Endpoints の非推奨化と EndpointSlice 移行
はじめに
Kubernetes v1.33 では長らく利用されてきた Endpoints API が正式に Deprecated となり、EndpointSlice API が標準化されます。
The EndpointSlices API has been stable since v1.21, which effectively replaced the original Endpoints API. While the original Endpoints API was simple and straightforward, it also posed some challenges when scaling to large numbers of network endpoints. The EndpointSlices API has introduced new features such as dual-stack networking, making the original Endpoints API ready for deprecation.
Endpoints / EndpointSlice はどちらも Pod のネットワークエンドポイントを管理するための API です。
Endpoints を参照するコンポーネントが存在する場合、どのような影響があるのかについて理解しておく必要があります。
例えば、Endpoints から EndpointSlice に移行すると、API グループが core から discovery.k8s.io に変わるため、カスタムコントローラはじめ client-go を利用している場合は、実装そのものを修正する必要があります。
また、v1/Endpoints を直接 get / watch / list するコンポーネントの場合、必要に応じて RBAC を修正する必要があります。
今回のブログでは、Endpoints と EndpointSlice の違いや、移行することにどのようなメリットがあるのかについて紹介したいと思います。
Endpoints
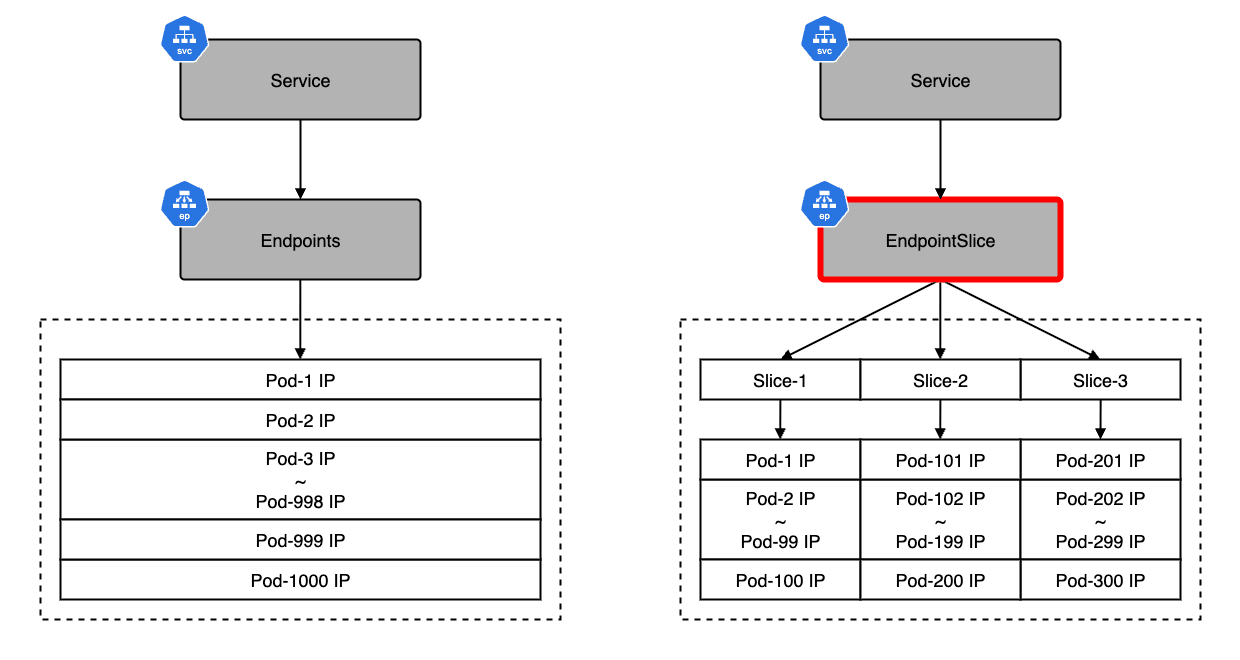
Endpoints は Pod のネットワークエンドポイントを管理するための API です。 Endpoints は『Service → Pod』の一覧を単一オブジェクトで保持しており、Service リソースと連携して動作することで、リクエストを適切な Pod へルーティングします。
kube-proxy や CoreDNS はこのオブジェクトを監視することで、ノード上の iptables / ipvs rule または eBPF を更新します。
Endpoints リソースは Service リソースを作成すると自動的に生成・管理されます。 これは Deployment から ReplicaSet が自動的に作られるのと同様、普段は Endpoints を意識したり、直接操作したりすることはほとんどないかと思います。
Endpoints の問題点
Endpoints についてはいくつか問題点が挙げられていますが、大きく以下の 3 つになります。
1. スケーラビリティの課題
Endpoints は 1 Service = 1 Endpoints オブジェクト で、その中に全エンドポイント(Pod IP や Port)が集約されます。 そのため、Endpoints が巨大化すると、etcd の KV サイズ上限に抵触したり、更新頻度が高い場合には書き換え負荷が高くなったりします。
クラスタが大規模化すると、Service 毎に単一の Endpoints オブジェクトを使う方式では効率良く扱うことができなくなります。
2. クラスタ全体の負荷高騰
Endpoints は単一オブジェクトに集約されるため、頻繁な変更は単一のホットスポットを生みます。 これにより、更新競合や、大規模クラスタでは Control-Plane(kube-apiserver / etcd)の負荷が問題視されます。
また、Endpoints が更新されると、kube-proxy 等 Data-Plane 側のコンポーネントもオブジェクトの変更通知を受け取ることになります。 つまり、Endpoints のサイズが大きくなるほど、kube-proxy の再計算コストは増大し、これによって CPU 負荷やネットワーク帯域の浪費が発生します。
3. Dual-Stack 環境 / Topology Aware Routing の未サポート
