Alerting on SLOs:6 つの戦略で学ぶアラート設計
はじめに
CPU 使用率 > 80%、エラー数 > N 件といった、閾値ベースのアラートはユーザ影響との相関が薄く、ノイズの原因になりやすい設計です。
一方で、ノイズを減らすために閾値を緩くすると、今度は Error Budget を着実に消費する緩やかな劣化を見逃します。
SLO ベースのアラートは Error Budget がどれだけの速度で消費されているか を監視することで、この問題に対処します。 Google SRE Workbook の Chapter 5: Alerting on SLOs では、このアプローチを 6 つの戦略で段階的に説明しています。
今回のブログでは、Alerting on SLOs の内容に基づき、6 つの戦略を Precision・Recall・Detection Time・Reset Time の 4 属性で順に比較しながら、なぜ Multiwindow / Multi-Burn-Rate 戦略が推奨されるのかを整理してみたいと思います。
SLI・SLO・Error Budget の基礎概念については こちらのブログ で紹介しています。
アラートを評価する 4 つの属性
アラート戦略の良し悪しを判断するために、Google SRE Workbook では 4 つの属性を定義しています。
| 属性 | 概要 | 悪いとどうなるか |
|---|---|---|
| Precision | 発火したアラートのうち、実際に対応が必要だった割合 | ノイズが増え、アラート疲れにつながる |
| Recall | 対応が必要な事象のうち、アラートが検出できた割合 | 本当に対応すべき問題を見逃す |
| Detection Time | 問題発生からアラート発火までの時間 | Budget の消費が進んでから気づくことになる |
| Reset Time | 問題解決後、アラートが止まるまでの時間 | 解決済みの問題でアラートが鳴り続ける |
Precision と Recall は割合なので 100% に近いほど良い状態です。 Precision が高ければ 鳴ったアラートはほぼ全て対応が必要 であることを意味し、Recall が高ければ 対応が必要な問題をほぼ全て検知できている ことを意味します。 Detection Time と Reset Time は時間なので、短ければ短いほど良い状態です。
理想的なアラートは Precision / Recall が高く、Detection Time / Reset Time が短い状態 ですが、現実には各属性間にトレード・オフがあります。
例えば、Detection Time を短くするためにウィンドウを狭くすると、一時的なスパイクでも発火しやすくなり Precision が下がります。 逆に Precision を上げるためにウィンドウを広げると、問題の検知が遅れ Detection Time が悪化します。
以降の 6 つの戦略を通じて、このトレード・オフがどのように現れるかを見ていきます。
前提:共通の設定例
以降の各戦略は、同じ前提条件で比較します。
- SLO:99.9%(30 日間のローリングウィンドウ)
- Error Budget:0.1% = 30 日で 43.2 分のダウンタイム相当
戦略 1:単純な閾値アラート
最もシンプルなアプローチは、Error Rate が SLO の閾値を超えたらアラートを発火する方法です。
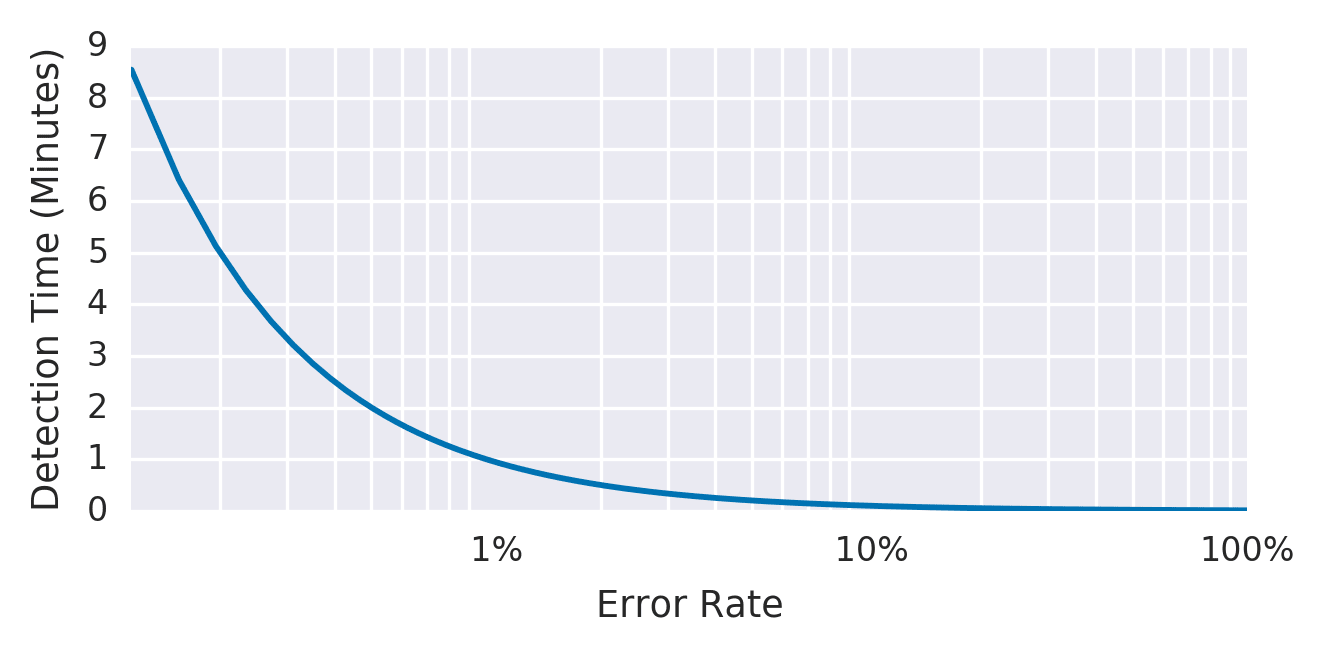
10 分間のウィンドウで Error Rate が 0.1% 以上になったら アラートを発火します。
評価
| 属性 | 評価 | 理由 |
|---|---|---|
| Precision | 悪い | 月間 Budget の 0.02% 消費でもアラートが発火する |
| Recall | 良好 | ほぼすべてのイベントを検出できる |
| Detection Time | 良好 | 完全停止で約 0.6 秒 |
