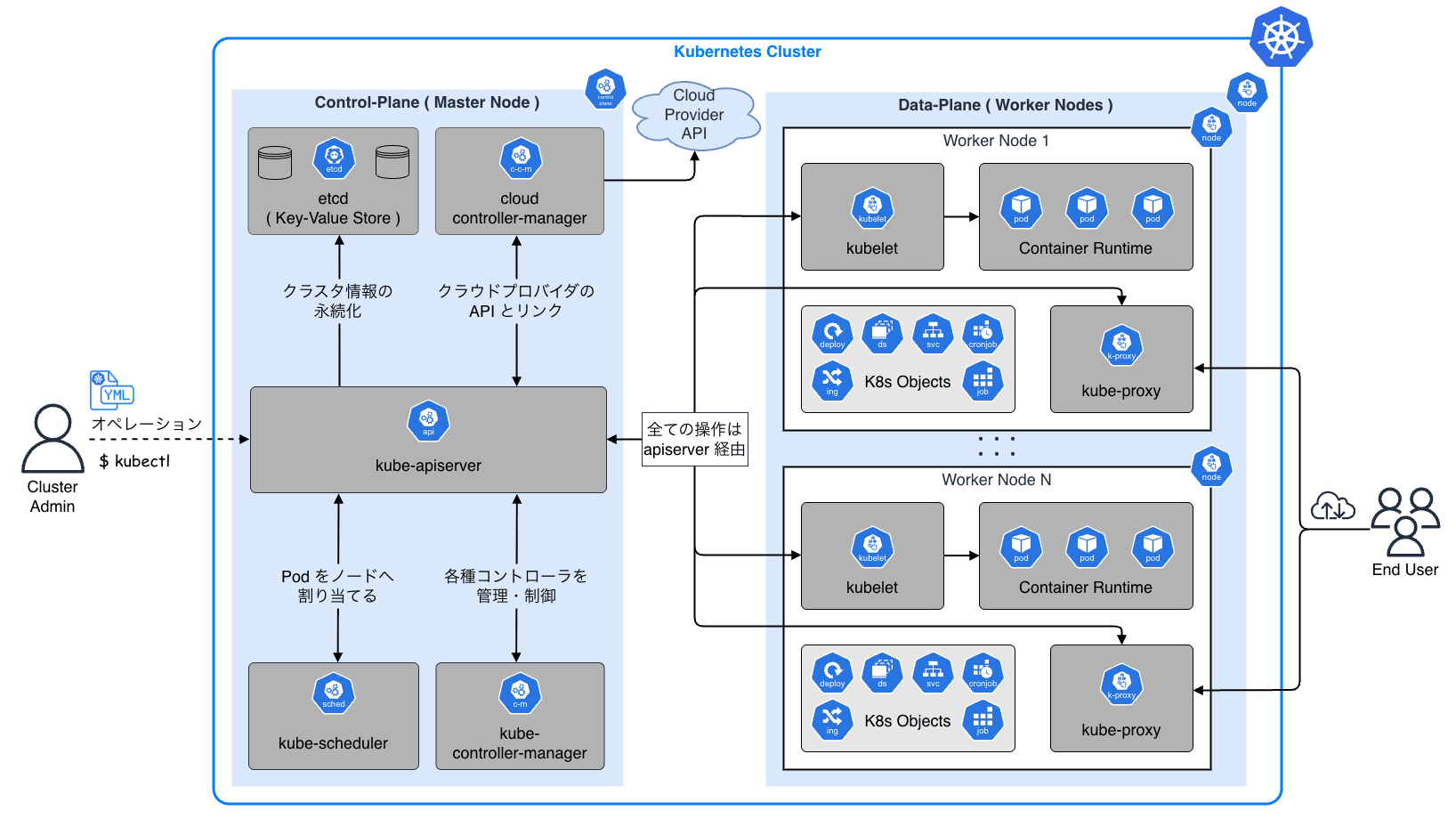
Kubernetes ではクラスタ上で動かすアプリケーションを Pod と呼ばれる単位(1 つ以上のコンテナの集まり)で扱います。

Docker ではコンテナ単体を管理していましたが、Kubernetes では Pod を最小単位としてデプロイ・管理 を行います。 つまり、「コンテナをデプロイする」とは「Pod を作成する」ことを意味します。
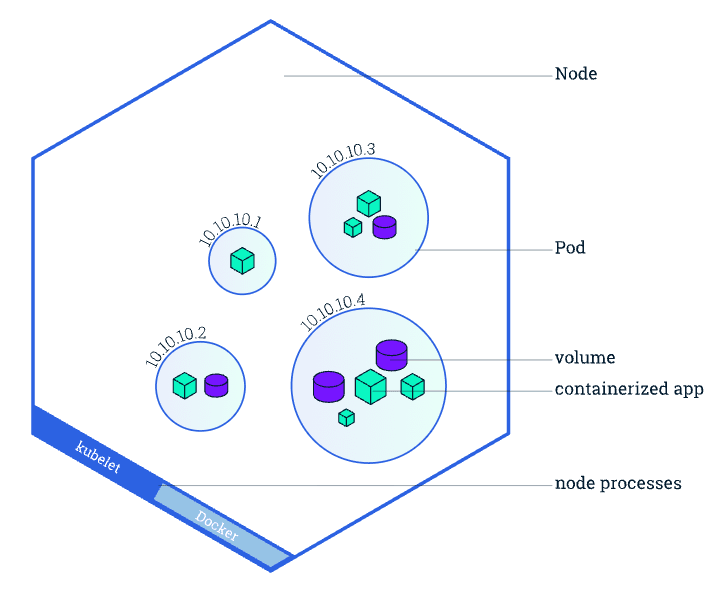
Control-Plane
Control-Plane はマスターノードとも呼ばれ、主にクラスタの「脳」に相当します。 「どの Pod をどこで動かすか」「今、システムはどういう状態にあるべきか」といった意思決定や管理を一手に引き受けます。 管理者がコマンド(マニフェスト)を送る相手も、この Control-Plane になります。
Data-Plane
Data-Plane はワーカーノード(単にノードと呼ぶこともある)とも呼ばれ、クラスタの「手足」に相当します。 Data-Plane は Control-Plane からの命令を受け取り、実際にコンテナ化されたアプリケーション(ワークロード)を稼働させる実行部隊です。
ユーザは、Control-Plane に対して「Web サーバを 3 つ動かして」と宣言するだけで、後は Kubernetes が自動的に空いているワーカーノードを探し出してコンテナを配置してくれます。 ユーザは、実際にどのサーバでコンテナが動いているかを意識する必要はありません。 これが、所謂 Kubernetes によるインフラの抽象化です。
これらの Control-Plane や Data-Plane のコンポーネント自体も Pod として Kubernetes クラスタ自身にデプロイされています。 つまり、Kubernetes は Kubernetes で自分自身を管理する再帰的な構造 を持っています。
それでは、 Control-Plane および Data-Plane の各コンポーネントの役割について具体的に見ていきます。
6.2 Control-Plane:マスターノード
