新卒研修で構築したサービス運用基盤の紹介
はじめに
SRE として 株式会社サイバーエージェント に新卒入社しました。
5 月から、配属先である 株式会社 AbemaTV にて Platform Engineer として勤めます。
弊社では、毎年新卒エンジニア研修の一環として 3 週間の短期開発にチームで取り組み、その成果や技術的アピールを発表するカリキュラムが実施されています。
今年度のテーマは『生成 AI を用いた SNS』となっており、私のチームでは、AI によって生成された画像を共有し合う SNS アプリケーションとして『BeauBelle』というサービスを提案・開発しました。
今回、私は Platform Engineer / SRE としてインフラ構成や運用基盤整備をメインで担当し、開発したサービスをデプロイまで持っていくことを個人ミッションとしていました。
開発研修の最終日には、メンター陣や先輩社員を招いた成果発表を行い、僕たちのチームは インフラ部門において技術賞 を頂きました。
今回のブログでは、開発したサービスと実際に構築した運用アーキテクチャについて設計思想や技術選定を交え紹介したいと思います。
テーマ
- 概要
- 15 チーム(各チーム 7-8 名構成)に分かれて『生成 AI を用いた SNS』を開発

- 15 チーム(各チーム 7-8 名構成)に分かれて『生成 AI を用いた SNS』を開発
- レギュレーション(以下の要件を備えた SNS サービス)
- 【必須】全チーム必ず満たす
- 機能要件
- ユーザ登録 / 投稿 / 投稿の参照 / いいね・リポスト / フォロー
- 画像 / アプリ内(サイト内)通知
- 非機能要件
- サーバ・クライアント間の API 通信に関して妥当性(根拠)のあるパフォーマンス改善を実施
- 何らかの形で AI を活用すること(※ 機能として導入しても可とする)
- セキュリティ面を考慮した設計
- 機能要件
- 【オプション】自由に機能を実装して可
- 機能要件
- 外部連携でのログイン機能 / 動画 / トレンド・キーワード分析
- 音声入力と文字起こし / スペース機能
- 非機能要件
- 「可用性・運用の観点での工夫」についてのアクション
- 脆弱性診断の実施
- 機能要件
- 【必須】全チーム必ず満たす
- 稼働日数
- 3 週間 14 営業日
- 評価軸
- アイデアではなく技術や開発プロセスを重視
- 設計した目標・機能に対してどれだけ達成できているか
- AI を如何に活用できているか
BeauBelle とは
概要
BeauBelle は AI で簡単に画像を生成できるようになった今 "理想の美" を追求し、共有し合うことをコンセプトとした SNS です。
例えば、日常会話で「どんな人がタイプ?」という質問に対して返ってくるのは「綺麗系」や「可愛い系」「犬系・猫系女子」「ロングヘア」等、抽象的な表現が多く、伝わりずらいことがよくあります。
そんな時、写真・画像があれば自分の好みのタイプをより具体的に伝えることができるでしょう。
BeauBelle は、AI によって生成した女性をコレクションして、美女図鑑を作ることで理想のタイプを見つけ出すことができます。 また、自分が理想とする女性の画像を生成して共有することもできます。