| Reset Time | 良好 | 10 分ウィンドウなので短い |
戦略 1 では Precision が極めて低いことが最大の問題になります。 Error Budget にほとんど影響しない一時的なスパイクでもアラートが発火するため、1 時間で最大 144 回ものアラートが発火する 可能性があります。 これはアラート疲れの典型的な原因になります。
具体例
特定の API パス(SLO 99.9%、30 日間)に Error Rate ベースのアラーティングを設定した場合において、深夜 3 時にネットワークの瞬断が発生し、10 秒間だけ Error Rate が 5% に跳ね上がったとします。
10 分ウィンドウの平均 Error Rate は 0.1% を超えるため、アラートが即座に発火します。 しかし、瞬断は 10 秒で自然回復しており、ユーザへの影響はほぼありません。 オンコールのエンジニアは深夜に起こされますが、調査しても既に問題は解消しています。
このようなケースが頻発すると、オンコールのエンジニアがアラートを軽視するようになり、本当に対応が必要な障害を見逃すリスクが高まります。
戦略 2:アラートウィンドウの拡大
戦略 2 は、戦略 1 の Precision を改善するために ウィンドウを長くして平滑化する アプローチです。
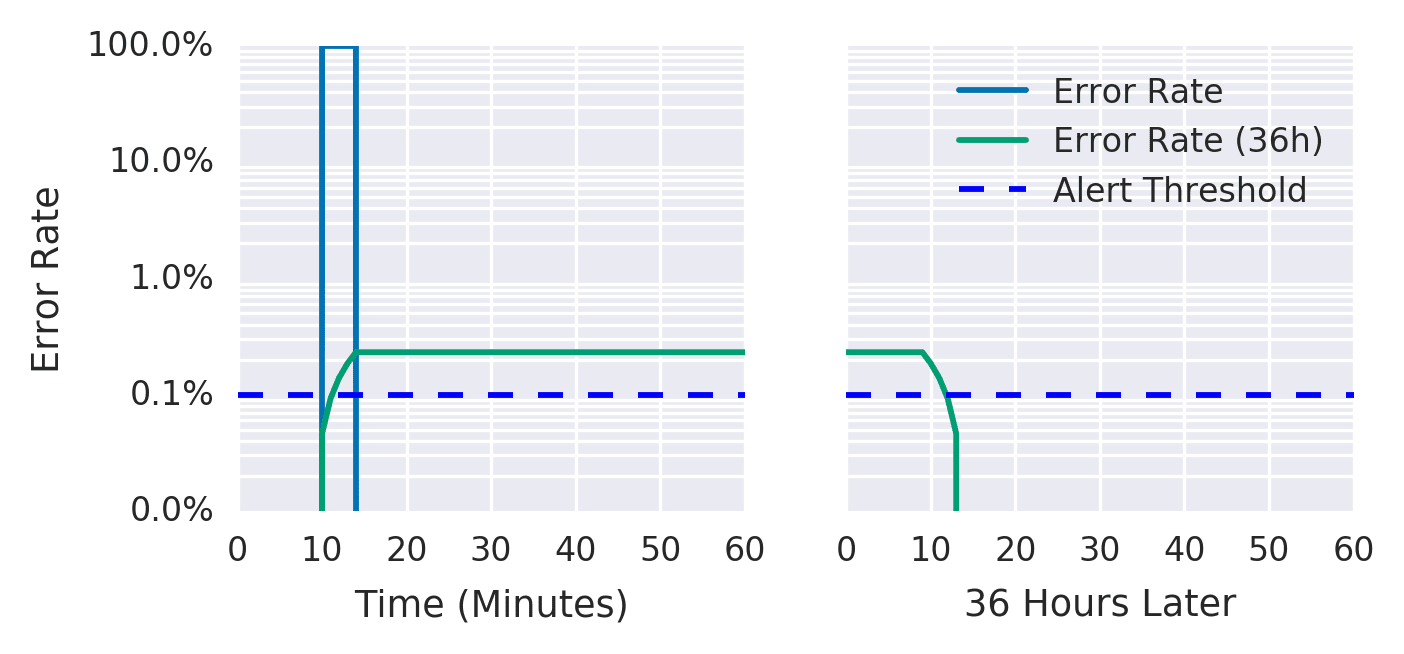
ウィンドウを 10 分から 36 時間に大幅に拡大することで、一時的なスパイクでは発火しなくなります。
評価
| 属性 | 評価 | 理由 |
|---|---|---|
| Precision | 良好 | 小さなスパイクでは発火しない |
| Recall | 良好 | 戦略 1 と同様、ほぼすべてのイベントを検出できる |
| Detection Time | 良好 | 完全停止で約 2 分 10 秒 |
| Reset Time | 悪い | 問題解決後も 36 時間アラートが続く |
ウィンドウを 10 分から 36 時間に広げたことで、戦略 1 で問題だった Precision は改善されています。 短時間のスパイクは 36 時間の平均に埋もれるため、ノイズが大幅に減ります。 Recall と Detection Time も良好です。
しかし、Reset Time が致命的に悪化しています。 36 時間のウィンドウは過去 36 時間分のデータを常に参照していることを意味するため、問題が解消しても過去のエラーがウィンドウから抜けるまでアラートが鳴り続けます。
具体例
月曜の午前中にデプロイ起因で 30 分間 Error Rate が上昇し、ロールバックで問題が解消したとします。
しかし、36 時間ウィンドウの平均にはこの 30 分間のエラーが残り続けるため、アラートは火曜の夜まで鳴り続けます。 運用者目線では、「このアラートは解決済みだから無視してよい」という判断になるため、アラートを無視する習慣がつくと本当に対応が必要なアラートも見落とすリスクが高まります。
戦略 3:持続時間パラメータ
閾値を一定時間超え続けた場合にのみアラートを発火する アプローチです。
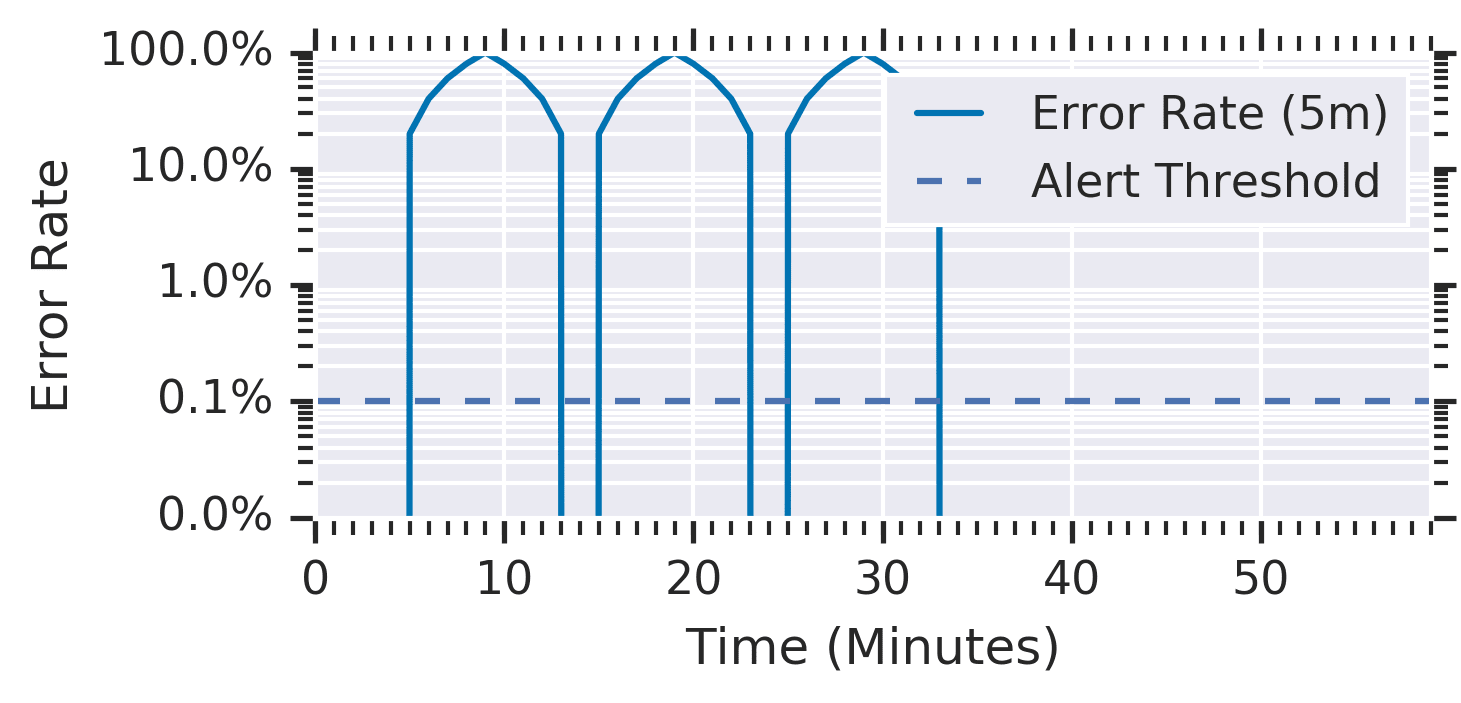
for: 1h により、Error Rate が 1 時間継続して 0.1% を超えた場合にのみアラートが発火します。
評価
| 属性 | 評価 | 理由 |
|---|---|---|
| Precision | 良好 | 一時的なスパイクでは発火しない |
| Recall | 悪い | メトリクスの変動でカウンタがリセットされる |
| Detection Time | 悪い | 100% 停止も 0.2% 停止も同じ 1 時間待つ必要がある |
| Reset Time | 良好 | 問題解決後 for の期間が経過すればアラートが止まる |
戦略 2 で問題だった Reset Time は改善したものの Recall と Detection Time に新たな課題が生じています。
Recall が低い理由は、for を用いた場合、連続で閾値を超え続けないとアラートが発火しない点にあります。