Control-Plane コンポーネントはクラスタに関する全体的な決定(スケジューリング)を行い、新しいワークロードの作成やノードの障害といったクラスタイベントの検出および応答を行います。
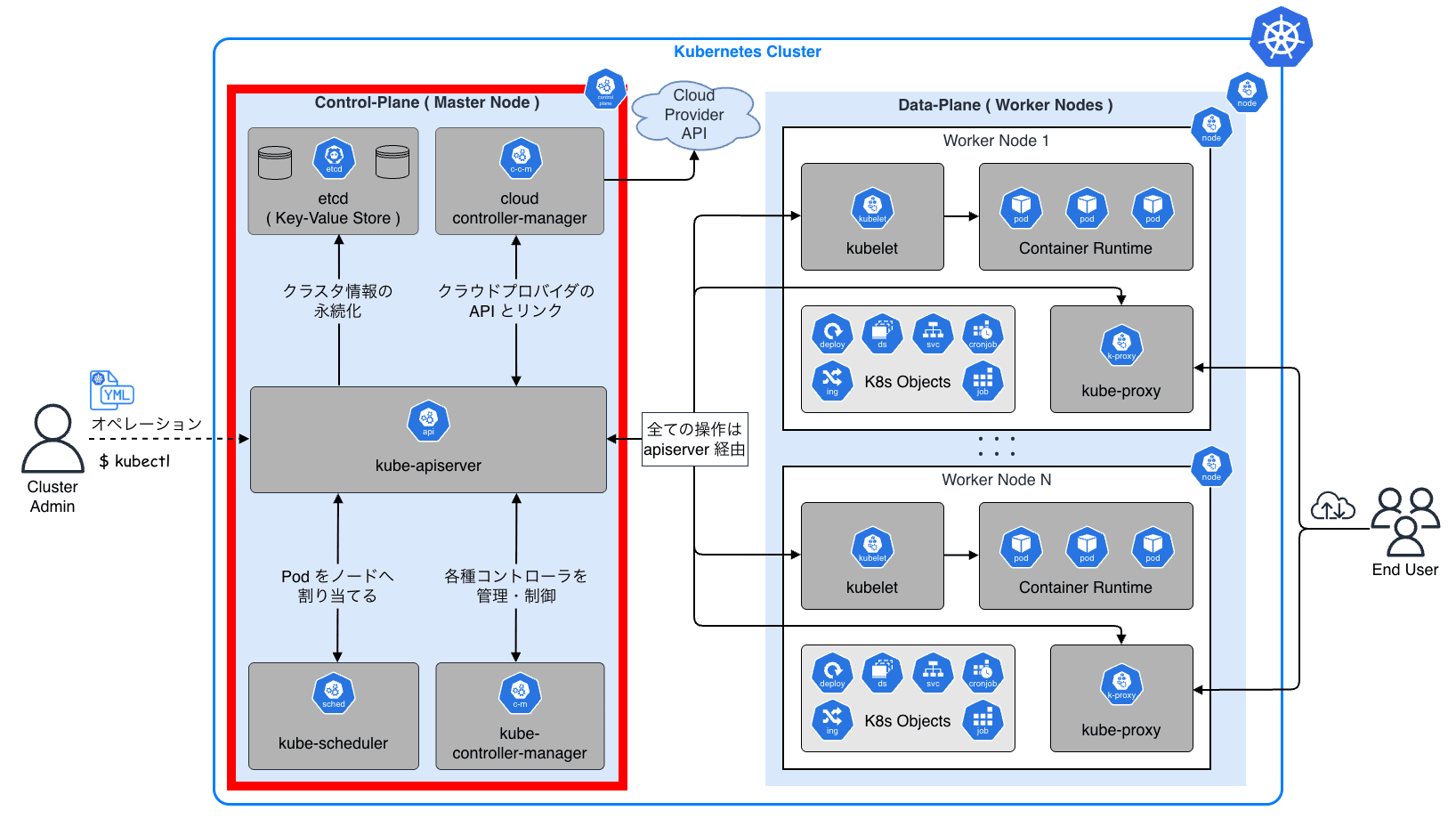
| コンポーネント | 役割・機能 |
|---|---|
| kube-apiserver | 所謂 Control-Plane のフロントエンドで、全ての認証・認可、API リクエストを処理する |
| etcd | クラスタの全てのデータを保存する分散 KVS(Key-Value Store) |
| kube-scheduler | 新規 Pod を適切なワーカーノードに割り当てる(スケジューリング) |
| kube-controller-manager | ノードやレプリケーション、エンドポイント等のコントローラを実行する |
| cloud-controller-manager | 各種クラウドプロバイダ(AWS / Google Cloud 等)の API と連携する |
kube-apiserver

kube-apiserver は、Control-Plane のフロントエンドとして機能し、水平スケール可能なコンポーネントです。 後述するすべてのコンポーネントは、互いに直接通信することはなく、必ず API サーバを経由して情報を交換します。
API リクエスト(例:POST /api/v1/namespaces/default/pods)は、一連のフィルタチェインを通過して処理されます。
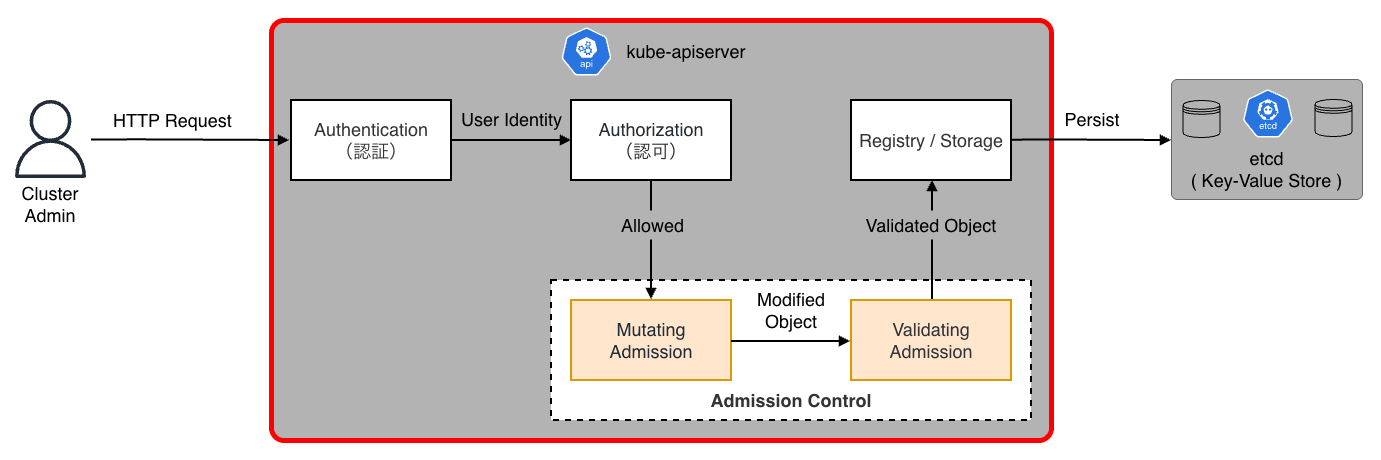
- 認証(Authentication)
- リクエストの送信者が誰であるかを特定する
- X.509 クライアント証明書:双方向 TLS 認証
- Bearer Token:ServiceAccount トークンや OIDC トークン
- Bootstrap Token:ノード参加時の初期認証用
- 認可(Authorization)
- 特定されたユーザが、その操作を行う権限を持っているかを確認する
- RBAC(Role-Based Access Control):ロールとバインディングに基づく標準的な認可
- ABAC(Attribute-Based Access Control):ポリシファイルに基づく認可
