コンテナ仮想化技術と Kubernetes の俯瞰図 - 実践編
はじめに
コンテナ仮想化技術と Kubernetes の俯瞰図 - 基礎編 では、コンテナ技術の歴史的背景から Docker の内部アーキテクチャ、そして Kubernetes の設計思想や各コンポーネントの役割について紹介しました。
Kubernetes は、「宣言的 API」や「Reconciliation Loop」といった仕組みによって大規模な分散システムを自律的に運用可能にするプラットフォームでした。
Kubernetes の基本的な仕組みについて理解したところで、本記事では実際に Kubernetes を運用する上で必要となる具体的なプラクティスを紹介したいと思います。
第 1 章:Pod の詳細とマニフェストの構造
Kubernetes を操作する上で最も基本的かつ重要なのが「マニフェストファイル」と「Pod」の理解です。 本章では、Pod のリソース管理やライフサイクルの内部挙動について紹介します。
1.1 マニフェストファイルの構造
Kubernetes では マニフェスト と呼ばれる「あるべき状態(Desired State)」が書かれた YAML 形式のファイルを kubectl コマンドによってクラスタに適用することで、リソースを宣言的に管理します。
全てのリソースに共通する 4 つの主要なフィールドがあります。
- apiVersion
- リソースのバージョン(例:
v1,apps/v1) - API の進化に伴って変更される
- kind
- リソースの種類(例:
Pod,Service,Deployment)
- metadata
- リソースを特定するための情報
name:リソースの名前(Namespace 内で一意である必要がある)namespace:リソースが所属する名前空間(省略時はdefaultNamespace)labels:検索やグルーピングに使われる Key-Value ペア(例:app: nginx)annotations:システムコンポーネントが利用するメタデータ(検索対象にはならない)
- spec
- リソースの仕様(Desired State)
- ここに記述された状態になるように Kubernetes が自律的に調整する
- 例:
containers:実行するコンテナの情報volumes:ストレージの情報
- 例:
以下は Pod を作成するマニフェストの例です。
このマニフェストをクラスタに適用するには以下のコマンドを実行します。
これで nginx コンテナを起動する Pod が 1 つ作成されます。
Dockerfile との責務分離
よく混同されがちですが、Dockerfile はコンテナイメージのビルド(Build)を定義 するもので、Kubernetes のマニフェストはコンテナの実行(Run) を定義するものです。
例えば、Dockerfile で定義されたデフォルトの起動コマンドや環境変数は、マニフェスト側で上書き(オーバーライド)することができます。
- Dockerfile(イメージの定義)
- Pod マニフェスト(実行時の定義)
このように、Kubernetes ではビルド済みの不変なイメージ(Immutable Image)に対して、環境毎の設定をマニフェストで注入するという設計思想になっています。
1.2 Pod の QoS クラス
Kubernetes は、リソース(CPU / Memory)の要求値(requests)と制限値(limits)の設定に基づいて、Pod に QoS Class を割り当てます。
これはノードがリソース不足に陥った際、どの Pod を優先的に停止(Evict)させるかを決定する重要な指標です。
| QoS Class | 条件 | OOM Score(oom_score_adj) | 特徴 |
|---|---|---|---|
| Guaranteed | 全てのコンテナで requests == limits(CPU / Memory 両方) | -998(最低) | 最も優先される。 よほどのことがない限り Kill されない。DB 等重要なステートフルアプリ向け。 |
| Burstable | 最低 1 つのコンテナで requests が設定されているが Guaranteed ではない | 2 〜 999 | Guaranteed よりは優先度が低い が、リソースに空きがある限り Limit までバースト可能。Web サーバ等一般的用途。 |
| BestEffort | requests も limits も設定されていない | 1000(最高) | 最も優先度が低い。 ノードのリソースが逼迫すると真っ先に Kill される。開発環境や重要度の低いバッチ向け。 |
【注意】
本番環境で安定稼働させるため、重要な Pod には必ず requests と limits を明示的に設定し、可能な限り Guaranteed クラスを目指すべきです。
1.3 Pod のライフサイクルと Probes
Pod は作成されてから削除されるまで、いくつかの状態(Phase)を遷移します。
| フェーズ | 説明 |
|---|---|
| Pending | Pod は承認されたが、コンテナイメージのダウンロード中か、スケジュール待ち |
| Running | 少なくとも 1 つのコンテナが起動している(または起動中・再起動中) |
| Succeeded | 全てのコンテナが正常終了(exit 0)し、再起動されない状態 |
| Failed | 少なくとも 1 つのコンテナが異常終了した状態(0 以外の終了ステータス) |
| Unknown | ノードとの通信断絶等、何らかの理由によりステート情報が不明 |
3 種類の Probe
Kubernetes はコンテナの状態を監視するために 3 種類の Probe(プローブ)と呼ばれるヘルスチェック機構を提供しています。 これらを適切に設定することで、障害時の自動復旧やゼロダウンタイムデプロイが可能になりあす。
- Startup Probe
- 目的:アプリケーションの起動完了を確認する
- 挙動:成功するまで、他の Probe(Liveness / Readiness)は実行されない
- 用途:起動に時間がかかるアプリケーション(例:Java, Rails)で、Liveness Probe による誤殺を防ぐために使用
- Liveness Probe
- 目的:アプリケーションが正常に稼働しているかを確認する
- 挙動:失敗すると、コンテナは再起動される
- 用途:デッドロックや無限ループに陥ったプロセスを自動復旧させる
- Readiness Probe
- 目的:アプリケーションがリクエストを受け付け可能かを確認する
- 挙動:失敗すると、Service のエンドポイントから IP アドレスが除外される(再起動はされない)
- 用途:起動直後の初期化処理中や、過負荷で一時的に応答できない場合に、リクエストを流さないようにする
ライフサイクルフック
Kubernetes ではライフサイクルフック(Lifecycle Hooks)という仕組みを用いて、コンテナの起動直後と停止直前に任意のコマンドを実行できます。
特に preStop フックは Graceful Shutdown において極めて重要です。
- postStart
- コンテナ作成直後に非同期で実行される(
ENTRYPOINTと並行)
- コンテナ作成直後に非同期で実行される(
- preStop
- コンテナが終了する(
SIGTERMが送られる)直前に実行される - Kubernetes が Pod を削除する際、まず
preStopフックを実行し、完了してからSIGTERMを送る - Nginx の場合、
sleep 10等を入れて、ロードバランサからの切り離しが完了するまで待機する処理がよく記述される
- コンテナが終了する(
1.4 InitContainer と Sidecar Containers
1 つの Pod には複数のコンテナを含めることができます。 これらは同じ IP アドレス、同じポート空間、同じストレージボリュームを共有します。
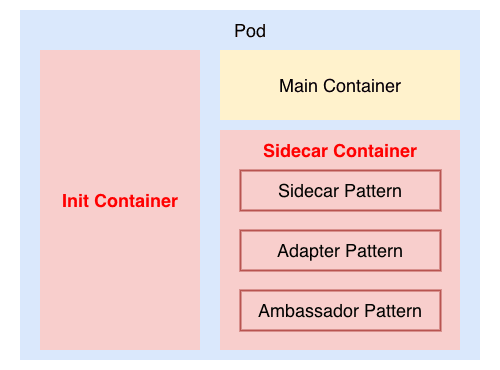
-
InitContainers
- メインコンテナが起動する前にシーケンシャルに実行される
- 例:
- DB の疎通確認待ち(
nc -z db 5432) - 設定ファイルの生成(
envsubst)
- DB の疎通確認待ち(
- 失敗すると Pod 全体が再起動を繰り返す(
RestartPolicyに従う)
-
サイドカーコンテナ(Sidecar Containers)
-
メインコンテナを補助するために、常にメインコンテナの横で動き続ける
-
サイドカーコンテナを用いたデザインパターンは、役割によって以下の 3 つに分類される
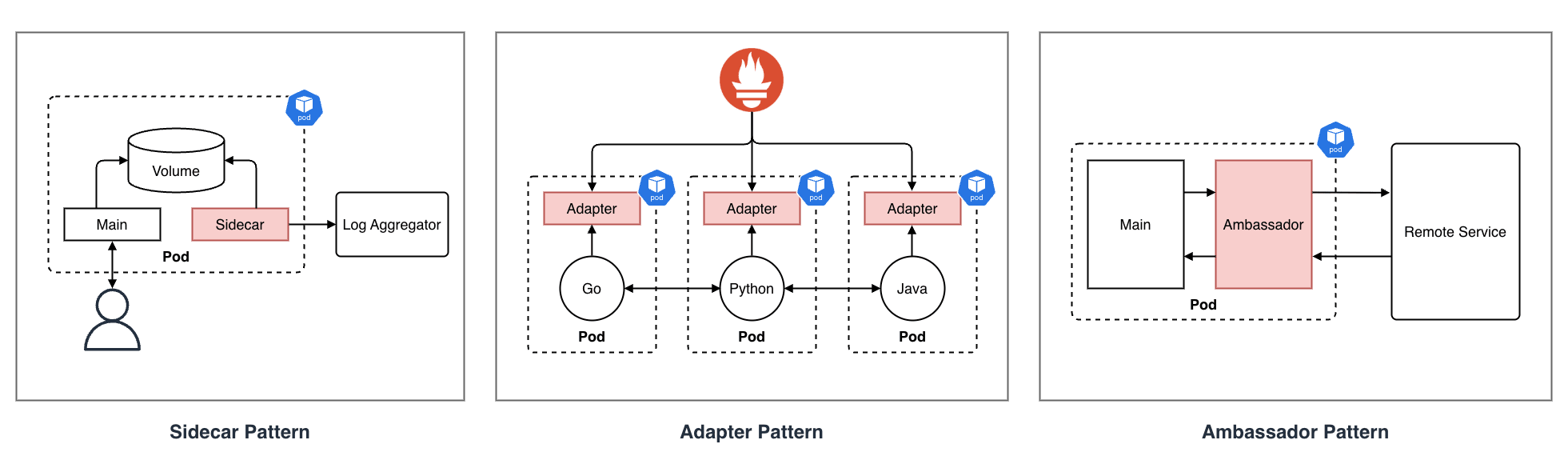
-
サイドカーパターン(Sidecar Pattern)
- 役割:メインコンテナの機能拡張
- メインコンテナ自体に変更を加えることなく、補助的な機能(ログ転送やファイル同期等)を追加するパターン
- 例:Web サーバのコンテンツを GitHub と定期的に同期する(git-sync)/ ログファイルを転送する
-
アダプターパターン(Adapter Pattern)
- 役割:インターフェースの変換・統一
- メインコンテナの出力を、外部システムが期待する標準的な形式に変換するパターン
- 例:アプリケーション独自のメトリクスを Prometheus 形式に変換するエクスポータ
-
アンバサダーパターン(Ambassador Pattern)
- 役割:外部への接続代理
- メインコンテナから外部システムへの通信を中継・代行するパターン
- アプリケーションはローカルホストに接続するだけで複雑な接続処理(認証やルーティング)をアンバサダーが隠蔽する
- 例:Cloud SQL Auth Proxy、サービスメッシュのサイドカープロキシ(Envoy)
-
-
Downward API
- Pod 自身の情報(例:Pod 名、Namespace、IP アドレス、リソース制限値)を環境変数やボリュームファイルとしてコンテナ内に注入する機能
- アプリケーションが自分自身のメタデータを知る必要がある場合に利用する
第 2 章:Namespace とマルチテナンシ