断続的にエラーが発生するパターンでは、閾値を一瞬でも下回る度にカウンタがリセットされ、Budget を消費し続けていてもアラートが発火しません。
Detection Time が悪い理由は、for が問題の深刻度を区別しないためです。
サービスが完全に停止している場合でも、軽微なエラー増加の場合でも、同じ時間(この例では 1 時間)を待たなければアラートが発火しません。
具体例
依存先サービスの不安定さにより Error Rate が断続的に上下する状況を考えます。
| 時刻 | Error Rate | 閾値(0.1%) | for カウンタ |
|---|---|---|---|
| 00 分 | 0.15% | 超過 | カウント開始 |
| 15 分 | 0.05% | 下回る | リセット |
| 30 分 | 0.12% | 超過 | カウント開始 |
| 45 分 | 0.08% | 下回る | リセット |
| 60 分 | ... | ... | 1 時間経過してもアラート未発火 |
for: 1h では閾値を 1 時間連続で超え続けた場合にのみ発火する ため、途中で一瞬でも閾値を下回るとカウンタがリセットされます。
この間も Error Budget は閾値を超えている間ずっと消費されていますが、アラートは一度も発火しません。
結果として、数日後に Budget が枯渇して初めて問題に気づくという事態が起き得ます。
また、for は問題の深刻度を考慮しません。
100% の完全停止でも、0.2% の軽微なエラー増加でも、同じ 1 時間待たなければアラートが発火しないため、深刻な障害への初動が遅れるリスクがあります。
このため、SLO ベースのアラートに for のみを使うことは推奨されません。
Burn Rate の導入
戦略 1〜3 はいずれも Error Rate そのものを閾値に使っていました。 ここで視点を変え、Error Budget が どれだけの速度で消費されているか を監視する Burn Rate のアプローチを導入します。
Burn Rate とは
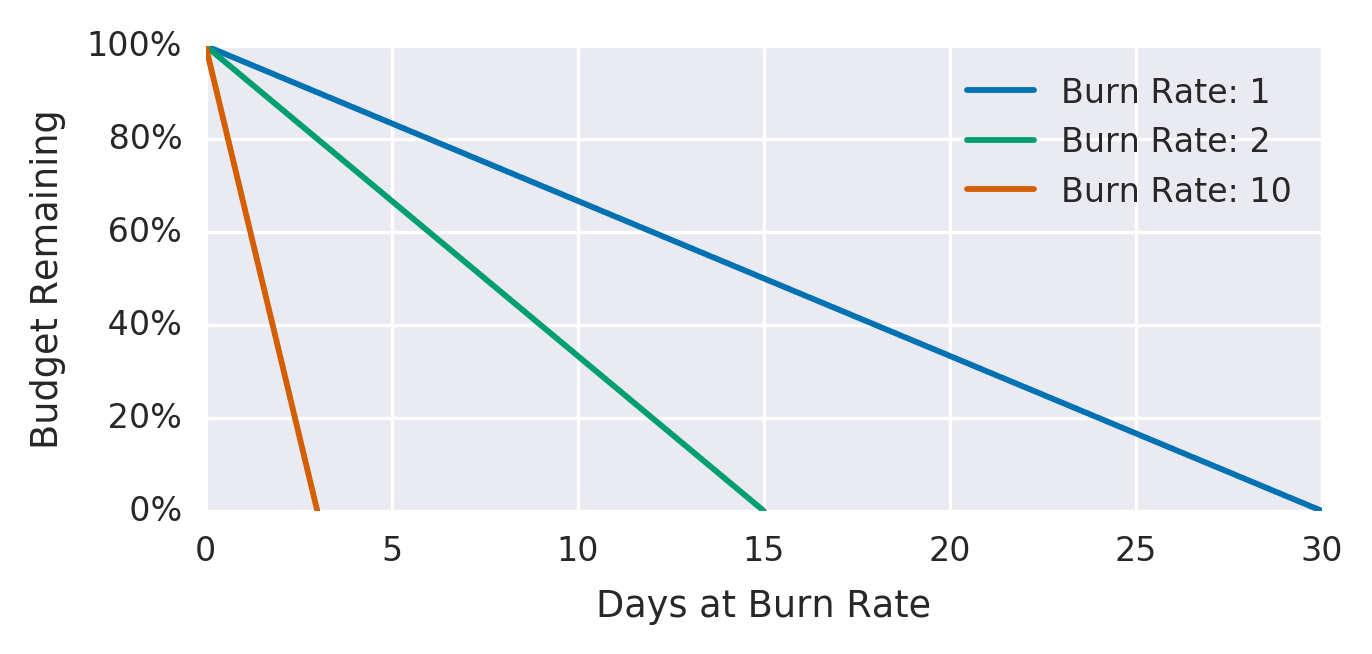
Burn Rate は Error Budget の消費速度を表す倍率 です。
Burn Rate が 1 であれば、SLO 期間(30 日)でちょうど Error Budget を使い切るペースです。 Burn Rate が 10 であれば、3 日で Budget が枯渇する猛烈なペースになります。
99.9% SLO(30 日間)の場合の Burn Rate と Budget 枯渇までの時間は以下の通りです。
| Burn Rate | Error Rate | Budget 枯渇までの時間 |
|---|---|---|
| 1 | 0.1% | 30 日(= ちょうど期間内で使い切る) |
| 2 | 0.2% | 15 日 |
| 10 | 1.0% | 3 日 |
| 1,000 | 100%(完全停止) | 43 分 |
Burn Rate の計算例
例として、1 時間で Error Budget の 5% を消費するペースが Burn Rate でいくつに相当するかを計算してみます。
つまり Burn Rate 36 は、1 時間で Budget の 5% を消費する速度を意味します。
検出時間の計算
特定の Burn Rate に対する検出時間は以下の式で求めることができます。
完全停止(Error Ratio = 1)で Burn Rate 36、1 時間ウィンドウの場合、Detection Time は約 40 秒です。
戦略 4:単一 Burn Rate アラート
戦略 1〜3 が Error Rate そのものを閾値にしていたのに対し、戦略 4 からは Burn Rate を閾値に使います。
ここでは 1 時間ウィンドウに Burn Rate 36 の閾値を設定 します。 先ほどの計算例で示した通り、Burn Rate 36 は「1 時間で Budget の 5% を消費するペース」に相当します。