- Node Authorization:kubelet(※後述)からのアクセスを自身のノードに関連するリソースのみに制限
- Webhook:外部の認可サービスへのデリゲーション
- Admission Control
- 認証・認可を通過した後、オブジェクトの永続化直前に実行される「変更(Mutating)」および「検証(Validating)」のフック
- Mutating Admission:リクエスト内容を書き換える(例:
Sidecar Injection、DefaultStorageClass、ServiceAccountの自動付与) - Validating Admission:リクエスト内容を検証し、違反があれば拒否する(例:
LimitRangerによるリソース制限チェック、PodSecurityポリシ) - これらは Webhook として外部サーバ(OPA Gatekeeper や Kyverno 等)にデリゲーションすることが可能
etcd

etcd は、一貫性、高可用性を持つ分散 KVS(Key-Value Store)で、Kubernetes クラスタ内のすべての情報を管理します。 クラスタの状態(どのノードにどの Pod がいるかや、現在の設定等)はすべてここに永続化されます。
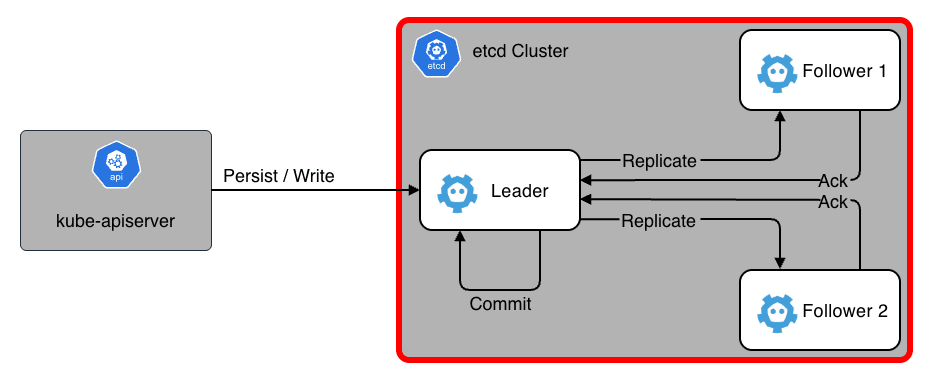
- Raft
- 分散合意アルゴリズムとして Raft を採用しており、過半数のノードが生存していれば書き込み可能
- このため、etcd クラスタは奇数台(3 台または 5 台)で構成するのが一般的
- 監視機構
- キーの変更をリアルタイムで通知する機能があり、これが Kubernetes の「宣言的 API」を支える根幹となっている
- バックアップの重要性
- etcd のデータが失われるとクラスタは復旧できなくなる
- 定期的なスナップショット取得が運用上の最重要課題
kube-scheduler

kube-scheduler は、新しく作成された Pod(まだノードが割り当てられていない Pod)を監視し、実行すべき最適なワーカーノードを選択します。
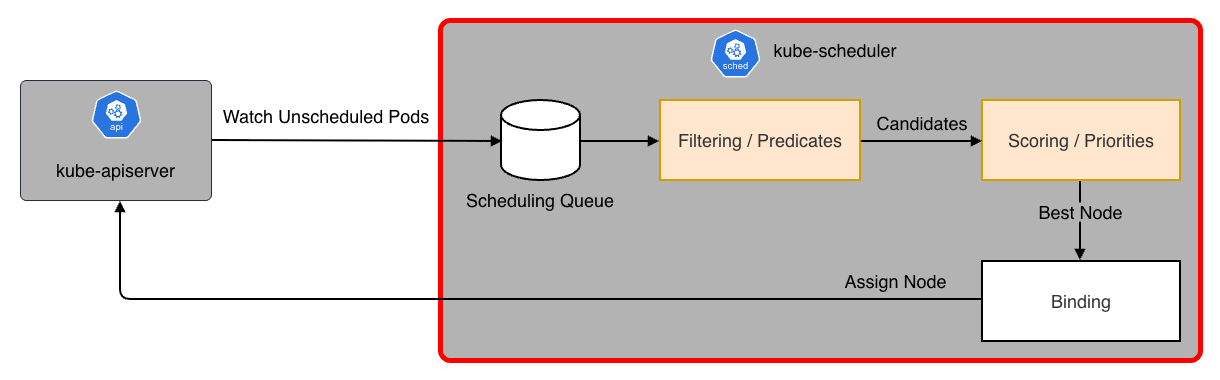
スケジューリングは主に 2 つのフェーズで行われます。