Kubernetes の Namespace は、同一の物理クラスタ上で複数のチームやプロジェクトが共存できるように、クラスタを仮想的に分割する機能です。 これにより、同じクラスタ内で、「開発環境(dev)」や「本番環境(prod)」といった環境毎の分離や、リソース名の衝突回避が可能になります。
2.1 Kubernetes における Namespace
混同されがちですが、Linux カーネルにおけるリソース分離機能(Namespace)と、Kubernetes の Namespace は別物 です。
- Linux Namespace:カーネルリソース(PID, Network, Mount 等)をプロセス単位で隔離する技術(コンテナの実体)
- Kubernetes Namespace:Kubernetes API オブジェクトを論理的にグループ化する機能
Kubernetes クラスタに Namespace を作成しても、Linux カーネル上に新しい Namespace が作られるわけではありません。 Kubernetes における Namespace は、etcd 上の仮想的な分離およびキー表現に利用されます。
2.2 etcd におけるキー構造
Kubernetes の全データは分散 KVS である etcd に保存されますが、Namespace はそのキー空間(Key Space)を分割する役割を果たしています。
API サーバはこの構造を利用して、以下のような重要な機能を実現しています。
- 効率的なクエリ(Range Query)
特定の Namespace 内のリソースのみを一括で取得・監視することが可能になります。 これはクラスタ全体の負荷を軽減し、スケーラビリティを向上させます。
- 権限チェック(RBAC)の最適化
Namespace 単位でのアクセス制御を行う際、API サーバはリクエストされたリソースパスのプレフィックスを見るだけで、対象のスコープを迅速に判定できます。
- リソースクォータ(ResourceQuota)の適用
CPU やメモリの使用量制限を Namespace 単位で集計・管理するための境界線として機能します。
これはデータベースにおける「スキーマ」や SaaS における「テナント ID」に近い概念であり、マルチテナント環境における論理的な分離の基盤となっています。
2.3 ソフトマルチテナンシとハードマルチテナンシ
Namespace は ソフトマルチテナンシ(論理的な分離)を提供しますが、ハードマルチテナンシ(完全な隔離)は提供しません。
- ネットワーク:デフォルトでは Namespace 間の通信は遮断されない(フラットネットワーク)
- リソース競合:同一ノード上の Pod はカーネルを共有するため、cgroups による制限をかけない限り リソースを奪い合う可能性 がある
従って、厳格な分離が必要な場合は、Namespace だけでなく、Sandboxed Containers(gVisor, Kata Containers)や、物理的なクラスタ分割を検討する必要があります。
2.4 リソースのスコープ
Kubernetes のリソースには、Namespace 内に閉じ込められるもの(Namespaced)と、クラスタ全体で共有されるもの(Cluster Scoped)の 2 種類があります。
-
Namespaced リソース
- 特徴:特定の Namespace に所属する。作成時に
-nで指定可能で、Namespace を削除すると共に削除される。 - 主なリソース:
Pod,Service,Deployment,StatefulSet,Secret,ConfigMap,PVC,Role,ServiceAccount,NetworkPolicy
- 特徴:特定の Namespace に所属する。作成時に
-
Cluster Scoped リソース
- 特徴:Namespace に所属しない。クラスタ全体で一意の名前を持ち、全 Namespace から参照可能。
- 主なリソース:
Node,Namespace,PersistentVolume(PV),StorageClass,ClusterRole,ClusterRoleBinding,CRD
任意のリソースがどちらのスコープなのかは、以下のコマンドで確認することができます。
第 3 章:クラスタネットワークとサービスディスカバリ
Kubernetes のネットワークモデルは 全ての Pod が NAT 無しで相互に通信できる というフラットなネットワークを前提としています。
これは P2P(Peer-to-Peer)アーキテクチャ において、参加ノードが対等に直接通信するという特性と類似しており、実際に多くの CNI プラグイン(Flannel や Calico 等)は、ノード間を オーバーレイネットワーク で接続することで、物理ネットワーク構成に依存しない論理的なフラットネットワークを実現しています。
Kubernetes では、これを実現するために CNI(Container Network Interface) プラグインが利用されます。
3.1 CNI とオーバーレイネットワーク

CNI は、Pod が起動した際にネットワークインターフェースを作成し、IP アドレスを割り当てるための標準インターフェースです。 Flannel, Calico, Cilium, AWS VPC CNI といった多数の実装があります。
オーバーレイネットワーク(VXLAN / IPIP)
異なるノード上の Pod 同士が通信するために、Kubernetes では物理ネットワークの上に、仮想的なネットワーク(オーバーレイネットワーク)を構築します。 VXLAN(Virtual eXtensible Local Area Network) は代表的なプロトコルで、L2 フレームを UDP パケット(ポート 4789 番)にカプセル化して物理ネットワーク(L3)上で配送します。 これにより、異なる LAN に存在するワークロードは NAT を意識することなく、シームレスに相互通信することができます。
身近なところでは、VPN トンネルがオーバーレイネットワークの一種にあたります。
オーバーレイネットワークや VXLAN の仕組みについては こちら のブログでも詳しく紹介しています。
パケットフロー追跡
Pod A(Node 1:10.244.1.2)から Pod B(Node 2:10.244.2.2)へリクエストを送信する場合のパケットフローを追ってみます。
ここでは、CNI に Flannel(VXLAN モード)を利用していることを前提とします。
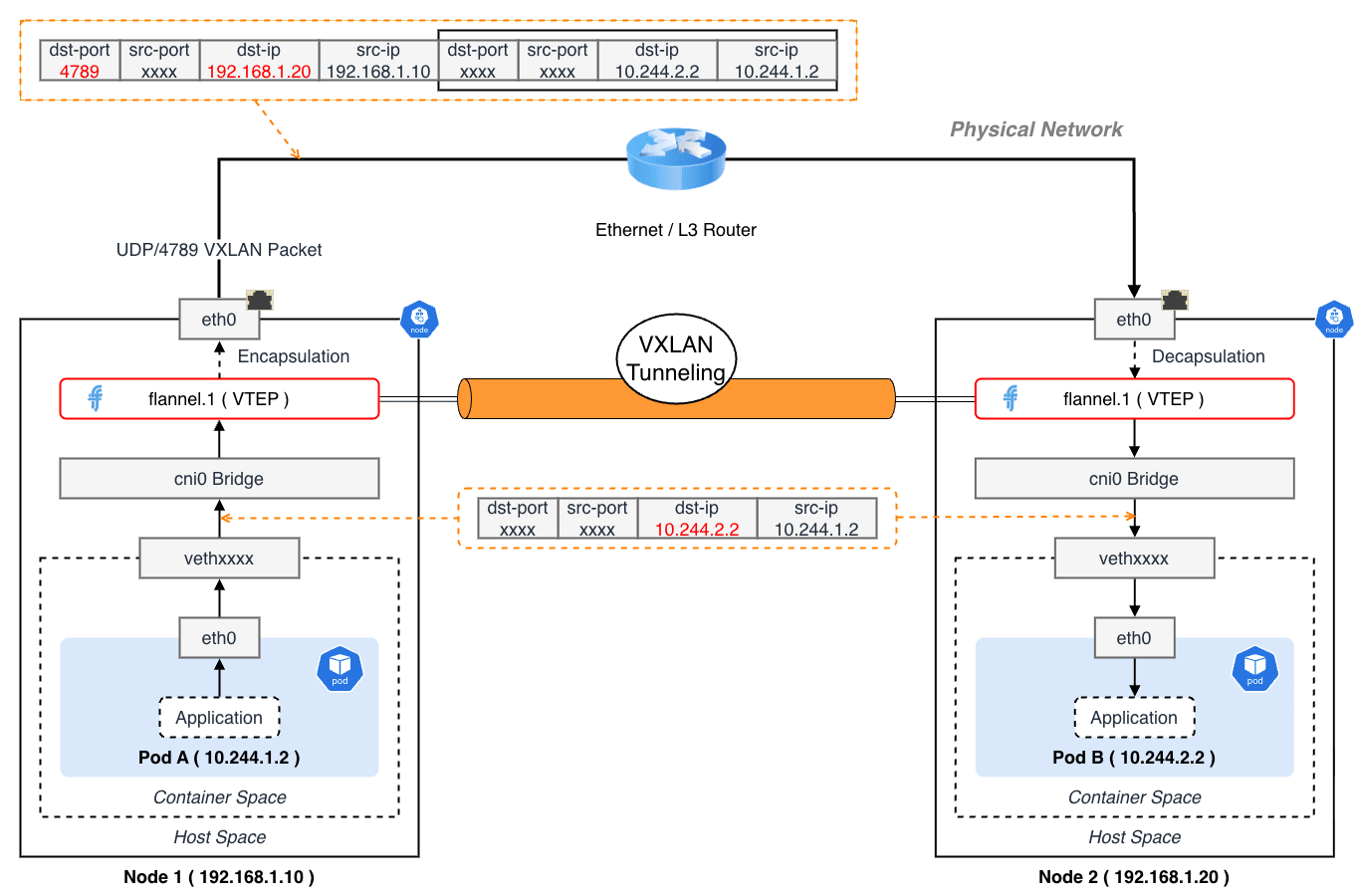
- コンテナ内(Pod A)
- アプリケーションが
10.244.2.2へパケット送信 - ルートテーブルによりデフォルトゲートウェイ(
eth0)へ転送
- アプリケーションが
- veth ペア通過
- パケットはホスト側の
vethxxxxインターフェースへ移動 - この時点で Network Namespace が「コンテナ」から「ホスト」へ 切り替わる
- パケットはホスト側の
- ブリッジ(cni0)
vethはcni0ブリッジに接続されている- ブリッジは L2 スイッチとして動作するが、宛先 IP(
10.244.2.2)はローカルネットワーク外 - Node 1 のルートテーブルを参照:
10.244.2.0/24 via 10.244.2.0 dev flannel.1 - これにより、パケットは
flannel.1インターフェースへ転送される
- カプセル化(Encapsulation - Node 1)
flannel.1の実体は VTEP(VXLAN Tunnel End Point)となっている- カーネルは、宛先
10.244.2.2が Node 2 の物理 IP(192.168.1.20)に紐付いていることを FDB(Forwarding Database)から知る - オリジナルのパケットに以下のヘッダを付与する
- Ethernet Header:
Src=Node1 MAC, Dst=Node2 MAC - IP Header:
Src=Node1 IP, Dst=Node2 IP, Proto=UDP - UDP Header:
Dst Port=4789 - VXLAN Header:
VNI=1
- Ethernet Header:
- 物理ネットワーク上での通信
- カプセル化された UDP パケットとして物理ネットワークを通して Node 2 に到達する
- カプセル化解除(Decapsulation - Node 2)
- Node 2 のカーネルが UDP 4789 ポートでパケットを受信
- VXLAN ドライバがヘッダを取り外す
- ルーティング(Node 2)
- 取り出されたパケット(Dst:
10.244.2.2)を見てルートテーブルを参照 10.244.2.0/24 dev cni0に従い、cni0ブリッジへ転送
- 取り出されたパケット(Dst:
- コンテナへ到達(Pod B)
cni0ブリッジは ARP テーブルを参照して対応するvethyyyyへフレームを転送- Pod B の
eth0に到達し、アプリケーションが受信する
Bash で理解する CNI プラグイン
CNI は単なる実行ファイルの仕様でしかありません。 ということは、以下の環境変数と標準入力(JSON)を受け取って動作すれば、Bash スクリプトでも CNI プラグインを作成することが可能です。
- コマンド:
ADD,DEL,CHECKが環境変数(CNI_COMMANDで渡される) - 入力:ネットワーク設定が標準入力で渡される
Kubernetes は、これと同等のスクリプトを Pod 作成時に実行しています。 CNI の仕様に関する詳細は、CNI Specification に記載されています。
3.2 Service の仕組みと iptables / IPVS