現在のマッチングアプリは自分から行動を起こす能動体系のサービスが多いですが、今後は理想の女性(好みのタイプ)を登録しておき、AI によって自動的に相性の良い二人をマッチングさせる受動体系のサービスも普及することが予想されます。(バチェラーデート 等)
BeauBelle は画像に特化したマッチングアプリとして機能し、さらなるサービス拡張も目指しています。
機能
14 日間で実装を完遂できるミニマムの機能として以下を定義しました。
- いいね・スーパーライク(ビジョコレ)
- 左右にスワイプして次々に出現する美女画像を評価することで理想の女性をコレクション(美女コレクションを作る)することができる
- ポスト(ビジョシェア)
- 好みのタイプの美女画像を生成して投稿することができる
- フォロー・フォロワー(ビジョマイニング)
- 好みの美女をポストしているユーザをフォローしておくことで理想の女性を発見(美女発掘)しやすくなる
- 公序良俗の維持
- 投稿時に BeauBelle AI が不適切画像(露出度, 美女に関係の無い投稿, ...etc.)を除去
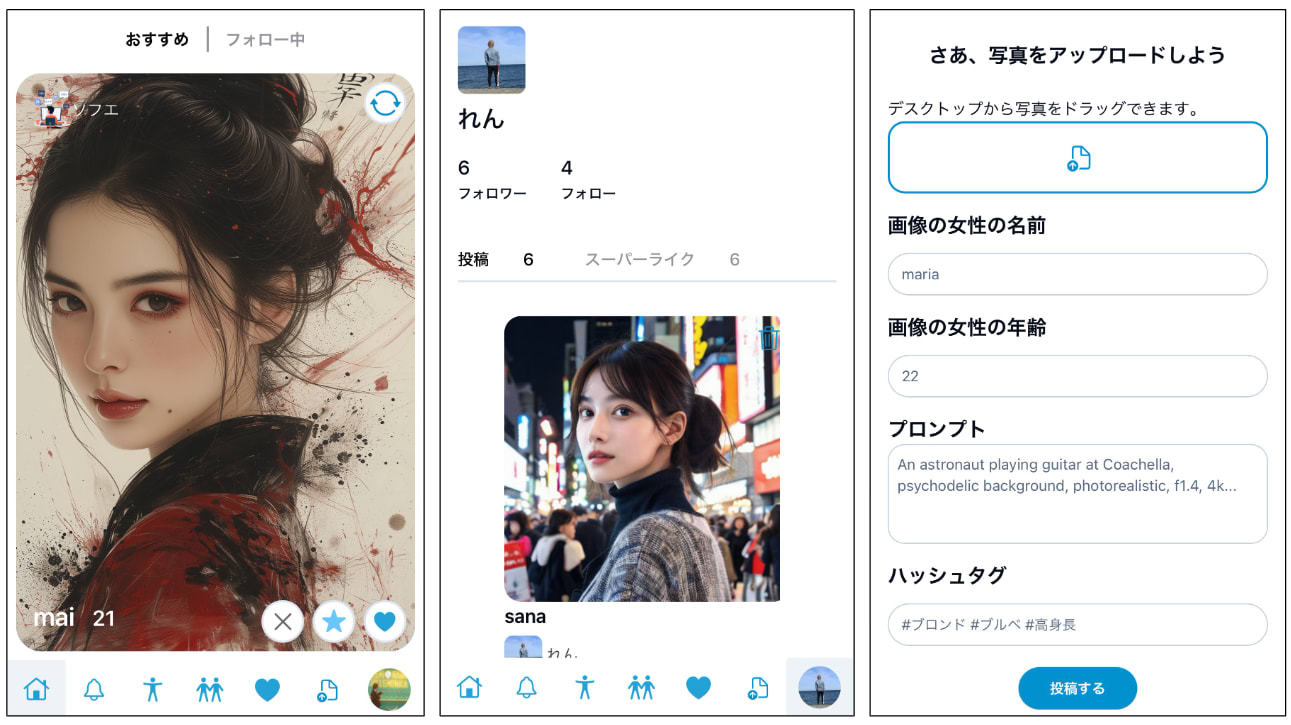
UI/UX
デプロイしたサービスの UI/UX を一部紹介します。 BeauBelle はレスポンシブ対応をしており、スマホで利用することもできます。
PC 版


スマホ版
チーム編成
| ドメイン | メンバー |
|---|---|
| WEB フロント | 3 人 |
| バックエンド | 3 人 |
| ML | 1 人 |
| Cloud Platform / SRE(👈 担当) | 1 人 |
技術スタック
簡単に BeauBelle を構成する技術スタックと実装ポイントについて紹介します。
各ドメインに属するメンバーが最も得意とする言語・技術を、責任を持って使用し、共有・浸透させ合うことでチームとしてレベルアップを図る というコンセプトの元、選定・設計を行いました。
WEB フロント


- FW:Next.js v14.1
- ルーティングエンジン:App router
- 認証ライブラリ:NextAuth v5(beta)
- データフェッチ:SWR(Stale-While-Revalidate)
- バリデーション:zod
- UI/UX:shadcn, Storybook
BeauBelle WEB フロントの詳細(NextAuth v5 周り)については こちら のブログで詳しく紹介されています。
バックエンド


- FW:Ruby on Rails v7.1
- マイグレーション:Active Record
- 非同期処理:Active Job
- DB:MySQL 8.0(RDBMS)
- ローカル環境:Docker Compose v2
- ローカルストレージ:MinIO
ML(画像分析)