- フィルタリング(Filtering / Predicates)
- 「この Pod を実行できないノード」を除外
- 例:CPU/メモリの空き容量不足、Taints/Tolerations の不一致、NodeSelector の不一致
- スコアリング(Scoring / Priorities)
- フィルタリングを通過したノードに点数を付け、最も高得点のノードを選びます。
- 例:イメージが既にキャッシュされているノード(起動が速い)、負荷が低いノード、同じサービスの Pod が分散されているか(Anti-Affinity)
kube-controller-manager

kube-controller-manager は、Control-Plane における他のコンポーネントの管理及び制御を行います。 論理的には、各コントローラは個別のプロセスとして動作しますが、複雑さの観点から一つの実行ファイルにまとめてコンパイルされ、単一のプロセスとして稼働します。
コントローラは現在の状態(Current State)を常に監視しており、あるべき状態(Desired State)に近づけるために以下のコントローラを制御します。
- Node Controller
- ノードがダウンしたことを検知して対応
- Replication Controller
- Pod の数が指定したレプリカ数と一致しているかを監視
- 足りなければ作成し、多すぎれば削除する
- Endpoint Controller
- Service と Pod を紐付ける Endpoints オブジェクトを生成する
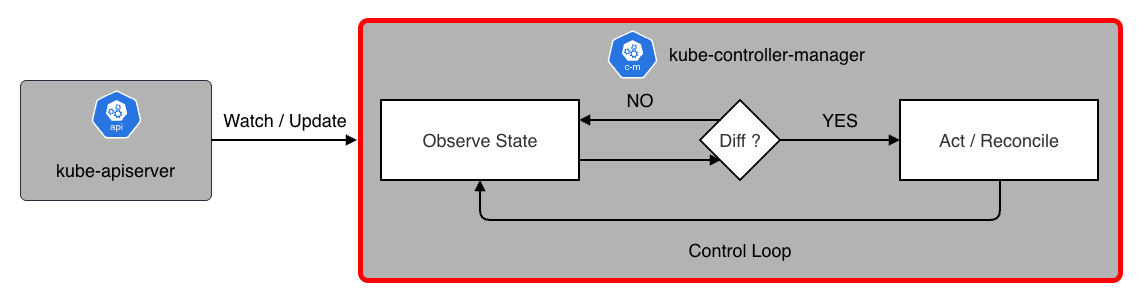
Kubernetes のコントローラは、API サーバにポーリングして変更を確認するという単純な実装ではありません。 それでは数千の Pod がある環境で API サーバがパンクしてしまいます。
この問題を回避するために、kube-controller-manager では Informer パターン と呼ばれる高度なキャッシュ機構を利用しています。
- List & Watch
- 最初に一度だけリソース一覧を取得(List)
- その後は、変更イベント(Added, Updated, Delete)だけをストリームで受け取る(Watch)
- Local Store(Cache)