Service は、動的に IP が変わる Pod 群に対して、単一の不変な IP アドレス(ClusterIP)を提供します。 この仕組みの裏側には、Linux カーネルの netfilter(iptables) があります。
kube-proxy(iptables mode)の実体
kube-proxy はプロキシサーバとしてパケットを中継するのではなく、iptables ルールを管理するエージェント です。 実際のパケット転送はカーネルが行います。
Service my-svc(ClusterIP:10.96.0.100, Port:80)が、2 つの Pod(10.244.1.5:8080, 10.244.2.6:8080)に振り分ける場合の iptables Chain を見てみます。
このように、DNAT(Destination NAT)によって宛先 IP が ClusterIP から特定の Pod IP に書き換えられることで通信が成立します。
IPVS モードの優位性
Service が数千個を超えると、iptables ルールが膨大になり、ルール更新やパケット照合の計算量が で増加し、パフォーマンスが劣化します。 IPVS(IP Virtual Server) モードを使うと、ハッシュテーブルベースの ルーティングが可能になり、大規模クラスタでも高速に動作します。
iptables ルールの中身
実際に iptables-save コマンドで、NodePort Service がどのように実装されているかを確認してみます。
この出力から、Kubernetes がカーネルのパケットフィルタリング機能を巧みに利用してロードバランサを実装していることがわかります。
確率的なルール(--mode random --probability)を Chain させることで、単純なラウンドロビンに近い負荷分散をカーネルレベルで高速に処理しています。
3.3 Service と CoreDNS

Kubernetes 内のサービスディスカバリには CoreDNS が標準で使われます。
Service を作成すると、my-service.my-ns.svc.cluster.local のような A レコードが CoreDNS に登録されます。
Pod がこのドメイン名を解決すると、Service の ClusterIP が返されます。 そして、ClusterIP へのアクセスは、前述の kube-proxy(iptables / IPVS)によって各 Pod へ振り分けられます。
第 4 章:ワークロードとストレージ
4.1 ワークロードリソースと OwnerReference
アプリケーションの状態や性質に応じて、Kubernetes は様々なワークロードリソース(コントローラ)を提供しています。 本章では、特に重要な Deployment, StatefulSet, DaemonSet, Job / CronJob の役割や特徴について紹介します。
コントローラと Pod の親子関係
これらのリソースによって作成された Pod には、metadata.ownerReferences というフィールドが自動的に付与されます。
これは「誰がこの Pod を管理しているか」を示すポインタにあたります。
例えば Deployment が作成した Pod は、直接的には Deployment ではなく ReplicaSet によって管理されます。
Kubernetes のガベージコレクションはこの参照を辿り、親(Deployment)が削除されたときに、子(ReplicaSet)や孫(Pod)もカスケード削除する仕組みになっています。
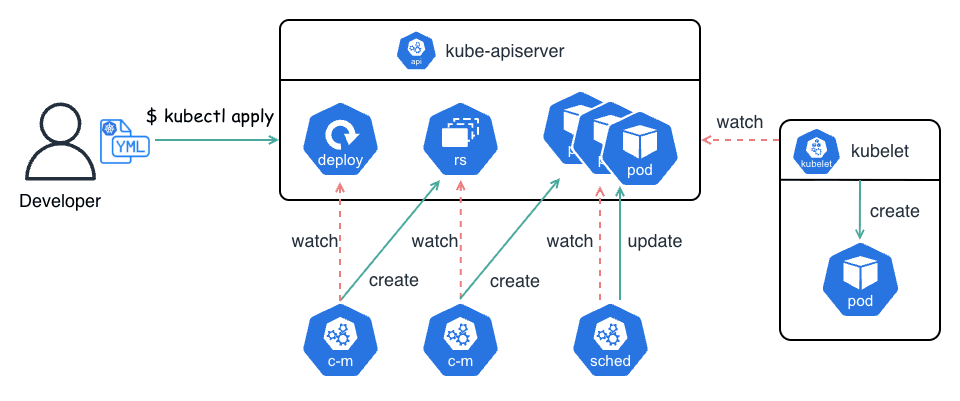
また、本番環境では、テストやカナリアリリース等を除き、素の Pod を単体でデプロイすることはほとんどの場合ありません。 これは、所謂「裸の Pod(Naked Pod)」と呼ばれる非推奨な方法です。
必ず Deployment 等のワークロードリソースを経由してデプロイすることで、セルフヒーリング機能やローリングアップデートといった恩恵を受けることができます。
4.2 アプリケーションの性質とリソース選択
| リソース | 用途 | 特徴 |
|---|---|---|
| Deployment | ステートレスアプリ | Web サーバや API サーバ等。Pod の入れ替えが自由。ReplicaSet を管理し、Rolling Update を標準で提供。 |
| StatefulSet | ステートフルアプリ | DB(MySQL, PostgreSQL)や分散 KV ストア(kafka, Zookeeper)等。順序(0, 1, 2...)とネットワーク ID(pod-0.svc)が永続的に維持される。ストレージ(PVC)も Pod 毎に個別に紐付けられる。 |
| DaemonSet | ノード常駐エージェント | ログ収集(Fluentd)や監視(Node Exporter)、CNI プラグイン等。全ノード(または指定ノード)に 1 つずつ Pod を配置。新しいノードが追加されると自動的に Pod が起動する。 |
| Job / CronJob | バッチ処理 | 完了することを期待されるタスク。CronJob は定期実行。失敗時のリトライ回数等を制御できる。 |
4.3 Deployment のアップデート戦略