- 推論エンドポイント生成:Amazon SageMaker
- 学習モデル管理:Amazon ECR
- イベント発火:Amazon Lambda
- 投稿画像管理:Amazon S3
Cloud Platform / SRE(運用基盤)


- 運用基盤
- Kubernetes v1.29(Amazon EKS)
- コード化
- IaC:Terraform, CloudFormation
- CaC:Shell Script, Makefile
- マニフェスト管理:Helm, Kustomize
- DevOps
- CI:GitHub Actions(Workflows), Atlantis
- CD:ArgoCD
- Telemetry
- Monitoring:kube-prometheus-stack(Prometheus, Grafana)
- Logging:efk-stack(Elasticsearch, Fluentd, Kibana)
クラウドプラットフォーム・運用構成
実際にサービスを運用するために構築したインフラ構成について紹介します。
BeauBelle の運用基盤(以下、BeauBelle Ops と記述)は、サービスの成長を視野に入れ、将来における拡張性や運用の柔軟性を考慮した エコシステム を構築するために Kubernetes(EKS)を採用しました。

設計思想
運用基盤の構築に伴い、特に非機能要件に着目をして、ミニマムで完遂できるタスクリストを洗い出しました。
- Cloud Platform(開発期間 前半で実施)
- 可用性
- 冗長構成
- 負荷分散と水平スケーリング
- セキュリティ
- OIDC
- NextAuth v5 を EKS に組み込む
- 可用性
- SRE(開発期間 後半で実施)
- Developer Experience
- 開発の足を止めないための仕組み作り
- 迅速なデプロイの実現と属人化の防止
- Developer Safety
- 責務の境界を明確にした処理設計
- Immutable Infrastructure
- モニタリング基盤の整備
- サービス拡張性を見据えた IaC 設計
- Developer Experience
Cloud Platform
可用性
冗長構成

運用基盤は 3AZ で冗長化することで可用性を担保しています。
EKS はセキュリティの観点からプライベートクラスタとして構築しているため、全てのワーカノードはプライベートサブネットに配置されています。 ノードプールは EC2 ON_DEMAND インスタンスを用いて ASG(Auto Scaling Groups)を構成しています。
また、ON_DEMAND インスタンスは稼働時間による従量課金制となるため、開発をしない深夜帯や土日は Auto Scaling Scheduler を用いて ASG を制御することでコストを抑えました。
負荷分散と水平スケーリング
全てのワーカーノードはプライベートサブネットに配置しているため、ALB が受信したユーザリクエストは直接 Pod に届きません。 そのため、リクエストをプライベートサブネットにルーティングするには ALB に対して各 AZ のパブリックサブネットを紐付ける必要があります。

また、リクエストを受けた Pod は CPU 使用率を指標として、HPA(Horizontal Pod Autoscaler)による水平オートスケーリングを実行します。
これにより、リクエストを 3AZ で分散しつつ、Pod の処理負荷が上昇した場合は、自動的にスケールを実行して平準化するようにしています。
セキュリティ
OIDC
ID・Pass 認証は一切避け、OIDC を使用したコンポーネント間接続を目指しました。
パスワード認証と比較し、短命なトークンを利用した認証方式を採用することで、セキュリティの向上を図るとともに、管理コストも下げる目的があります。
特に、EKS には IRSA(IAM Roles for Service Accounts) という仕組みが用意されており、AWS 側で定義した IAM Role を EKS OIDC Provider を介して Kubernetes Service Account に紐付ける機能があります。