- 受け取ったイベントを元に、手元のメモリ内キャッシュを更新
- コントローラが「現在の Pod の状態」を知りたい時は、API サーバではなくこのメモリキャッシュを参照する
- これにより API アクセスを削減する
- Workqueue
- イベントが発生すると、対象のリソースのキー(
namespace/name)をキューに格納 - 複数のワーカープロセスがこのキューからキーを取り出して Reconcile 処理を実行する
- イベントが発生すると、対象のリソースのキー(
cloud-controller-manager

cloud-controller-manager は、パブリッククラウドのマネージドサービスを接続するための制御コンポーネントです。
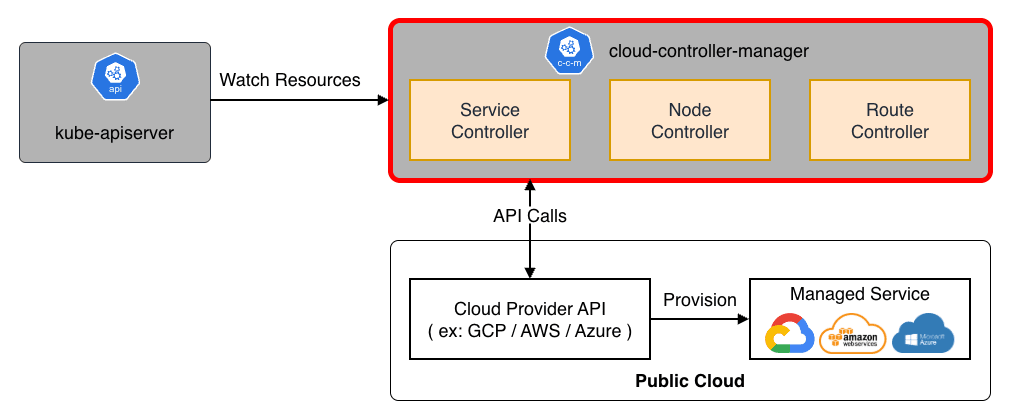
クラスタをクラウドプロバイダの API とリンクし、クラスタのみで相互作用するコンポーネントからクラウドプラットフォームで相互作用するコンポーネントを分離する役割を担います。 例えば、AWS の ELB(Load Balancer) を作成したり、EBS(Persistent Disk) をマウントしたりする際に、このコンポーネントがクラウド側の API を叩きます。
なお、cloud-controller-manager は、その名の通りクラウドプロバイダと連携するためのコンポーネントです。 従って kind、minikube といった学習用のローカル環境、kubeadm や Rancher 等で構築した素の Kubernetes では必須ではありません。
6.3 Data-Plane:ワーカーノード
Data-Plane は、実際にワークロードが稼働するワーカーノード上のコンポーネント群です。
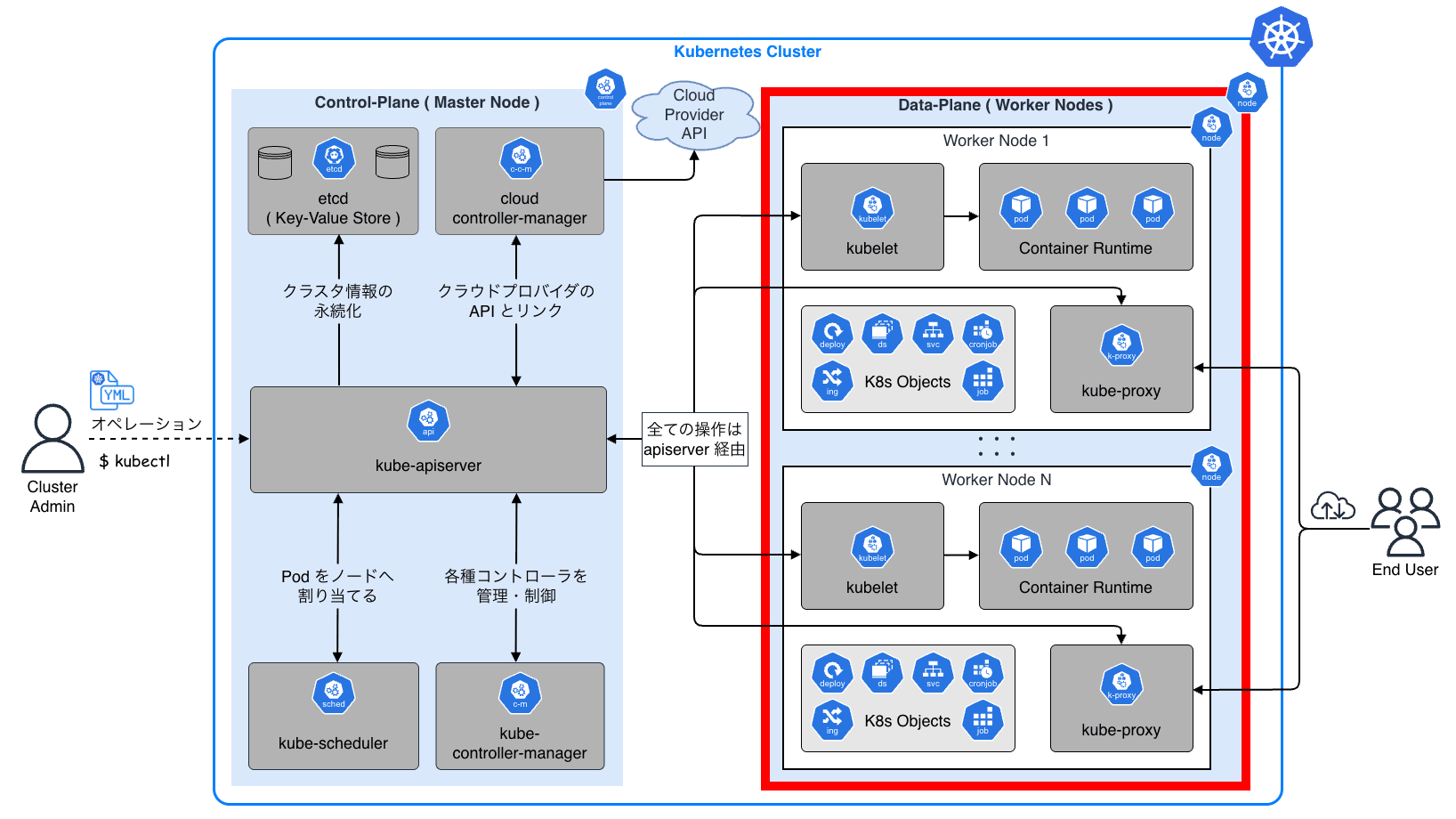
| コンポーネント | 役割・機能 |
|---|---|
| kubelet | 各ノード上で Pod(コンテナ)の起動・監視・管理を行うエージェント |
| kube-proxy | 通信を制御するネットワークプロキシ |
| Container Runtime | コンテナを実行するソフトウェア(containerd / CRI-O 等) |
kubelet