Deployment は、新しいバージョンのアプリケーションをデプロイする際、ダウンタイムが発生しないように Rolling Update を行います。
この挙動は maxSurge と maxUnavailable という 2 つのパラメータで厳密に制御されます。
Rolling Update の計算ロジック
例:replicas: 10, maxSurge: 20% (2), maxUnavailable: 10% (1) の場合
- Max Surge(超過可能数):
10 * 0.2 = 2- 最大で
10 + 2 = 12個の Pod が同時に存在できる
- 最大で
- Max Unavailable(不足可能数):
10 * 0.1 = 1;- 最小で
10 - 1 = 9個の Pod が Running 状態である必要がある
- 最小で
更新プロセス
- Start:現在 10 (
v1) が起動中 - Scale Up:新しい ReplicaSe(
v2) を作成して Pod を起動- 上限は 12 なので、一度に 2 つ(
v2) 起動できる (v1: 10,v2: 2,Total: 12)
- 上限は 12 なので、一度に 2 つ(
- Scale Down:v2 が Ready になったら、古い ReplicaSe(
v1) を停止- 下限は 9 なので、3 つ(
v1) 停止できる(12 - 3 = 9) (v1: 7,v2: 2,Total: 9) - ただし、実際には
maxSurgeの枠を使って、さらに新しい Pod を起動していく
- 下限は 9 なので、3 つ(
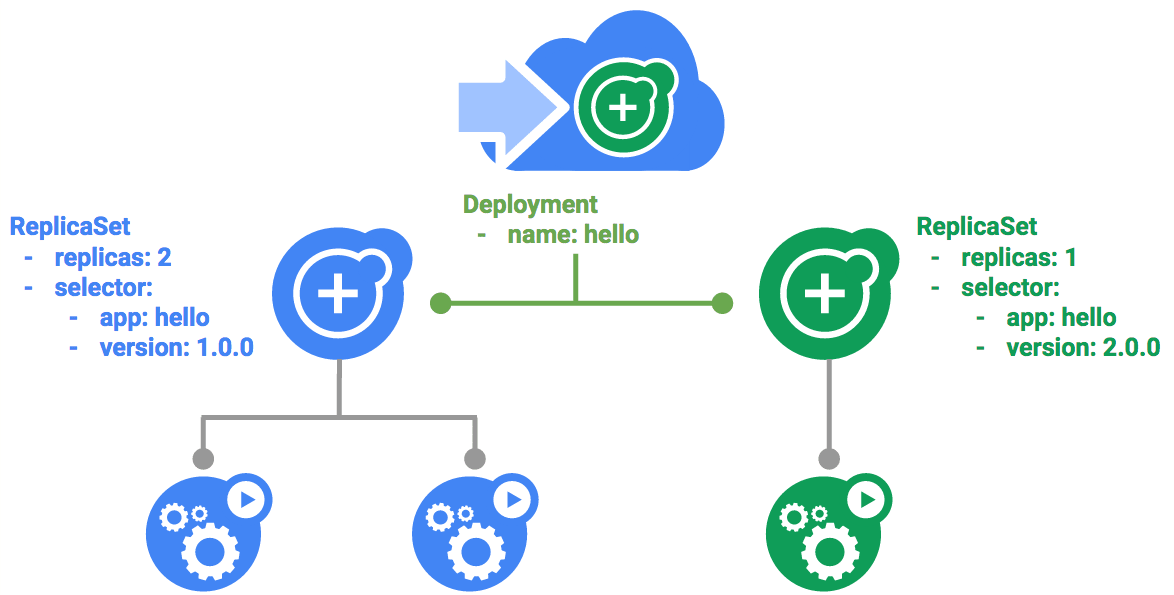
このように、Kubernetes は「許容できる最大数」と「最小数」の範囲内で、順次新しい Pod へ入れ替えていきます。
4.4 StatefulSet のアイデンティティ管理

StatefulSet は、永続的なアイデンティティ(識別子)が必要なアプリケーションのために設計されています。
1. ネットワーク識別子(Stable Network ID)
StatefulSet で作成された Pod は、ランダムなハッシュ値ではなく、web-0, web-1, web-2 のような連番のホスト名を持ちます。
これらは Headless Service(ClusterIP: None)と組み合わせることで、DNS 名で直接解決可能になります。
web-0.nginx.default.svc.cluster.local->10.244.1.5web-1.nginx.default.svc.cluster.local->10.244.2.6
Pod が再起動して IP が変わっても、DNS 名は変わりません。
これにより、MySQL のレプリケーション設定等で「マスターは mysql-0」と固定的に記述できます。
2. 永続ストレージ(VolumeClaimTemplates)
Deployment では全ての Pod が同じ PVC(*後述)を共有するか、そもそも PVC を持ちませんが、StatefulSet は volumeClaimTemplates を定義することで、Pod 毎に専用の PVC を自動生成します。
web-0->www-web-0(PVC)web-1->www-web-1(PVC)
Pod web-0 が削除されて別のノードで再作成された場合でも、必ず同じ PVC www-web-0 が再マウントされます。
これにより、データの永続性と一貫性が保証されます。
4.5 DaemonSet
DaemonSet は、クラスタ内の全てのノード(またはラベルセレクタに一致する特定のノード群) に対して、Pod のコピーを 1 つずつ配置するためのコントローラです。 Deployment のようにレプリカ数を指定するのではなく、ノードが増えれば自動的に Pod も増える という特性を持ちます。
主なユースケース
- ログ収集エージェント
- モニタリングエージェント
- Prometheus Node Exporter を配置して各ノードのハードウェアリソース使用状況を監視する
- ネットワークプロキシ
- kube-proxy も実際には DaemonSet として実装されていることが多い(※ ディストリビューションによる)
4.6 Job と CronJob


Deployment や StatefulSet が常駐するプロセスを管理するのに対し、Job は完了して終了する(Run-to-Completion)プロセス を管理します。
- Job
- 指定された数の Pod が正常終了(Succeeded)するまで、必要に応じて Pod を再実行し続ける
- バッチ処理やデータのマイグレーション等に適する
- CronJob
- UNIX の crontab 形式のスケジュールに従って定期的に Job オブジェクトを作成する
- 定期実行のタスクに適する
4.7 ストレージオーケストレーション
Kubernetes では、ストレージの実体(物理ディスク)と、ユーザからの要求(論理ボリューム)を分離して管理します。



- PersistentVolume(PV)
- クラスタ管理者が提供する実際のストレージリソース
- Pod とは独立したライフサイクルを持つ
- PersistentVolumeClaim(PVC)
- ユーザ(開発者)による「ストレージを使いたい」というリクエスト
- 「容量 10Gi で ReadWriteOnce モードのディスクが欲しい」といった要求を定義する
- StorageClass(SC)
- ストレージの「種類」を定義する
- 例:
standard= HDD,fast= SSD)
- 例:
- これを指定することで、PV を事前に手動で作らなくても、オンデマンドで自動作成(動的プロビジョニング)することが可能になる
- ストレージの「種類」を定義する
CSI:Container Storage Interface

かつては Kubernetes のソースコード内に AWS EBS や NFS 等のボリュームプラグインが含まれていましたが(In-Tree)、現在は CSI(Container Storage Interface) という標準インターフェースに切り出され(Out-of-Tree)、各ストレージベンダが独自のドライバを提供しています。
動的プロビジョニング(Dynamic Provisioning)
CSI と StorageClass を利用すると、ユーザが PVC を作成したタイミングで、自動的にクラウド側のディスク作成 API を呼び出し、PV を作成・バインドすることが可能になります。 これを 動的プロビジョニング(Dynamic Provisioning)と呼びます。
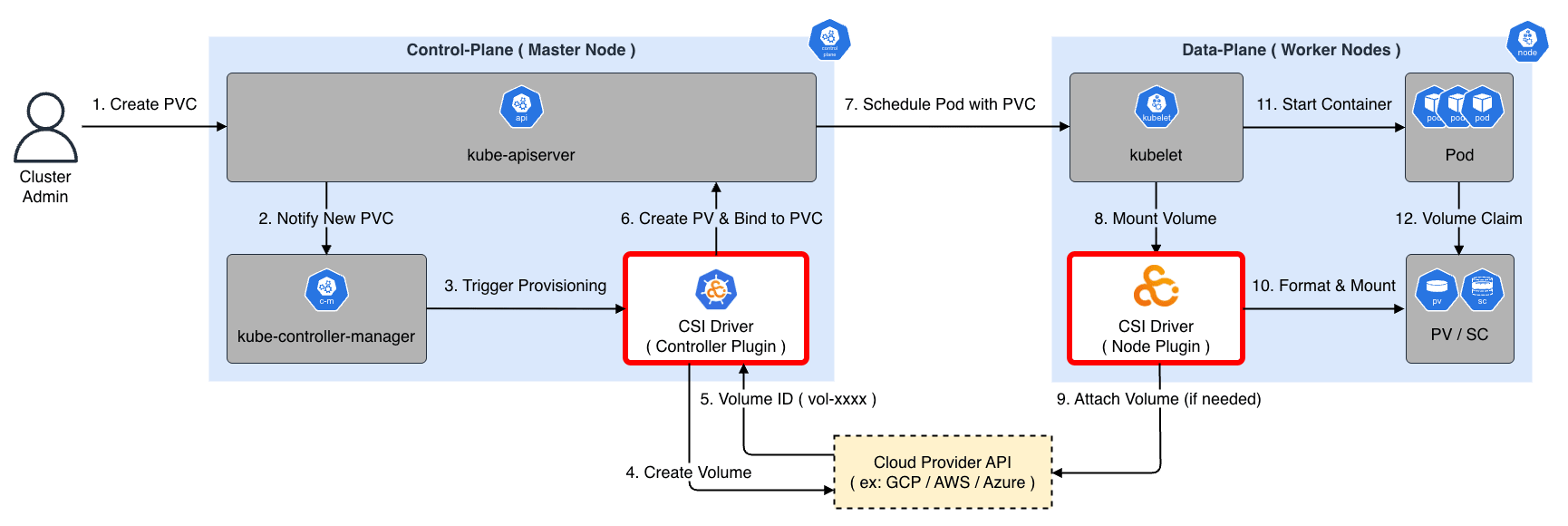
- User:
PersistentVolumeClaim(PVC)を作成する(StorageClass: standard指定) - kube-controller-manager:PVC の作成を検知し、指定された StorageClass に対応する CSI Provisioner(外部コントローラ) に通知
- CSI Driver(Controller):クラウドプロバイダの API(例:
aws ec2 create-volume)を叩いて実ディスクを作成 - CSI Driver:作成したディスク ID を持つ
PersistentVolume(PV)オブジェクトを作成して PVC にバインド - kubelet(Node):Pod がスケジュールされたノード上で、CSI Driver(Node)がディスクをフォーマットして Pod にマウント
※ 厳密には、クラウドプロバイダ固有のリソース作成(LoadBalancer や Volume 等)には cloud-controller-manager が関与する場合もありますが、現在の標準的な CSI 構成では CSI Driver 自体がクラウド API を直接操作することが一般的です。
この仕組みにより、開発者はベンダ毎の実装の違いを意識することなく、ディスクストレージを抽象的な要求によって利用することができます。
4.8 オートスケーリング