BeauBelle では、画像投稿時にバックエンドが S3 Presigned URL の発行を行うために、Pod から AWS マネージドサービスにアクセスする必要があるので、S3 へのアクセスを定義した IAM Policy を準備して Pod に付与します。 これにより、Secret Key を Pod に設定することなく AWS リソースにアクセス可能となります。
また、IRSA はローカルの開発環境(Docker Compose)では利用できないため、MinIO を S3 互換のオブジェクトストレージとして別途構築し、ID・Pass 認証を使用しました。
起動時に、Rails.env によって実行環境を判断し、IRSA を使用するか否かを決定しています。
NextAuth v5 を EKS に組み込む
BeauBelle では、ログイン機能の実装において、認証ライブラリとして NextAuth.js を使用し、認可サーバ(ID Provider)には Amazon Cognito を使用しました。
| コンポーネント | 実装 |
|---|---|
| クライアントアプリケーション | NextAuth v5 |
| 認可サーバ(ID Provider) | Amazon Cognito |
OAuth 2.0 では、認証を行う過程で、認可サーバが発行したアクセストークンをクライアントアプリケーションに返送するためのコールバック URL が必要です。
OAuth 2.0 プロトコルに基づく認証・認可の仕組み については こちら のブログでも紹介しています。
一般に、コールバック URL はアプリケーションの URL で、NextAuth をアプリケーションクライアントとして使用する場合は、[アプリケーション URL]/api/auth/callback/cognito となります。
ただし、Cognito(OAuth 2.0)では、コールバック URL は localhost を除き、https 通信のみを許可する 仕様となっています。
Amazon Cognito requires that your redirect URI use HTTPS, except for http://localhost, which you can set as a callback URL for testing purposes.
従って、ローカル環境では、例えば、以下のようなエンドポイントが使用できても、本番環境(クラスタネットワーク)では使用することができません。
これは、本番環境では、EKS クラスタ前段に存在する ALB までは HTTPS 通信となる一方で、クラスタ内(ALB からのトラフィックルーティング)はデフォルト HTTP 通信となるため、OAuth 2.0 の認証フローに反するからです。(いわゆる SSL 終端 というやつです)

その結果、本番環境では、ユーザがログイン画面から遷移することができなくなり、EKS にデプロイした NextAuth 側では warning が発生する問題が生じます。
似たような Issue はいくつか挙げられていました。
ALB を介して EKS に流入したリクエストは、Kubernetes の Service Discovery によってクラスタネットワークでのみ有効な IP アドレスに解決されます。
そのため、NEXTAUTH_URL に指定したドメインではなく、Pod の IP アドレスが送信元 IP(SIP)として使用されることで、上記のメッセージが表示されます。(この時、ユーザ画面では undefined パスへリダイレクトされる挙動となります)
対処方法として、NextAuth の実装 にあるように、trustHost: true を指定することで、クラスタ内の通信を全て信頼できるものとして許可することができます。
- NextAuthConfig の options 実装
この方法はクラスタ内の通信に一切のアクセス制限を設けないため、セキュリティ上課題が残ります。
ALB では SSL 終端を実装することができますが、クラスタ内ネットワーク(Service - Pod 間 等)では適用できないため、NextAuth v5 を EKS で使用する際に、どのように対処することがベストプラクティスなのか、明らかになっていません。
SRE
Developer Experience
開発者体験(DX:Developer eXperience)の向上を図るために、迅速なデプロイの実現と属人化の防止を目指しました。
デプロイの属人化が発生すると、リリース依頼を投げるオーバーヘッドが発生し、リリースを行う開発者も一度開発の手を止める必要が出てきます。 今回、14 日間という短い期間での開発だったので、WEB フロントエンジニアやバックエンドエンジニアも開発したコードを即座に本番環境に反映できる迅速な DevOps サイクルが必要だと考えました。
そこで、CI/CD の構築において、次の Must 条件を立てました。
- 誰でもデプロイできること
- デプロイに伴って特別な手順(コマンドラインの実行)を踏まないこと
- デプロイ結果を可視化できること
BeauBelle では、CI に GitHub Actions を、CD には ArgoCD を採用しました。
GitHub Actions は、特に GitHub Workflows を用いてボタン一つでデプロイできるようにしています。