kubelet は、各ノードで動作するエージェントで、Pod のスペック(設定情報)に基づいてコンテナを実行・維持する責務を持ちます。
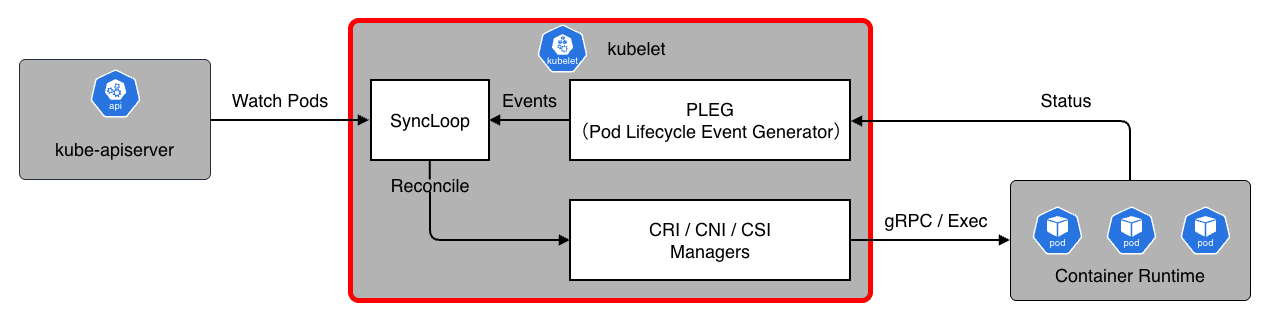
CRI(Container Runtime Interface)
gRPC を通じて containerd や CRI-O 等の高レベルランタイムと通信し、コンテナのライフサイクルを操作します。
CNI(Container Network Interface)
ネットワークプラグインを呼び出し、Pod への IP アドレス割り当てやネットワーク設定を行います。
CSI(Container Storage Interface)
ストレージボリュームをマウント・アンマウントします。
PLEG(Pod Lifecycle Event Generator)
コンテナランタイムの状態を定期的にポーリングまたはストリーミングして状態変化をイベントとして生成します。
SyncLoop
PLEG からのイベント、API サーバからの更新、定期的なタイマ等をトリガに、SyncPod と呼ばれる kubelet の中心的な調整関数(メソッド)を実行します。 ここで「あるべき状態」と「現在のコンテナの状態」を比較し、コンテナの作成・再起動・削除等の操作を行います。
Static Pods
通常、Pod は API サーバ経由で作成されますが、kubelet は特定のディレクトリ(デフォルト /etc/kubernetes/manifests)にある YAML ファイルを監視し、そこから直接 Pod を起動することもできます。
これを、通常の Pod とは区別して Static Pod と呼びます。
前述した Control-Plane コンポーネントのうち、etcd、kube-apiserver、kube-controller-manager、kube-scheduler の 4 つは Static Pod として起動 されます。
kube-proxy

kube-proxy は Service と呼ばれる仮想 IP へのトラフィックを、バックエンドの Pod IP へ転送する役割を担い L4(TCP/UDP)のプロキシとして動作します。