HPA(Horizontal Pod Autoscaler)は、Pod の CPU 使用率やカスタムメトリクスに応じて Deployment の replicas 数を自動的に増減させます。
オートスケーリングの計算式
HPA コントローラは 15 秒(デフォルト)毎に以下を計算します。
例えば、現在のレプリカ数が 3 で、CPU 使用率が 50%(Current)、目標が 25%(Desired)の場合、 となり、レプリカ数を 6 にスケールアウトさせます。
フラップ(Flapping)の防止
負荷が頻繁に上下する場合、スケールアウトとスケールインを繰り返すとシステム全体が不安定になります。 これを フラッピング(Flapping)または スラッシング(Thrashing) と呼んだりします。
このような現象を防ぐため、HPA には Stabilization Window(安定化ウィンドウ) が用意されており、デフォルトで過去 5 分間の推奨値の中で最大のものを採用する(スケールインを遅らせる)ロジックが組み込まれています。
4.9 スケジューリングの制御
特定の Pod を任意のノードに配置したい(あるいは配置したくない)場合、Kubernetes の制御機能を利用することができます。
Taints / Tolerations
ノードに対して Taint(制約) を付与することで、その条件を Toleration(許容) できない Pod のスケジュールを拒否します。
例えば、GPU 搭載ノードに gpu=true:NoSchedule という Taint を付けると、これに対応する Toleration を持たない Pod はスケジュールされません。
Affinity / Anti-Affinity
Taint が「拒否」する仕組みであるのに対し、Affinity は Pod を特定のノードに「引き寄せる」仕組みです。
-
Node Affinity
- 特定のラベルを持つノードにスケジュールする
requiredDuringSchedulingIgnoredDuringExecution:必須条件(満たさないと Pending となる)preferredDuringSchedulingIgnoredDuringExecution:推奨条件(満たさなくても起動はする)
-
Pod Affinity / Anti-Affinity
- 既に実行されている他の Pod との位置関係で配置先を決定する
- 例:
- Web サーバとキャッシュサーバを同じノードに置きたい → Affinity を利用
- 冗長化のため、同じアプリケーションの Pod は別々のノードに配置したい → Anti-Affinity を利用
この設定により、app=store ラベルを持つ Pod 同士は、同じホスト名を持つノード(つまり同一ノード)にはスケジュールされなくなります。
第 5 章:構成とシークレット
アプリケーションをコンテナ化する際、設定(Configuration)と コード(Code)を分離する ことは Twelve-Factor App における重要な原則の一つです。
Kubernetes では、環境毎に異なる設定値やパスワード等の機密情報を、コンテナイメージをビルドし直すことなく外部から注入するための仕組みを提供しています。 特に ConfigMap と Secret はその中核となるリソースです。
5.1 ConfigMap

ConfigMap は、アプリケーションの設定ファイルや環境変数といった 機密ではないデータを、コンテナイメージから分離して管理するためのリソースです。 これにより、開発環境と本番環境で異なる設定値を注入したり、アプリケーションコードを変更することなく設定を変更したりすることができます。
5.2 Secret

Secret は、パスワード、OAuth トークン、SSH キー等の 機密性の高いデータを格納するためのリソースです。 機能的には ConfigMap と似ていますが、以下の点で異なります。
- データは Base64 形式でエンコードされて保存される
- クラスタの設定により etcd 内で暗号化して保存(Encryption at Rest)することが可能
5.3 ローディング方法
1. 環境変数としての注入
最も基本的な使い方は、Pod の環境変数として値を渡す方法です。
2. Volume としてのマウント
nginx.conf のような設定ファイルをそのままファイルとして配置したい場合は VolumeMount を利用します。
この方法の利点は、ConfigMap の内容を書き換えると、Pod 内のファイルも(数分のラグはありますが)自動的に更新されます。
これは Secret を Volume としてマウントした場合も同様です。
※ 環境変数として注入した場合、Pod を再起動またはロールアウトしない限り値は更新されません。
第 6 章:セキュリティと権限管理
Kubernetes は マルチテナント を考慮しており、厳格な権限管理機能を提供しています。
6.1 Role-Based Access Control




「誰が(Subject)、何に対して(Resource)、何をしてよいか(Verb)」というアクセスポリシを定義し、それらを紐付けることで制御します。
具体的には、Role また ClusterRole リソースを用いて「どの API リソースに対して、どのような操作(get, list, create 等)を許可するか」という権限セットを定義します。 ここで、Role とは特定の Namespace 内で有効な権限セットを定義するためのリソースであり、ClusterRole とはクラスタ全体で有効な権限セットを定義するためのリソースです。
Role の場合は、RoleBinding を、ClusterRole の場合は ClusterRoleBinding を用いて特定のユーザやグループ、ServiceAccount に紐付けることで、実際の権限付与が行われます。
- 例:閲覧専用ユーザの作成
権限確認
設定した RBAC が正しく機能しているか確認するには auth can-i サブコマンドを利用します。
User と Group


Kubernetes には User というリソースは存在しません。
ユーザ認証は外部(Google アカウント、LDAP、クライアント証明書の CN)に委譲されています。
RBAC では、証明書に含まれる CN(Common Name)をユーザ名、O(Organization)をグループ名として扱います。
例えば O=system:masters というグループには、デフォルトで特権(cluster-admin)が割り当てられています。
6.2 ServiceAccount と Pod の権限

Pod 内のアプリケーションが Kubernetes API を操作する場合(例:CI/CD ツール、監視エージェント)、ServiceAccount を利用します。
デフォルトでは default ServiceAccount がマウントされますが、権限を絞った専用の ServiceAccount を作成して Pod に割り当てることがセキュリティ上のベストプラクティスです。
認証フローとトークンの仕組み
ServiceAccount を使用すると、Kubernetes は自動的に JWT を生成し、Pod 内の /var/run/secrets/kubernetes.io/serviceaccount/token にマウントします。
アプリケーションはこのトークンを Authorization: Bearer <TOKEN> ヘッダとして付与することで、API サーバへの認証を行います。
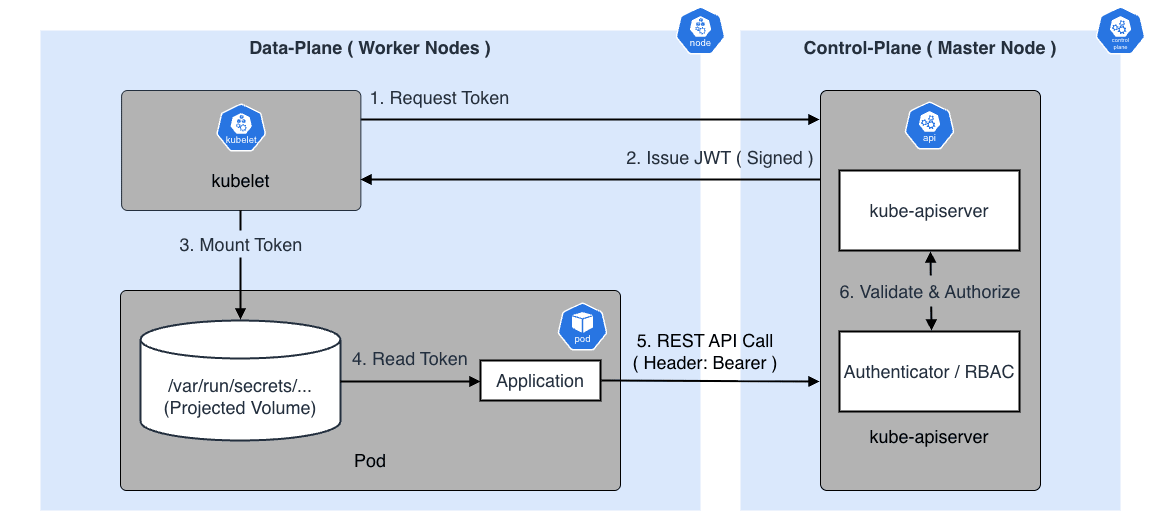
kubectl(User Account)との違い
| ServiceAccount(SA) | User Account(UA) | |
|---|---|---|
| 主な利用者 | Pod 内のプロセス(Bot) | 人間の管理者・開発者 |
| 管理主体 | Kubernetes リソースとして管理 | 外部(Google, LDAP 等)で管理 |
| 認証方式 | JWT トークン(自動マウント) | クライアント証明書 / OIDC トークン |
| スコープ | Namespace に属する | グローバル(全クラスタ) |
私たちが普段 kubectl を実行する際は、~/.kube/config に記載されたクライアント証明書や外部認証プロバイダ(OIDC)のトークンを使って User Account として認証しています。
一方、Pod は ServiceAccount として認証され、そのユーザ名は system:serviceaccount:<namespace>:<name> という形式になります。
6.3 Pod Security Context
コンテナ仮想化技術と Kubernetes の俯瞰図 - 基礎編 で解説した Capabilities やファイルシステムの権限設定を、Kubernetes リソースとして定義する機能です。
コンテナの実行ユーザ(runAsUser)や特権の剥奪(drop capabilities)を指定することで、堅牢な Pod を作成できます。
第 7 章:Kubernetes API の拡張
7.1 Custom Resource Definition

Kubernetes の特徴の一つに、API 自体をユーザが拡張できる CRD(Custom Resource Definition) という機能があります。
CRD を作成すると、標準のリソース(Pod や Deployment)と同じように kubectl コマンドや Kubernetes API 経由で独自のオブジェクトを操作できるようになります。
7.2 Operator パターン
CRD 単体ではただのデータですが、それを監視・制御する「カスタムコントローラ」を組み合わせることで、特定のアプリケーションの運用ノウハウを自動化することができます。 これを Operator パターン と呼びます。
例えば、Prometheus Operator は Prometheus という CRD を定義します。
ユーザがこのマニフェストを適用すると、Operator(コントローラ)がこれを検知して以下の処理を自動で行います。
- 指定されたバージョンの Prometheus を StatefulSet としてデプロイする
replicas: 2に従って冗長構成を組む- 設定ファイルの生成とリロードを行う
このように、「Prometheus クラスタの構築と運用」というドメイン知識をコード化(Codify)し、Kubernetes ネイティブなリソースとして扱えるようにするのが CRD の真価です。
7.3 Kubebuilder