ここで 5% という値は Google SRE Workbook が戦略 4 の例として用いている数値であり、「1 時間でこれだけ消費しているなら即座に対応が必要」という 運用上の判断ライン です。 このペースが続けば約 20 時間で Budget が枯渇するため、それだけの深刻度を検知するアラートということになります。
exprの 36 * 0.001 は、Burn Rate(36)に SLO が許容する Error Rate(1 - 0.999 = 0.001)を掛けた値です。
つまり、直近 1 時間の Error Rate が 3.6% を超えた場合にアラートが発火します。
評価
| 属性 | 評価 | 理由 |
|---|---|---|
| Precision | 良好 | 有意な Budget 消費時のみ発火する |
| Recall | 悪い | Burn Rate 35 では全 Budget 枯渇しても検知できない |
| Detection Time | 良好 | 完全停止で約 40 秒 |
| Reset Time | 不十分 | 問題解決後も最大 58 分間アラートが残る |
戦略 1〜3 と比較して、Precision と Detection Time は大きく改善されています。 Burn Rate を閾値にすることで、Budget に影響のある消費ペースの時だけアラートが発火するため、戦略 1 のようなノイズは発生しません。 Detection Time も完全停止時に約 40 秒と高速です。
一方で、戦略 3 と同様に Recall の低さが問題になります。 単一の Burn Rate 閾値では、閾値をわずかに下回るペースでの Budget 消費を一切検知できません。 Reset Time についても 1 時間ウィンドウの影響で問題解決後に最大 58 分間アラートが残り続けます。
具体例
特定の API エンドポイントで断続的なタイムアウトが発生し、Burn Rate 35 で Budget が着実に消費されている状況を考えます。 閾値が Burn Rate 36 に設定されているため、35 はぎりぎり閾値を下回り、アラートは一度も発火しません。 このペースでは約 20.5 時間で Budget が完全に枯渇しますが、オンコール担当者は問題に気づくことができません。
戦略 5:Multiple Burn Rate アラート
戦略 4 では単一の Burn Rate 閾値しか設定しないため、閾値を下回るペースの消費を検知できないという Recall の問題がありました。 戦略 5 はこの問題を解決するために、消費速度の段階に応じて複数のアラートを設定する アプローチを取ります。
設計の考え方
まず、「どのくらいのペースで Budget が消費されたら、どのレベルで通知すべきか」という運用上の許容ラインを決めます。
| 検知対象 | 許容ライン | 通知 |
|---|---|---|
| 急速な消費(Fast Burn) | 1 時間で Budget の 2% を消費したら | オンコール・即時対応 |
| 中程度の消費 | 6 時間で Budget の 5% を消費したら | オンコール・即時対応 |
| 緩やかな消費(Slow Burn) | 3 日で Budget の 10% を消費したら | チケット起票・翌日対応 |
これらの許容ラインは Google SRE Workbook で提示されている推奨値 ですが、組織やサービスの特性に応じて調整することも可能で、例えば「1 時間で 3% 消費したら通知」というラインにすることもできます。
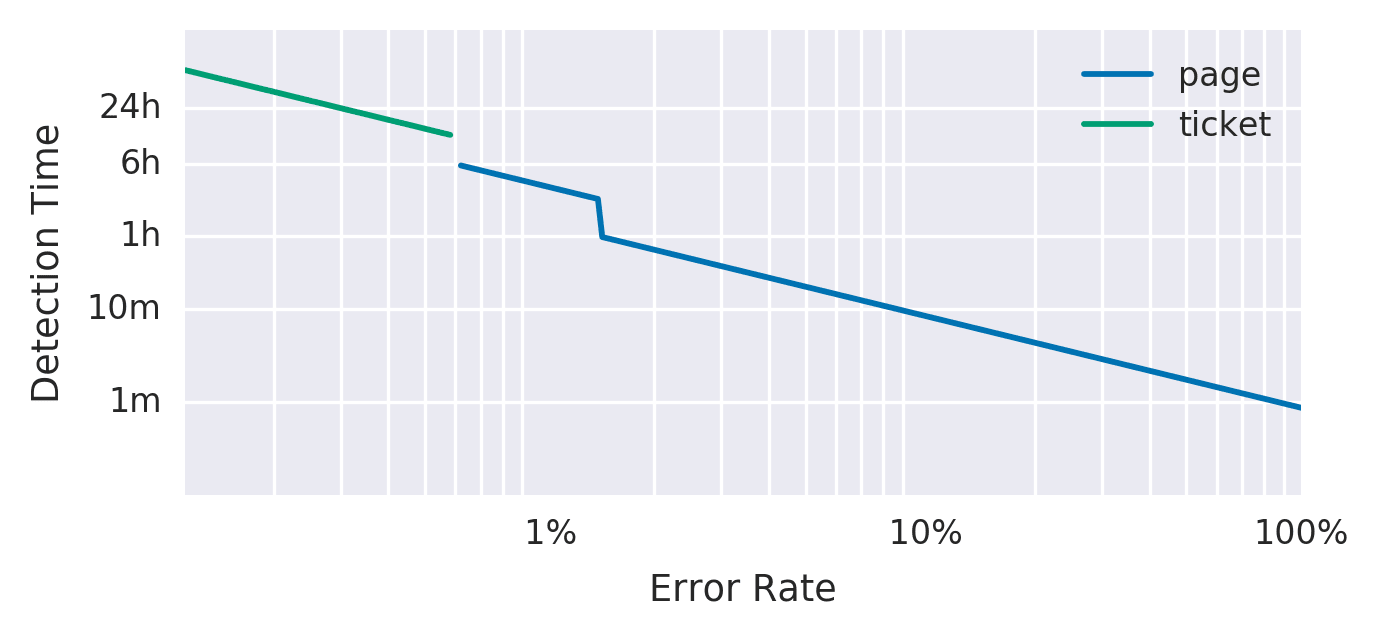
- 青線(page):Error Rate が高いほど短時間で検知される(オンコール対応)
- 緑線(ticket):低い Error Rate でも検知できるが Detection Time が長い(チケット起票)
許容ラインから Burn Rate を逆算する
許容ラインが決まったら、それぞれに対応する Burn Rate の閾値を以下の式で逆算します。