Endpoints は IPv4/IPv6 デュアルスタック環境や、Topology Aware Routing(同ゾーン優先ルーティング)といった、現代の Kubernetes に求められる高度なネットワーキング機能をサポートするための拡張性がありません。
これらを実現するには IP アドレスだけでなく、その IP がどのゾーンにあるか(トポロジ情報)やアドレスタイプといったメタデータが必要ですが、Endpoints API の単純なリスト構造にはそれらを含める余地がありません。
無理に実装しようとすると、API サーバへの追加問い合わせ(N+1 問題)が発生し、パフォーマンスが悪化することが懸念されたため、新しい API である EndpointSlice でのみサポートされることになりました。
余談ですが、Gateway API 等も、現在では EndpointSlice の利用が前提となっています。
EndpointSlice
EndpointSlice API は、Endpoints API が持つスケーラビリティや機能的な制限を根本的に解決するために設計された Service Discovery API です。
EndpointSlice は core v1 から完全に分離された discovery.k8s.io API グループとして実装されています。
Endpoints API は単一のオブジェクトで全ての Pod IP を管理していたため、大規模環境での負荷や更新効率に課題がありました。 対して EndpointSlice API は、エンドポイント情報を複数の Slice(Shard)と呼ばれる単位に分割して管理します。
これにより、以下のようなメリットが生まれます。
Sharding によるスケーラビリティ向上
基本 100 個のエンドポイントを 1 つの Slice として分割管理(Sharding)することで、数万規模の Pod を持つ Service でも etcd のサイズ制限に抵触することなくスケールできます。
差分更新による負荷軽減
変更があった Slice だけを更新・通知すれば良いため、kube-apiserver(Control-Plane)や kube-proxy(Data-Plane)の負荷が大幅に削減されます。
柔軟なメタデータの付与
IPv4/IPv6 デュアルスタック対応や、各エンドポイントへのトポロジ情報(Zone / Node)の付与が可能となり、高度なルーティングが実現でます。
Endpoints と EndpointSlice の比較
| Endpoints | EndpointSlice | |
|---|---|---|
| API グループ | core/v1 | discovery.k8s.io/v1 |
| データ構造 | Service = Object | Service = Slices |
| 更新機構 | 全体を常に更新(Full) | 変更分のみ更新(Partial) |
| スケーラビリティ | 低い(etcd 上限抵触リスク有) | 高い(Sharding 対応) |
| クラスタ負荷 | 非常に高い | 低い |
| IPv4/IPv6 Dual-Stack | 限定的(ハックが必要) | ネイティブサポート |
| Topology Aware Routing | 非対応 | ネイティブサポート |
| サポート状況 | Deprecated(v1.33+) | Stable(Standard) |
Endpoints は小規模でシンプルな環境では機能していましたが、Kubernetes が大規模化し、マルチクラウドやハイブリッドクラウドといった複雑なネットワーク要件が求められるようになるにつれ、その設計の古さがボトルネックとなりました。
EndpointSlice への移行は、単なる API の置き換えではなく、Kubernetes クラスタ全体のパフォーマンスと拡張性を底上げするための重要な手段と言えます。
移行における注意点
最後に Endpoints から EndpointSlice への移行に際して、考慮しておくべきポイントをまとめておきます。
基本的に Kubernetes のコアコンポーネントは自動的に対応しますが、ユーザ自身が管理するツールや設定は確認しておいた方が良いでしょう。
Legacy Controller / Service Mesh の確認
古いバージョンの Ingress Controller や Service Mesh(Istio, Linkerd 等)、自作の Operator が v1/Endpoints API を直接 watch している場合、これらのコンポーネントが EndpointSlice に対応しているか、最新バージョンへアップデート済みかを確認する必要があります。