独自の Operator を一から実装するのはハードルが高いですが、Kubebuilder という SDK を利用することで、開発を効率化できます。 Kubebuilder は Go 言語で書かれており、CRD の定義やコントローラの雛形(Scaffold)を自動生成してくれるため、開発者はビジネスロジックの実装に集中することができます。
第 8 章:minikube で構築するローカル Kubernetes
Kubernetes の基本的なリソースを理解したところで、実際に自分の手でクラスタを操作してみることで、各コンポーネントの役割がより明確になります。 本番環境では kubeadm や kOps、あるいはパブリッククラウドのマネージドサービス(EKS, GKE, AKS)を利用することが一般的ですが、学習目的であれば minikube や kind 等を使ってローカルマシン上に軽量な Kubernetes 環境を構築することができます。
本章では、minikube を使ってローカルマシン上に Kubernetes クラスタを構築する方法について紹介します。
8.1 minikube とは

minikube は、ローカルマシン上でシングルノードの Kubernetes クラスタを簡単に起動できるツールです。 macOS, Linux, Windows に対応しており、Docker, VirtualBox, Hyper-V, Podman 等の様々なドライバ上で動作します。
minikube のアーキテクチャ
コンテナ仮想化技術と Kubernetes の俯瞰図 - 基礎編 で紹介したとおり、本番環境の Kubernetes クラスタでは通常、Control-Plane と Data-Plane が物理的に分離されています。
一方で、minikube では これらが単一ノード上に統合 されています。 つまり、1 つの VM(またはコンテナ)の中で、Control-Plane コンポーネントとユーザのワークロードが共存して動作します。
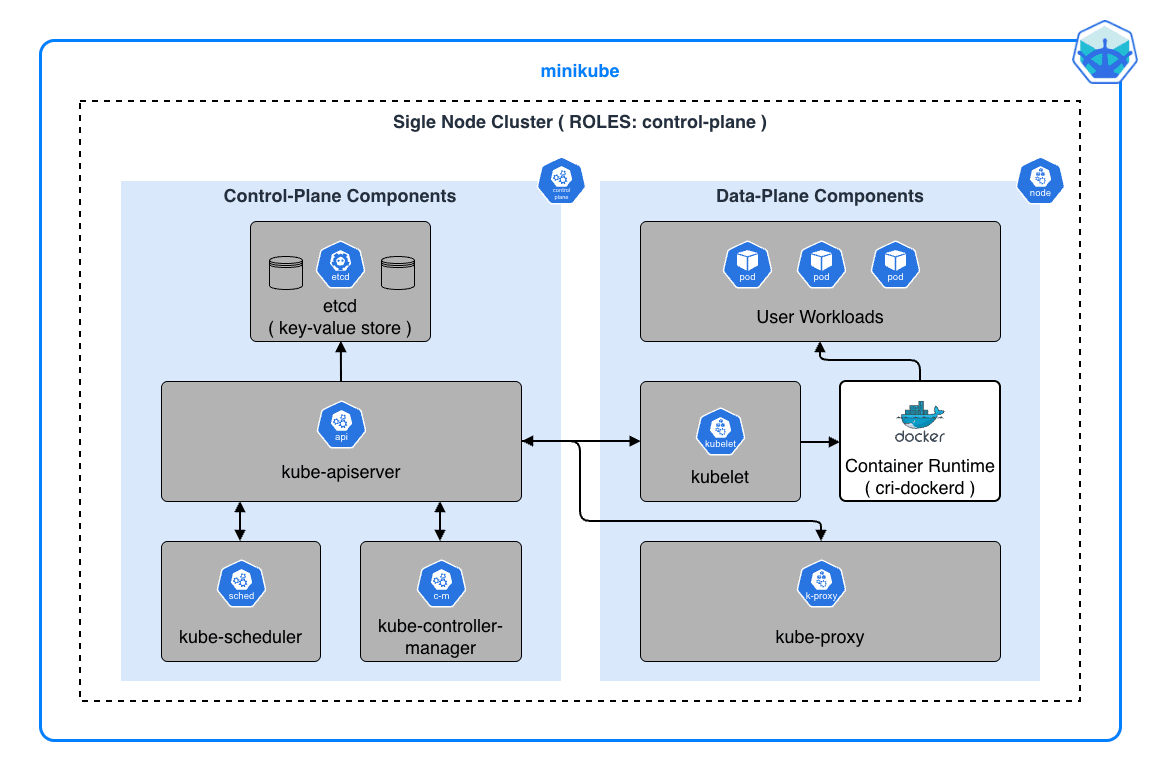
この統合により、複数のサーバを用意することなく、ラップトップ 1 台で Kubernetes の全機能を触ることができます。
ただし、本番環境とは異なり、minikube では高可用性(HA)や負荷分散の検証には適していないため、あくまで学習・開発用途として利用します。
主な特徴
- 軽量:シングルノード構成で、ラップトップでも手軽に動作する
- アドオン:Dashboard, Ingress, metrics-server 等の機能をワンコマンドで有効化できる
- マルチクラスタ:複数のクラスタを同時に起動・切り替え可能
- LoadBalancer サポート:
minikube tunnelコマンドで LoadBalancer タイプの Service をローカルで利用可能
8.2 minikube のインストール
macOS
Homebrew を使用してインストールします。
Linux
バイナリを直接ダウンロードしてインストールします。
Windows
Chocolatey または WinGet を使用します。
kubectl のインストール
minikube には kubectl が同梱されていますが、独立してインストールすることも可能です。
8.3 クラスタの起動と基本操作
クラスタの起動
以下のコマンドで Kubernetes クラスタを起動します。
初回起動時は、コンテナイメージのダウンロードが行われるため、数分程度掛かります。
起動が完了すると、kubectl が自動的に minikube クラスタに接続するよう設定されます。
クラスタの状態確認
クラスタの停止・削除
8.4 アドオン
minikube は、よく使われる Kubernetes コンポーネントを アドオン として簡単に追加することができます。
よく使うアドオン
| アドオン | 概要 |
|---|---|
| dashboard | Kubernetes Dashboard(Web UI) |
| metrics-server | Pod / Node のリソース使用量を収集(HPA に必要) |
| ingress | Nginx Ingress Controller |
| ingress-dns | Ingress のホスト名をローカル DNS で解決 |
| storage-provisioner | 動的 PV プロビジョニング(デフォルトで有効) |
Dashboard の起動
8.5 コマンド Tips
minikube service
NodePort や LoadBalancer タイプの Service に対して、ブラウザでアクセスするための URL を取得します。
minikube tunnel
LoadBalancer タイプの Service に外部 IP を割り当てるためのトンネルを作成します。
minikube ssh
minikube ノード(VM / コンテナ)に SSH 接続します。
Docker 環境の共有
minikube 内の Docker Daemon をホストマシンから利用できるように設定します。 これにより、ローカルでビルドしたイメージを直接 minikube で使用できます。
第 9 章:ハンズオン - アプリケーションのデプロイと公開
minikube 環境を使って、実際にアプリケーションをデプロイし、Kubernetes の主要な機能を利用してみます。
9.1 Pod と Deployment の作成
単一 Pod の作成
まずは最もシンプルな形で Pod を作成します。
Pod の状態を確認します。
Deployment による管理
本番環境では Pod を直接作成することは推奨されません。 代わりに Deployment を使用することで、レプリカ数の管理、ローリングアップデート、セルフヒーリングといった機能を利用できます。
以下のマニフェストファイル nginx-deployment.yaml を作成します。
適用して確認します。
セルフヒーリング(Self-Healing)の確認
Kubernetes の強力な機能の一つがセルフヒーリングです。 Pod を手動で削除しても、Deployment が自動的に新しい Pod を起動します。
このように Kubernetes はセルフヒーリング機能を持っており、Pod が削除された場合は自動的に新しい Pod を起動し、常に Deployment で定義したレプリカ数を保つように調整(Reconciliation)します。
9.2 Service による公開
Pod は動的に IP アドレスが変わるため、直接アクセスするのは困難です。 そこで、Service を利用することで安定したエンドポイントを確保します。
ClusterIP Service
クラスタ内部からのみアクセス可能な Service です。
spec.type に ClusterIP に設定しますが、これはデフォルトであるため、必ずしも明示的に設定する必要はありません。
ClusterIP はクラスタ内でのみアクセス可能な Service です。
そのため、ローカル環境からクラスタ内の Service に接続するためには port-forward サブコマンドを利用します。
localhost:8080 にアクセスして Nginx のウェルカムページが表示されたら ClusterIP Service での公開は完了です。
NodePort Service
NodePort は、ClusterIP の機能に加えて、各ノードの特定ポート(30000〜32767) を通じてクラスタ外部からアクセス可能にする Service タイプです。 NodePort を使用すると、エンドユーザはノードの IP アドレスを指定してアプリケーションにアクセスできるため、前述のようなポートフォワードをする必要はありません。
minikube 環境では minikube service コマンドを使用して、NodePort Service にアクセスできます。
http://127.0.0.1:58124 にアクセスして Nginx のウェルカムページが表示されたら NodePort Service での公開は完了です。
ClusterIP と NodePort の違い
| ClusterIP | NodePort | |
|---|---|---|
| アクセス範囲 | クラスタ内部のみ | クラスタ外部からもアクセス可能 |
| 公開ポート | 無し | 各ノードの 30000〜32767 番ポート |
| ユースケース | 内部マイクロサービス間通信 | 開発環境での外部公開、簡易的な外部アクセス |
| 本番環境での利用 | ○(内部通信用) | △(LoadBalancer や Ingress を推奨) |
本番環境でアプリケーションを外部公開する場合は、NodePort よりも LoadBalancer(クラウド環境)や Ingress(*後述)を使用するのが一般的です。
9.3 ConfigMap と Secret
アプリケーションの設定値や機密情報は、コンテナイメージに含めずに外部から注入するのがベストプラクティスです。
ConfigMap の作成と利用
Pod から環境変数として参照する例:
Secret の作成と利用
Pod から参照する例:
9.4 Ingress による L7 ルーティング