ここで、Service とは、複数の Pod に対する単一のアクセス窓口(IP アドレスや DNS 名)を提供する抽象的なリソースです。 Pod は作成・削除される度に IP アドレスが変わってしまいますが、Service を経由することで、クライアントは固定の IP アドレスで安定してアクセスできるようになります。 なお、Service の詳細な種類や仕組みについては 実践編 で紹介しています。
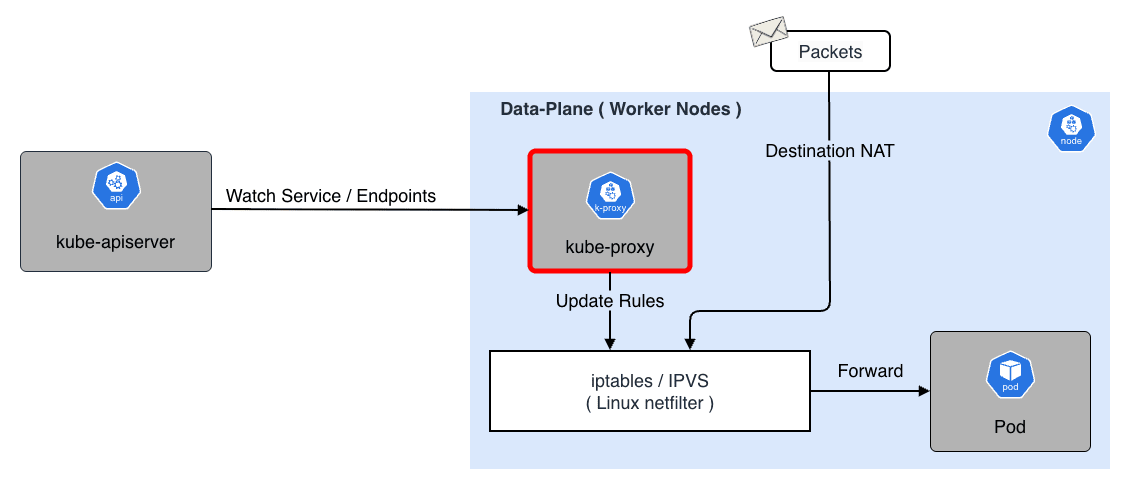
kube-proxy には以下 3 つのプロキシモードがあります。
User space mode(Legacy)
- パケットを一度ユーザ空間の kube-proxy プロセスに渡し、そこから再送信する
- コンテキストスイッチのオーバーヘッドが大きく、現在はほとんど使われていない
iptables mode(Default)
- Linux カーネルの netfilter 機能を使ってパケット処理をすべてカーネル空間で完結させる
- Service 毎に多数の iptables ルールを作成する
- のアルゴリズムとなっているため Service が数千〜数万になると、ルールの更新および再適用に時間がかかり CPU 負荷が増加する
IPVS(IP Virtual Server)mode
- LVS(Linux Virtual Server) と呼ばれるカーネル組み込みのロードバランシング機能を利用する
- 内部データ構造にハッシュテーブルを使用するため、 の計算量で高速にパケットを処理できる
- ラウンドロビンがデフォルトとなっているが、他にも最小コネクション(Least Connection)や 重み付け(Weighted)といった高度な分散アルゴリズムを利用できる
- 大規模クラスタでは通常 IPVS モードを利用することが推奨される
Container Runtime


Container Runtime は、ノード上でコンテナイメージを取得・展開し、実際に実行する責任を持つソフトウェアです。 Docker も内部的には containerd というランタイムを使用しています。
一方、Kubernetes では、これらのランタイムを Kubernetes 自体が直接操作することはなく、前述した CRI という統一されたインターフェースを介して操作します。 これにより、ユーザは containerd や CRI-O 等、要件に合わせたランタイムを自由に選択・交換することができます。