| 許容ライン | ウィンドウ | 計算 | Burn Rate |
|---|---|---|---|
| 1 時間で 2% 消費したら通知 | 1 時間 | 14.4 | |
| 6 時間で 5% 消費したら通知 | 6 時間 | 6 | |
| 3 日で 10% 消費したら通知 | 3 日(72 時間) | 1 |
- オンコール・即時対応
- チケット起票・翌日対応
評価
| 属性 | 評価 | 理由 |
|---|---|---|
| Precision | 良好 | 重大度に応じた適切な通知ができる |
| Recall | 良好 | 3 日ウィンドウで遅い消費もカバーする |
| Detection Time | 良好 | 急速な消費は短ウィンドウで即検知する |
| Reset Time | 不十分 | 3 日ウィンドウ分の遅延が残る |
戦略 4 で問題だった Recall は、複数の Burn Rate 閾値を設定することで改善されています。 1 時間ウィンドウ(Burn Rate 14.4)では検知できない緩やかな消費も、3 日ウィンドウ(Burn Rate 1)でカバーできます。 Precision も、消費速度に応じてオンコールとチケットを使い分けられるため良好です。
一方で、Reset Time には課題が残ります。 3 日ウィンドウのアラートは、問題が解消してもウィンドウ内に過去のエラーが含まれている限り発火し続けるため、最大 3 日間アラートが残る可能性があります。
また、3 つのウィンドウとそれぞれの Burn Rate で管理すべきパラメータが増えるため、複数条件が同時に発火した際の重複通知の抑制も考慮する必要があります。
具体例
金曜の夜にデプロイ起因で 2 時間ほど Error Rate が上昇し、ロールバックで解消したとします。 Fast Burn(1 時間ウィンドウと 6 時間ウィンドウ)のアラートはそれぞれのウィンドウ経過後に止まるため、即時対応は完了します。
一方で、Slow Burn(3 日ウィンドウ)のアラートは日曜まで鳴り続ける可能性があります。 チケット起票のため通常は翌営業日対応になりますが、月曜に出社したチームは「このチケットは金曜の対応済み障害の残骸なのか、週末に新たに発生した問題なのか」の判断に困ります。
戦略 6:Multiwindow / Multi-Burn-Rate アラート
戦略 5 の Reset Time 問題を解決するのが、Google SRE Workbook が推奨する Multiwindow / Multi-Burn-Rate アラートのアプローチです。
※ 戦略 5 の Multiple Burn Rate と戦略 6 の Multi-Burn-Rate の表現について
直訳するとどちらも同じ意味ですが、戦略 6 は「Multiwindow」と「Multi-Burn-Rate」の 2 つの特徴を組み合わせた手法なので複合形容詞として扱われています。
Multiwindow / Multi-Burn-Rate アラートの戦略では、長いウィンドウ(蓄積を見る)と 短いウィンドウ(今も続いているか)の両方を組み合わせてアラートの条件を設定 します。
具体的には、戦略 5(Multiple Burn Rate)に「短いウィンドウ」を AND 条件で追加します。 短いウィンドウは長いウィンドウの 1/12 になるように設定 します。
1/12 という比率の理論的な根拠は Workbook 上では明示されていませんが、短すぎるとノイズが増え、長すぎると Reset Time の改善効果が薄れるため、実運用上のバランスとして採用されていると考えられます。 例えば、1 時間の長いウィンドウに対して 5 分、6 時間に対して 30 分、3 日に対して 6 時間という短いウィンドウになります。
長いウィンドウだけでは Budget 消費の蓄積は検知できても、問題が既に解決されたかどうかがわかりません。 短いウィンドウを AND 条件で追加することで、「蓄積があり、かつ今も続いている」場合にのみアラートが発火します。