Ingress は、HTTP / HTTPS トラフィックをクラスタ内の Service にルーティングするための L7(アプリケーション層)ロードバランサです。 Service(ClusterIP, NodePort, LoadBalancer)が L4(トランスポート層)で動作するのに対し、Ingress はホスト名やパスに基づいた柔軟なルーティングが可能です。
Ingress Controller の有効化
Ingress リソースを利用するには、クラスタ内に Ingress Controller が必要です。 minikube では、アドオンとして簡単に有効化することができます。
サンプルアプリケーションの準備
2 つの異なるアプリケーションを用意し、Ingress でルーティングしてみます。
Ingress リソースの作成
パスベースのルーティングを設定します。
動作確認
macOS + Docker ドライバの環境では、minikube ip で取得した IP アドレスにホストから直接アクセスすることはできません。
これは Docker Desktop が Linux VM 内でコンテナを実行しており、そのネットワークがホストから隔離されているためです。
代わりに minikube tunnel を使用して、Ingress Controller にアクセスするためのトンネルを作成します。
/etc/hosts に 127.0.0.1 を追記します。
ブラウザまたは curl でアクセスします。
このように、単一のエントリポイント(demo.local)に対し、パスに応じて異なる Service にトラフィックをルーティングできます。
本番環境では、TLS 終端や認証、レートリミットといった高度な機能も Ingress で設定することが可能です。
今回は紹介しきれませんが、例えば Kubernetes の他のリソース(StatefulSet, PersistentVolume, Ingress, ConfigMap, Secret 等)を組み合わせることで以下のような Web 3 層アプリケーションを構築することもできます。
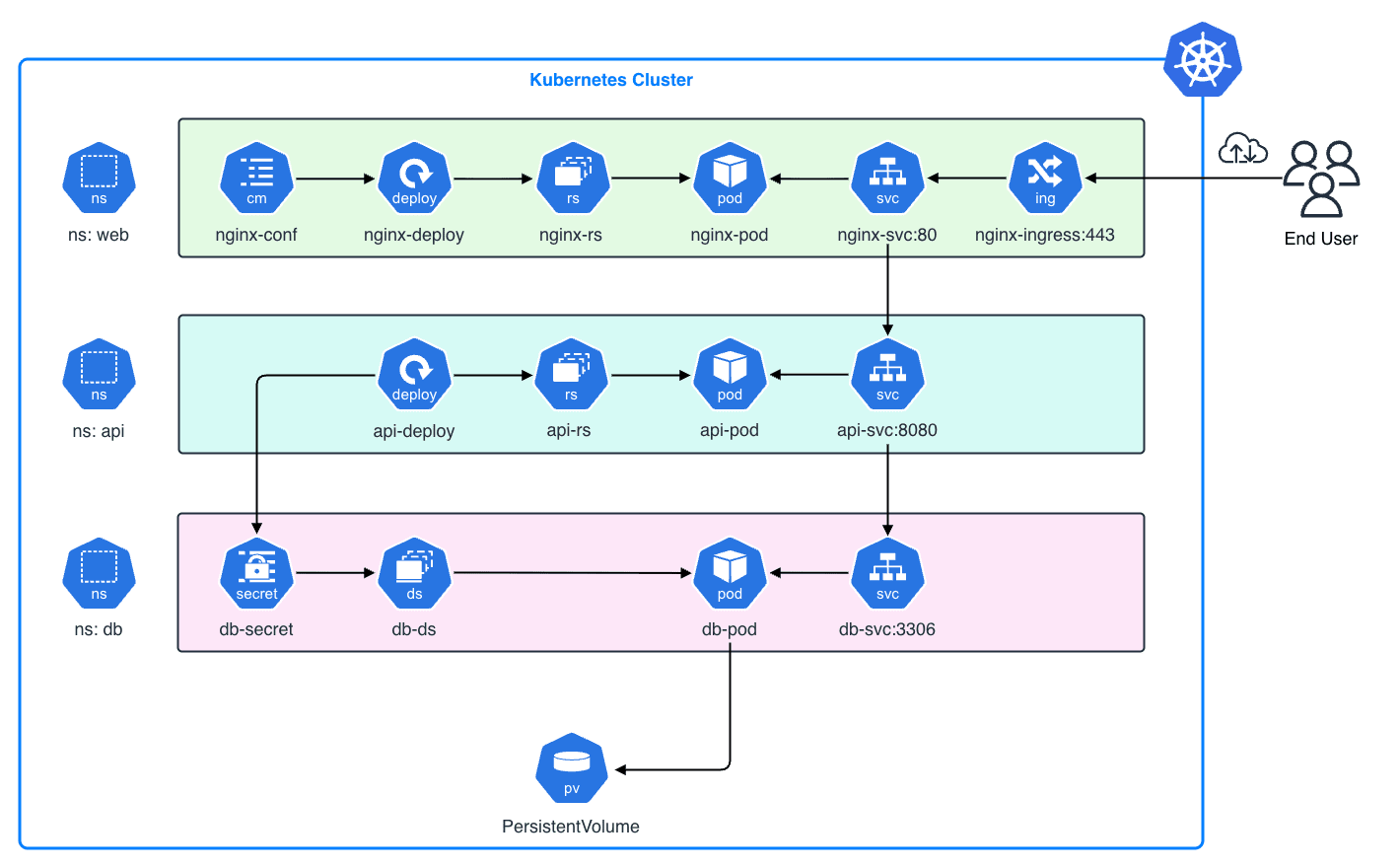
9.5 リソースのクリーンアップ
作成したリソースを削除する場合は以下のコマンドを利用します。
第 10 章:トラブルシューティング
最も基本的なエラーとその対処法をまとめておきます。
10.1 ImagePullBackOff / ErrImagePull
-
原因:イメージ名の間違い、タグが存在しない、認証情報(ImagePullSecret)の不足。
-
対処:
Eventsセクションを確認し、404 Not Found なのか、401 Unauthorized なのかを特定します。
10.2 CrashLoopBackOff
-
原因:アプリケーションが起動直後に落ちている。設定ミス、環境変数の不足、メモリ不足。
-
対処:
ログが出ていない場合は、Liveness Probe の設定が厳しすぎるか、起動コマンド(
ENTRYPOINT/CMD)が間違っている可能性があります。
10.3 Service に繋がらない
-
原因:Selector の不一致、ポート番号の間違い、NetworkPolicy による遮断。
-
対処:
-
Selector の確認:Service の Selector と Pod の Label が完全に一致しているか。
-
Endpoints の確認:
ここに IP アドレスが表示されていなければ、Pod が紐付いていません。
-
コンテナ内部からの調査:
デバッグ用 Pod を立ち上げて疎通確認します。
-
第 11 章:Kubernetes エコシステム
Kubernetes は単なるコンテナ実行基盤ではなく、CNCF(Cloud Native Computing Foundation) を中心とした巨大なエコシステムの中核です。 最後に、本番運用でよく利用される主要なツールを紹介します。
11.1 マニフェスト管理
Helm

Helm は Kubernetes のパッケージマネージャで、Linux における apt や yum に相当します。
複数のマニフェスト(Deployment, Service, ConfigMap, Ingress 等)をひとまとめにした「Chart」として管理できます。
values.yaml という設定ファイルを上書きするだけで、環境毎の差異(Dev / Prod でのレプリカ数やリソース量の違い)を吸収できるのが特徴です。
Kustomize

Kustomize は、テンプレートエンジンを使わずにマニフェストをカスタマイズするツールです。
Kubernetes v1.14 以降、kubectl のサブコマンド(kubectl apply -k)として組み込まれており、追加インストール不要で利用できます。
Kustomize は、ベースとなるマニフェストに対してオーバーレイ(パッチ)を重ねることで環境差分を吸収します。
Helm と Kustomize の違い
| Helm | Kustomize | |
|---|---|---|
| アプローチ | テンプレートエンジン(Go 等) | パッチ適用(純粋な YAML 操作) |
| 学習コスト | テンプレート構文の習得が必要 | YAML の知識だけで利用可能 |
| サードパーティ依存 | Helm CLI のインストールが必要 | kubectl に組み込み済み |
| 主なユースケース | 複雑なアプリの配布・再利用 | 単純な環境差分の管理 |
実際には、Helm Chart を Kustomize でラップする(helmCharts ジェネレータ)等、両者を組み合わせて使うケースも多いようです。
11.2 GitOps


従来は kubectl apply を CI ツール(Jenkins, GitHub Actions)から実行していましたが、セキュリティや監査の観点から GitOps という手法が主流になっています。
GitOps の基本原則は、GitHub リポジトリを「信頼できる唯一の情報源(SSOT:Single Source of Truth)」とすることです。 つまり、「GitHub リポジトリの状態 = クラスタのあるべき状態」となります。

- ArgoCD や Flux といったコントローラをクラスタ内に常駐させる
- コントローラが GitHub リポジトリを定期的にポーリング(または Webhook で検知)する
- GitHub 上のマニフェストとクラスタ内の状態に差分があれば、自動的に同期(Sync)する
これにより、kubectl コマンドを直接叩く権限を開発者に渡す必要がなくなり、オペレーションミスの防止や変更履歴の追従が容易になります。
11.3 Observability(O11y)
本番環境で Kubernetes を運用するには、何が起きているかを正確に把握する オブザーバビリティ(可観測性) が不可欠です。 オブザーバビリティは Metrics / Logs / Traces の 3 つの要素で構成されます。
Metrics:Prometheus / Grafana