また、開発者は ArgoCD の WEB UI からデプロイの実行結果およびログやリソースの状態を確認できるようにしています。

デプロイは次の手順で行われます。
CI/CD パイプライン

- 開発者は GitHub Workflows からデプロイを発火
- コードビルドしてコミットハッシュでタグを付与し、コンテナレジストリ(ECR)にアップロード
- 2 と同様のコミットハッシュで HelmChart のイメージタグをオーバーライド
- ArgoCD がマニフェストの変更差分を検知
- HelmChart(マニフェスト)を元に、対象の Docker イメージを ECR から取得してデプロイ
[env]-image-tags.yaml- Helm テンプレートにおいて、Docker イメージ ID を指定する箇所を切り出して単一のマニフェストとして管理
Developer Safety
責務の境界を明確にした処理設計
実際のサービス運用を想定すると、障害や不具合が発生した際に "誰が(どのドメインが)どこを見に行くのか"、"どこが責任を負うのか" というコンポーネント管理を考慮しておく必要があります。
責務の境界を明らかにしておく ことで、サービスに不具合が生じた際に、迅速な原因の切り分けや、トラブルシューティングの実施に繋げることが可能と考えました。
今回は開発期間も限られているため、最低限の責務分離モデルを設計してチームで共有しました。
BeauBelle では、ユーザが画像を投稿した際に、公序良俗判定を行うフローが存在します。
この機能を最も簡単に実装する場合、例えば、WEB フロントと ML がやり取りをすることで、画像の投稿受付・格納、分析処理を完結することができます。

しかし、簡易的な設計には、次のような課題があります。
- WEB フロント
- 【WANT】:画像格納のために S3 にアクセスする必要がある
- 【ISSUE】:バックエンドも S3 へのアクセスが必要になった場合、フロントエンドとバックエンドの双方にアクセスロールを付与する必要があるため権限管理が煩雑になる
- ML
- 【WANT】:画像データの格納のために DB へのアクセスが必要
- 【WANT】:WEB フロントに処理結果を通知するための API を生やす必要
- 【ISSUE】:ML はあくまで画像分析を行うことが主なミッションなので、基幹となる API や DAO を生やすのは、責務に反する(機械学習以外に考えなくてはいけないことが多くなる)
ここで、各ドメインの責務を考えて整理します。
- WEB フロント
- 【何をするか】:ユーザから投稿画像を受け付けるのみ
- 【何をしないか】:S3 へのアクセスに伴う複雑な権限制御
- バックエンド
- 【何をするか】:WEB フロントおよび ML に基幹 API(他コンポーネントと連携するために定常的に使用される API)を提供
- 【何をするか】:DAO(Data Access Object)の管理
- 【何をしないか】:ユーザからの投稿画像(バイナリデータ)は持たない → オブジェクトパスとして扱う
- ML
- 【何をするか】:画像分析のみに集中
- 【何をしないか】:DB アクセスや WEB フロントへの API 提供
これに基づき、画像投稿に伴う公序良俗判定フローに、API および DAO の提供を行うバックエンドを追加して再定義します。

- WEB フロント
- ユーザから投稿画像を受け付けるのみ
- Presigned URL を使用して画像を格納
- バックエンド
- S3(Presigned URL 発行)や DB へのアクセス(DAO 管理)
- 判定結果の通知やリクエストに使用する基幹 API の管理
- ML
- 画像分析機能のみを提供
- 処理結果判定の通知に使用する最低限の API のみをバックエンドに向けて用意
以上のように、責務の境界を明確にした上、処理を各ドメインで分離することにより、自身が所属する領域の作業に集中することができます。 同時に、運用において発生する不具合の原因調査やコードの修正にもあたりやすくなります。
また、明確にリソースへのアクセス制御(RBAC / ABAC)を設けることで、最小権限の原則(PoLP:Principle of Least Privilege) 遵守にも繋がります。
Immutable Infrastructure
Immutable Infrastructure(不変的インフラ)の概要については こちら の記事が分かりやすいと思います。
モニタリング基盤の整備
Cloud Native Immutable Infrastructure Principles に則り、リソース過剰消費の抑制、高効率なインフラ運用を目指すべくモニタリング基盤も導入しました。 今回は、OSS として提供されている kube-prometheus-stack で構築しました。
kube-prometheus-stack とは、Prometheus や Grafana、Thanos、メトリクスエクスポータツールをオールインワンで提供してくれる Kubernetes 用のモニタリングツールです。

kube-prometheus-stack が提供する Grafana には、予めいくつかのダッシュボードが用意されており、必要に応じてパラメータを変更して使用します。 CPU やメモリといったコンピュートリソースの使用率や、API の応答速度を中心に、ダッシュボードを整備しておくことで、将来的に Capacity Planning 等にも役立てることが可能です。