| 通知 | 長いウィンドウ | 短いウィンドウ | Burn Rate | Budget 消費量 |
|---|---|---|---|---|
| オンコール | 1 時間 | 5 分 | 14.4 | 2% |
| オンコール | 6 時間 | 30 分 | 6 | 5% |
| チケット | 3 日 | 6 時間 | 1 | 10% |
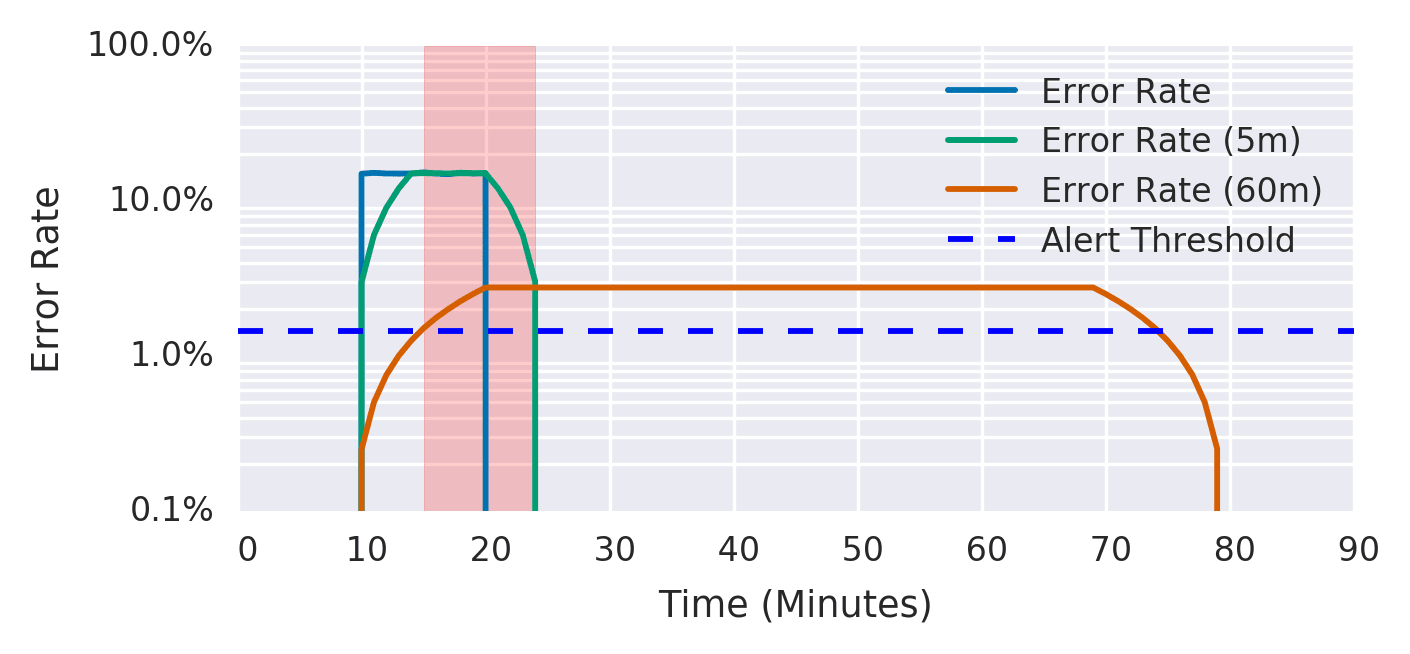
- 青線(Error Rate):実際の瞬間的な Error Rate で 10 分〜20 分あたりで急上昇し、その後正常に戻っている
- 緑線(短いウィンドウ):5 分ウィンドウの平均 Error Rate で実際の Error Rate に近い動きで問題解消後すぐに下がる
- 橙線(長いウィンドウ):1 時間ウィンドウの平均 Error Rate で過去 1 時間分を平均するため問題解消後も緩やかに下がる
- 赤い帯:アラートが発火している期間
- オンコール・即時対応
- チケット起票・翌日対応
AND 条件の短いウィンドウが 今もまだ問題が続いているか を確認する役割を果たします。
Multiwindow / Multi-Burn-Rate アラートの動作例
具体的なシナリオで Multiwindow / Multi-Burn-Rate アラートの動作を確認します。
シナリオ A:デプロイ起因の一時的な障害(Fast Burn)
| 時刻 | イベント | アラート状態 |
|---|---|---|
| 13:00 | デプロイにより Error Rate が急上昇(Burn Rate 20) | |
| 13:05 | 1h ウィンドウ AND 5m ウィンドウの両方が閾値超過 | アラート発火 |
| 13:10 | ロールバック完了、Error Rate が正常に戻る | |
| 13:15 | 5m ウィンドウの条件が外れる | アラート停止 |
5 分ウィンドウの AND 条件により、ロールバック完了から約 5 分でアラートが停止します。 戦略 5(Multiple Burn Rate アラート)では 1 時間ウィンドウのアラートが残り続けるため、Multiwindow / Multi-Burn-Rate アラート戦略の導入によって運用上の負担が大きく軽減されます。
シナリオ B:緩やかなパフォーマンス劣化(Slow Burn)
| 時刻 | イベント | アラート状態 |
|---|---|---|
| 月曜 | 依存先サービスの応答悪化でタイムアウト増加(Burn Rate 1.5) | |
| 火曜 | 3d ウィンドウ AND 6h ウィンドウの両方が閾値超過 | チケット起票 |
| 水曜 | 依存先サービスのスケールアウトにより解消 | |
| 水曜夜 | 6h ウィンドウの条件が外れる | アラート停止 |
急速な消費はオンコールで即座にアラートを発報し、緩やかな消費はチケットを起票して翌営業日に対応するという運用フローが自然と実現されます。
シナリオ C:瞬間的なスパイク(発火しないケース)
| 時刻 | イベント | アラート状態 |
|---|---|---|
| 15:00 | ネットワークの瞬断により 30 秒間 Error Rate が急上昇 | |
| 15:01 | Error Rate が正常に戻る | |
| 1h ウィンドウでは閾値を超えない | アラート未発火 |
30 秒程度の瞬断が Error Budget 全体に占める割合はほぼ 0% で、対応が必要な問題ではありません。 Multiwindow / Multi-Burn-Rate 戦略では、このようなスパイク(瞬断)ではアラートが発火しないため、鳴ったアラートは実際に対応が必要 という状態が保たれ Precision が高くなります。
なぜ Multiwindow / Multi-Burn-Rate 戦略が優れているのか
前提として、戦略 5(Multiple Burn Rate アラート)では Reset Time が不十分であるという課題がありましたが、Multiwindow / Multi-Burn-Rate アラートは短いウィンドウの AND 条件を追加することで Reset Time が劇的に改善されます。