Prometheus は、監視対象のエンドポイント(/metrics)からデータを定期的に Pull し、時系列データベースに保存します。
Grafana と組み合わせて可視化・アラートを設定するのがデファクトスタンダードです。
| エージェント | 概要 |
|---|---|
| Node Exporter | CPU、メモリ、ディスク I/O 等のホストレベルのメトリクス |
| kube-state-metrics | Deployment のレプリカ数や Pod の状態等 Kubernetes オブジェクトの状態 |
| cAdvisor | kubelet に内蔵され、コンテナ単位のリソース使用量を収集 |
Logs:Fluentd / Fluent Bit


コンテナのログ(stdout / stderr)は、ノード上の /var/log/containers/*.log に出力されます。
Pod が消えるとログも消えてしまうため、ログ収集エージェント(Fluentd / Fluent Bit)を DaemonSet として配置し、外部のログ基盤(Elasticsearch, Loki, CloudWatch Logs 等)に転送するのが一般的です。
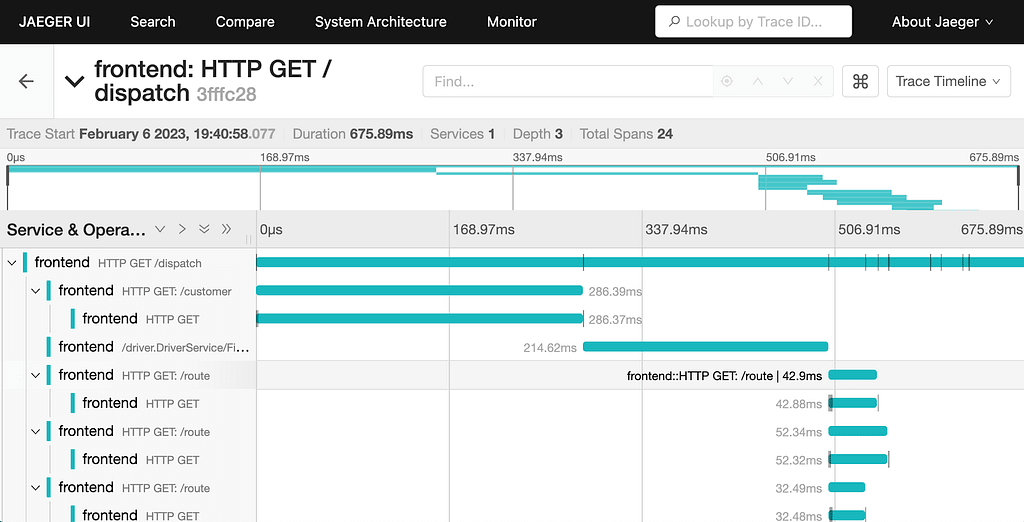
Traces:OpenTelemetry / Jaeger / Zipkin



マイクロサービスでは、1 つのリクエストが複数のサービス(Pod)を跨いで処理されます。 OpenTelemetry は、トレースデータの生成・収集の標準仕様であり、Jaeger や Zipkin と組み合わせて分散トレーシングを実現します。
11.4 Service Mesh


マイクロサービスアーキテクチャでは、サービス間の通信が複雑化します。 サービスメッシュ は、リクエスト・通信の流れをアプリケーションコードを変更せずに制御・観測するためのインフラ層です。
サイドカーパターン
サービスメッシュの基本アーキテクチャは Kubernetes の サイドカーパターン となります。 各 Pod にサイドカープロキシ(Envoy 等)を注入し、すべての Inbound / Outbound トラフィックがプロキシを経由するようにします。
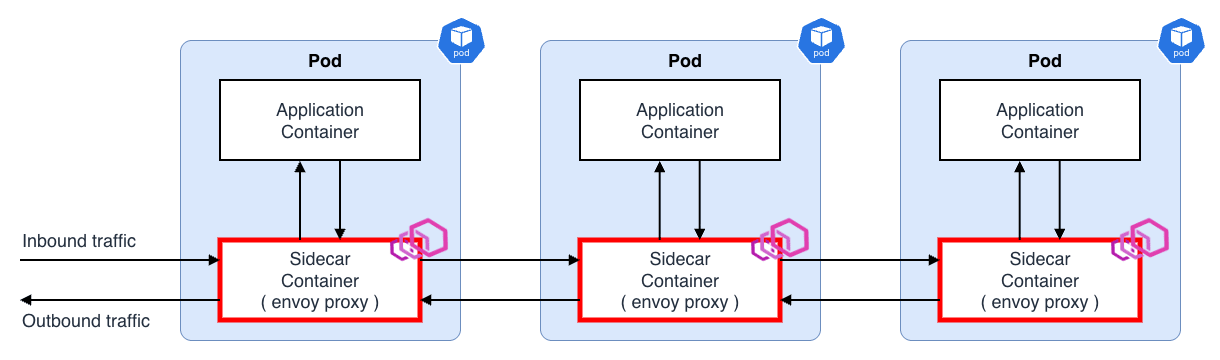
アプリケーションは localhost 宛に通信するだけで、プロキシが実際のルーティング、mTLS、リトライ、タイムアウト等を透過的に処理します。
主要機能
| 機能 | 説明 |
|---|---|
| Traffic Management | カナリアリリース、Blue/Green デプロイ、A/B テスト、トラフィックミラーリング |
| Resilience | サーキットブレーカー、リトライ、タイムアウト、レートリミット |
| Security | サービス間通信の自動 mTLS(相互 TLS)暗号化、認可ポリシー(RBAC) |
| Observability | 透過的なメトリクス収集、分散トレーシング、アクセスログ |
カナリアリリースの例
サービスメッシュを使うと、アプリケーションコードを変更せずにトラフィックを分割できます。 例えば「90% のトラフィックを v1 に、10% を v2 に」といったカナリアリリースが、インフラ層の設定だけで実現可能です。
Istio と Linkerd
サービスメッシュの代表的な実装として、Google が主導して開発された高機能な Istio と、CNCF プロジェクトで軽量・シンプルさを重視する Linkerd があります。
| Istio | Linkerd | |
|---|---|---|
| 特徴 | 高機能・多機能。エンタープライズ向け | 軽量・シンプル。導入が容易 |
| プロキシ | Envoy | linkerd2-proxy(Rust 製、軽量) |
| リソース消費 | 比較的大きい | 小さい(メモリ、CPU ともに少ない) |
| 学習コスト | 高い(設定項目が多い) | 低い(デフォルトで安全な設定) |
| mTLS | 手動設定も可能 | デフォルトで自動有効 |
| WASM 拡張 | ○(Envoy の WASM フィルタ) | ✕ |
| マルチクラスタ | ○(高度なマルチクラスタ構成をサポート) | ○(シンプルなマルチクラスタ構成) |
サービスメッシュ導入の判断基準
サービスメッシュは強力ですが、複雑さとリソースオーバーヘッドも伴います。 以下のような場合に導入を検討すると良いでしょう。
- マイクロサービスが多数:サービス間通信の可視化・制御が困難になってきた
- セキュリティ要件が厳格:サービス間の mTLS を必須にしたい
- 高度なトラフィック制御が必要:カナリアリリース、サーキットブレーカーをインフラ層で実現したい
- 統一的なオブザーバビリティ:各サービスにライブラリを組み込まずにメトリクス・トレースを収集したい
逆にサービス数が少ない場合や、シンプルな構成で十分な場合は、過剰な複雑さを招く可能性があります。
おわりに
ここまで、Kubernetes の基本概念から内部アーキテクチャ、Kubernetes のリソースやそれらの使い方について紹介してきました。
Kubernetes は非常に複雑なシステムに見えますが、一つ一つのコンポーネントが「何のために存在し、どう動いているか」を理解すれば、意外とシンプルな構造であることが分かります。 今回紹介した仕組みやアーキテクチャを理解しておくことは、Kubernetes を使ったアプリケーション開発や、効率的な開発・運用フローを考える上でも武器になると思います。
一方で、Kubernetes の進化は非常に速く、マイナーバージョンは 3〜4 ヶ月毎にリリースされます。 このサイクルの中で、API の廃止や破壊的な変更(Breaking Changes)が含まれることも珍しくありません。
わずか 1 年強でサポート期限(EOL)を迎えるため、常に最新情報を追い続け、計画的にアップデートし続けなければ、セキュリティリスクや技術的負債を抱えることになります。 そのため、キャッチアップして終わりではなく継続的な学習が必要です。
かつて、アプリケーションエンジニアとインフラエンジニアの間には、一定の壁が存在しましたが、Kubernetes の登場は、インフラをコードとして宣言的に管理することを当たり前にし、その境界線を根本的に変えました。 DevOps や SRE(Site Reliability Engineering)といった文化が真に定着し始めたのも、Kubernetes という技術的な共通基盤が確立されたことが大きく影響していると思います。
Kubernetes は、単なるコンテナオーケストレータではなく、開発と運用が同じ言葉(API)で繋がり、信頼性の高いシステムを共に作り上げるための、現代のソフトウェア開発におけるデファクトスタンダードとなっています。 これは、手順書ベースの手動管理から、コードによる宣言的な自律管理へと、インフラ運用の在り方自体も変えた革命的な技術だと思います。
本記事で紹介した内容は Kubernetes 運用における基礎中の基礎に過ぎませんが、学習の取っ掛かりとして、一助になれば幸いです。
コンテナ仮想化技術と Kubernetes の俯瞰図 - 基礎編 は こちら から読めます。
参考・引用

Kubernetes完全ガイド【電子書籍】
詳細を見る
Kubernetes完全ガイド 第2版
詳細を見る
みんなのDocker/Kubernetes【電子書籍】
詳細を見る
Docker/Kubernetes開発・運用のためのセキュリティ実践ガイド
詳細を見る
Kubernetes実践入門
詳細を見る
Linuxカーネル2.6解読室
詳細を見る