Terraform の構成
BeauBelle Ops は 99% Terraform で構築しました。 一度構築したインフラは変更しないという Immutable Infrastructure に則り、将来におけるサービスの拡張を前提としたディレクトリ構成を意識しています。
主に、modules ディレクトリを中心に platform および services ディレクトリで拡張します。
platform は、サービス運用に必要となるマネージドサービス、および IAM 等のロール、ポリシを管理します。 services は、platform を利用して動作するサービスを定義します。 例えば、GitHub Actions における OIDC 連携の設定等が services に含まれます。
また、マルチクラウド展開を想定して各プロバイダを直下で切っておき、その下で実行環境を定義します。 EKS や RDS 等、リージョナルリソースの場合は、さらにその下で必要に応じてリージョンを定義します。
基本的には Terraform modules で管理しておき、パラメータ設定を platform と services において Terraform resources で定義します。
Terraform resources のファイル構成は以下のようにしています。
また、tfstate 自体の管理は Terraform で行わないことがベストプラクティスとされているため、今回はシンプルに Shell Script で作成しました。 AWS なら CloudFormation や Cloud Development Kit(CDK) を使用しても良いかもしれません。
Terraform is an administrative tool that manages your infrastructure, and so ideally the infrastructure that is used by Terraform should exist outside of the infrastructure that Terraform manages. This can be achieved by creating a separate administrative AWS account which contains the user accounts used by human operators and any infrastructure and tools used to manage the other accounts. Isolating shared administrative tools from your main environments has a number of advantages, such as avoiding accidentally damaging the administrative infrastructure while changing the target infrastructure, and reducing the risk that an attacker might abuse production infrastructure to gain access to the (usually more privileged) administrative infrastructure.
以上のような構成を取ることで、実行環境の追加やマルチクラウド展開をする場合でも、既存のコード設計を変更することなく、拡張していくことが可能です。
まとめ
良かったこと
今回の開発では、実際に手を動かして様々な技術的挑戦をすることで、非常に多くの知見を得ることができました。 また、普段は触らないドメイン外の技術に触れたり改善に取り組んだりすることで新たな知見を得ることができました。
ミッションとして掲げていた、"デプロイを完遂する" に対しては、早い段階での運用基盤整備、DevOps を浸透することで、開発と運用のサイクルが周り、無事デプロイまで辿り着くことができました。 メンター陣や先輩社員を招いた最終成果発表では、インフラ部門において技術賞 も獲得することができて、非常に良い結果を残せました。
大変だったこと
スケジュール管理
工数やスケジュールを管理するのは非常に大変だと実感しました。 実際に開発が始まると、目の前の作業に集中してしまうことで、先々の見通しまで立てる余裕が無くなり、後から俯瞰した時に、考慮漏れや連携がうまくいかない、なんてことが発生しがちです。 常にチームメンバーとのコミュニケーション、タスク状況の共有を心掛け、朝夕会の場での進捗報告や方向性の擦り合わせが、非常に重要になることを実感しました。
アジェンダを整備して、毎日のミーティングをファシリテーションしてくれたメンバー(PM)には本当に感謝です!
また、思わぬバクが発生する可能性も視野に入れて、バッファを設けたリリーススケジュールを設定していくことが重要だと思いました。 ガントチャートやスプリント、カンバン等を活用して、開発計画を入念に練ることで、心理的安全性やスケジュールに沿った工数見積もりを行うことでサービスを安定して開発していけるのだと思いました。
限られた時間の中で開発するからこそ、スケジュール管理を意識するべき だと実感しました。
目標設計
開発当初に立てた個人目標(定量面・定性面)を振り返ってみるとかなり乖離している部分がありました。
最も、100% 目標設計と結果が重なれば良いのですが、先々の見通しが立たないうち(サービスの全体像が霞んでいる、必要な機能が不明瞭)や、経験が浅いうちは、これはかなり厳しいと思いました。 なので、毎日の振り返りで、目標設計と今取り組んでいることがズレてきていないかを確認して、目標設計を都度見直していくことが重要だと思いました。
また、トレーナーやチームメンバーとも擦り合わせ・共有を密にしておくことで、より納得のいく結果や評価に繋げられるのではないかと思います。
今後の方針
1 年目は インプット 3 : アウトプット 7 の割合(とにかくアウトプットを重視)を意識していきたいと思います。
言語化したり人に説明をしたりすることで、インプットした内容を自分の中で定着させるとともに、周りからの評価にも繋げたいという思いがあります。
また、成長角度を上げるためにも、"開発 < 目標設計" で詰めていきたいです。
最後に
チームメンバーのみんな 3 週間 本当にありがとう!
めちゃくちゃ充実した開発研修になりました!