具体、Multiple Burn Rate アラートでは問題解決後も最大 3 日間アラートが鳴り続ける可能性がありましたが、Multiwindow / Multi-Burn-Rate アラートは短いウィンドウの条件が外れた時点(5 分〜6 時間)でアラートが停止します。
| 属性 | 評価 | 理由 |
|---|---|---|
| Precision | 良好 | 短ウィンドウで「今も続いているか」を確認する |
| Recall | 良好 | 3 日ウィンドウで遅い消費もカバーする |
| Detection Time | 良好 | 完全停止で約 40 秒 |
| Reset Time | 良好 | 短ウィンドウの AND 条件で迅速に解除される |
このため、Multiwindow / Multi-Burn-Rate アラートは 4 つの属性すべてで「良好」を達成する唯一の戦略 とされています。
6 つの戦略の比較
ここまでの 6 つの戦略を一覧で比較します。
| アラート戦略 | Precision | Recall | Detection Time | Reset Time |
|---|---|---|---|---|
| 1. 単純な閾値 | 悪い | 良好 | 良好 | 良好 |
| 2. アラートウィンドウの拡大 | 良好 | 良好 | 良好 | 悪い |
| 3. 持続時間パラメータ | 良好 | 悪い | 悪い | 良好 |
| 4. 単一 Burn Rate | 良好 | 悪い | 良好 | 不十分 |
| 5. Multiple Burn Rate | 良好 | 良好 | 良好 | 不十分 |
| 6. Multiwindow / Multi-Burn-Rate | 良好 | 良好 | 良好 | 良好 |
- Error Rate ベース
- Burn Rate ベース(Error Budget 駆動)
戦略 1〜3 は Error Rate そのものを閾値にしたアプローチで、戦略 4〜6 は Burn Rate(Error Budget の消費速度)を閾値にしたアプローチです。 各戦略は前の戦略の弱点を補う形で進化しています。 戦略 1〜3 は Error Rate そのものに着目し、戦略 4〜6 は Burn Rate(Budget 消費速度)に着目しています。
実践的な考慮事項
Multiwindow / Multi-Burn-Rate アラートを実際の環境に適用する際、いくつかの考慮事項があります。
1. 低トラフィックサービスへの対応
1 時間に 10 リクエストしかないサービスで 1 リクエストが失敗すると、Error Rate は 10% になります。 これは Burn Rate 1,000 に相当し、即座に Page アラートが発火します。
しかし、実際には Budget への影響はごくわずかです。 低トラフィックサービスでは統計的な精度が低いため、以下の対策を組み合わせて適用すると良いとされています。
| 対策例 | 詳細 |
|---|---|
| 人工トラフィック | 外部から定期的にリクエストを発行する監視(black-box probers)でデータ量を補い、統計精度を高める |
| サービス結合 | 関連するマイクロサービスの SLI を束ねて評価する |
| クライアント側対応 | リトライやフォールバックで単一障害の影響を軽減する |
| SLO の緩和 | 99.9% → 99% に引き下げを検討する |
| ウィンドウ拡大 | アラートの時間枠を長くして平滑化する |
2. 極端な可用性目標への対応
高い SLO(99.999%)の場合
Error Budget が極めて小さく 100% 停止で 26 秒で Budget が枯渇します。 これではアラートの通知・確認・対応が間に合いません。