Custom Scripts / Automation の修正
運用で使用しているスクリプトで kubectl get endpoints を実行して IP を抽出したり、API を直接叩いて Endpoints リソースを操作している処理がないかを見直す必要があります。
もし存在する場合は、discovery.k8s.io/v1 EndpointSlice を参照するようにロジックを書き換える必要があります。
client-go を利用している場合は、実装そのものを修正する必要があります。
- Endpoints API(非推奨)
- EndpointSlice API(推奨)
モニタリングメトリクスの変更
Prometheus や Grafana で Endpoints に関連するメトリクス(例:kube_endpoint_*)を監視している場合、これらは非推奨マーク・削除される可能性があります。
EndpointSlice 用の新しいメトリクス(例:kube_endpoint_slice_*)へダッシュボードやアラート設定を移行する必要があります。
RBAC(API Permissions)の更新
ClusterRole や Role で endpoints リソースに対する権限(get, list, watch)のみを付与している ServiceAccount がある場合、そのコンポーネントが EndpointSlice を利用し始めると権限エラー(Forbidden)が発生します。
新に discovery.k8s.io API グループの endpointslices リソースに対する権限を追加する必要があります。
コミュニティの移行計画
KEP-4974 によれば、Endpoints の廃止(Deprecation)は単に機能を削除するのではなく、以下の 4 段階 に分けて慎重に進められる計画です。
Phase 1:API レベルでの非推奨化(v1.33+)
v1.Endpointsが Deprecation としてマークされる- ドキュメントやブログ等で周知が開始される
- ユーザが Endpoints を操作すると以下の Warning メッセージが表示される
Kubernetes が既存の API を Deprecation としてマークする仕組みについては こちらのブログ で紹介しています。
Phase 2:内部コンポーネントの完全移行
- Kubernetes 内部のコンポーネント(API Server の Aggregation レイヤ)が完全に EndpointSlice を使用するように更新される
- E2E テストが整備され、Endpoints Controller を無効化した状態でもクラスタが正常に動作することが検証される
Phase 3:Conformance Test からの除外
- 将来的には、Endpoints Controller や Mirroring Controller(Endpoints を元に Slice を作る、またはその逆の同期を行う機能)が必須要件(Conformance)から外れる
- これによりクラウドプロバイダやディストリビューションによっては、デフォルトで Endpoints Controller を無効化(停止)する構成が可能になる
Phase 4:エコシステムの移行完了
- コミュニティ全体での移行が進んだ段階で、Endpoints Controller を無効化することが推奨されるデフォルト設定としてドキュメント化される
- 最終的には、管理者が明示的に有効化しない限り Endpoints オブジェクトが生成されない世界を目指す
現時点(v1.33)では、まだ Endpoints API 自体が削除されるわけではなく、自動生成も停止されませんが、今後の方向性としては確実に Endpoints からの脱却が目指されていると言えます。
まとめ
今回のブログでは、Kubernetes v1.33 で非推奨となる Endpoints API から、標準となる EndpointSlice API への移行について紹介しました。
EndpointSlice は、大規模クラスタでのスケーラビリティ問題を解決し、IPv6 や高度なルーティング機能にも対応するために設計された強力な API です。 Endpoints API の廃止は、Kubernetes がより大規模で複雑なネットワーク環境に適応するための必然的な対応と言えます。
移行によって得られるパフォーマンス改善や安定性は非常に大きなメリットですが、ユーザ側では既存のコントローラや監視設定、RBAC の見直しが必要になります。 既存のサービスや運用ツールが予期せぬ影響を受ける前に、早めの確認と移行準備を進めておくことをお勧めします。