containerd
- Docker から切り出された業界標準のランタイム
- イメージの Pull、展開、コンテナプロセスの管理(runc の呼び出し)を担当します
- Kubernetes は cri-containerd プラグインを通じて containerd を操作します。
runc(OCI Runtime)
- 実際にカーネルの機能(Namespace / cgroups)を叩いてコンテナプロセス(サンドボックス)を作成する低レベルランタイム
- containerd の下で動作する
RuntimeClass
- セキュリティ要件の高い Pod に対して、gVisor(runsc) や Kata Containers といった、より隔離性の高いランタイムを指定して実行することが可能
まとめ
本記事では、コンテナ技術の歴史的背景から Docker の内部アーキテクチャ、そして現代のインフラ標準となった Kubernetes の設計思想までを網羅的に紹介しました。
コンテナの本質は、Namespace や cgroups といった Linux カーネルのプリミティブな機能を組み合わせた隔離技術にあります。 そして Kubernetes は、それらを「宣言的 API」と「Reconciliation Loop」という強力な機構で管理することで、大規模な分散システムを自律的に運用可能にするプラットフォームです。
インフラの複雑性を抽象化し、開発者が「どう動かしたいか」に集中できる環境を提供する Kubernetes は、まさに「クラウド時代の OS」と言えるでしょう。
続く 実践編 では、Pod ライフサイクルの詳細、ネットワーク・ストレージへの Deep Dive、そして実用的なクラスタ構築手順等、現場で役立つ内容について紹介しています。
参考・引用

Kubernetes完全ガイド【電子書籍】
詳細を見る
Kubernetes完全ガイド 第2版
詳細を見る
みんなのDocker/Kubernetes【電子書籍】
詳細を見る
Docker/Kubernetes開発・運用のためのセキュリティ実践ガイド
詳細を見る
Kubernetes実践入門
詳細を見る
Linuxカーネル2.6解読室
詳細を見る