この場合、アラート設計で解決するのではなく 100% 停止の確率自体をアーキテクチャ設計で下げる必要があります。 カナリアデプロイで 1% のユーザにのみ新バージョンを展開すれば、問題が発生しても影響範囲は 1% に限定され、Budget 枯渇までの時間は約 43 分に延長されます。
低い SLO(90%)の場合
Error Budget が大きすぎるため 100% 停止でも 1 時間で Budget の 1.4% しか消費しません。 オンコール(アラート)の閾値(2%)に達しないため、重大な障害でも通知されない可能性があります。
この場合、Burn Rate の倍率を下方に調整する必要があります。
3. スケール時のアラート管理
マイクロサービスが数十〜数百になると、サービス毎に個別のパラメータを管理することは現実的ではありません。 Google SRE Workbook では サービスをクラスに分類し、クラス毎に統一パラメータを適用する アプローチが推奨されています。
| クラス | 可用性 SLO | P90 レイテンシ | P99 レイテンシ |
|---|---|---|---|
CRITICAL | 99.99% | 100ms | 200ms |
HIGH_FAST | 99.9% | 100ms | 200ms |
HIGH_SLOW | 99.9% | 1,000ms | 5,000ms |
LOW | 99% | — | — |
NO_SLO | — | — | — |
5 つのクラスに分類するだけで、十分な精度と管理可能性を両立できます。 新しいサービスが追加された場合も、適切なクラスに割り当てるだけでアラートが自動的に設定されます。
各クラスの Burn Rate 閾値やウィンドウサイズはクラスの SLO から算出できるため、個別チューニングの工数を大幅に削減することができます。
4. オンコールとチケットの使い分け
Multiwindow / Multi-Burn-Rate アラートではオンコールとチケットの 2 種類の通知を使い分けます。 この使い分けを運用フローに落とし込む際の指針を整理します。
| 通知 | 意味 | 期待される対応 | 通知先の例 |
|---|---|---|---|
| オンコール | Error Budget が急速に消費されている | 即時対応 | PagerDuty / Datadog On-Call |
| チケット | Error Budget が緩やかに消費されている | 翌日対応 | Jira / Datadog Case Management |
- アラートの内容を確認し、どの Burn Rate 条件が発火しているかを把握する
- 直近のデプロイやインフラ変更を確認する
- 影響範囲を特定し、ロールバックや緩和策を実行する
- 短いウィンドウの条件が外れてアラートが停止するのを確認する
チケット起票の場合は、Error Budget の残量を確認した上で優先度を判断します。 Budget の残りが十分であれば、次のスプリントで対応を計画することも合理的な判断だと言えます。
おわりに
今回のブログでは Google SRE Workbook における SLO ベースのアラート設計を 6 つの戦略で段階的に取り上げ、各戦略の特徴や評価ポイントを整理しました。
最も重要なポイントは以下の 4 つです。
- アラートは Precision・Recall・Detection Time・Reset Time の 4 つの属性で評価する
- Error Rate そのものではなく、Burn Rate(Budget 消費速度)をアラートの基準にする
- Multiwindow / Multi-Burn-Rate アラートは、長いウィンドウと短いウィンドウの AND 条件で 4 属性すべてを良好にする
- 低トラフィックや極端な SLO には、アラート設計だけでなくアーキテクチャ設計やサービスクラス分類で対応する
SLI/SLO の定義と Error Budget の管理だけでは信頼性の運用は完結しません。 Budget がどのペースで消費されているかを適切に検知し、対応のアクションに繋げるアラート設計があって初めて、信頼性を数値で管理する仕組みが機能します。