SLI/SLO:サービスの信頼性を数値で管理する
はじめに
サービスの信頼性を議論する場面で、「可用性を上げよう」「最近不安定な気がする」といった定性的な表現にとどまるケースは少なくありません。 具体的な数値がなければ「どれくらい不安定なのか」「どこまで改善すれば十分なのか」を判断する基準がなく、開発チームは「新機能を早くリリースしたい」、運用チームは「安定稼働を最優先にしたい」といった双方の主張が衝突しがちです。
こうした課題に対して、SRE(Site Reliability Engineering) が提唱するのが SLI・SLO・Error Budget の考え方です。 今回のブログでは、これらの概念の意味・関係・実践方法を整理してみたいと思います。
SLI・SLO・SLA の全体像
Google SRE の The Art of SLOs では、以下のように述べられています。
「あらゆるシステムにおいて最も重要な機能は信頼性である」
ー The most important feature of any system is its reliability ー
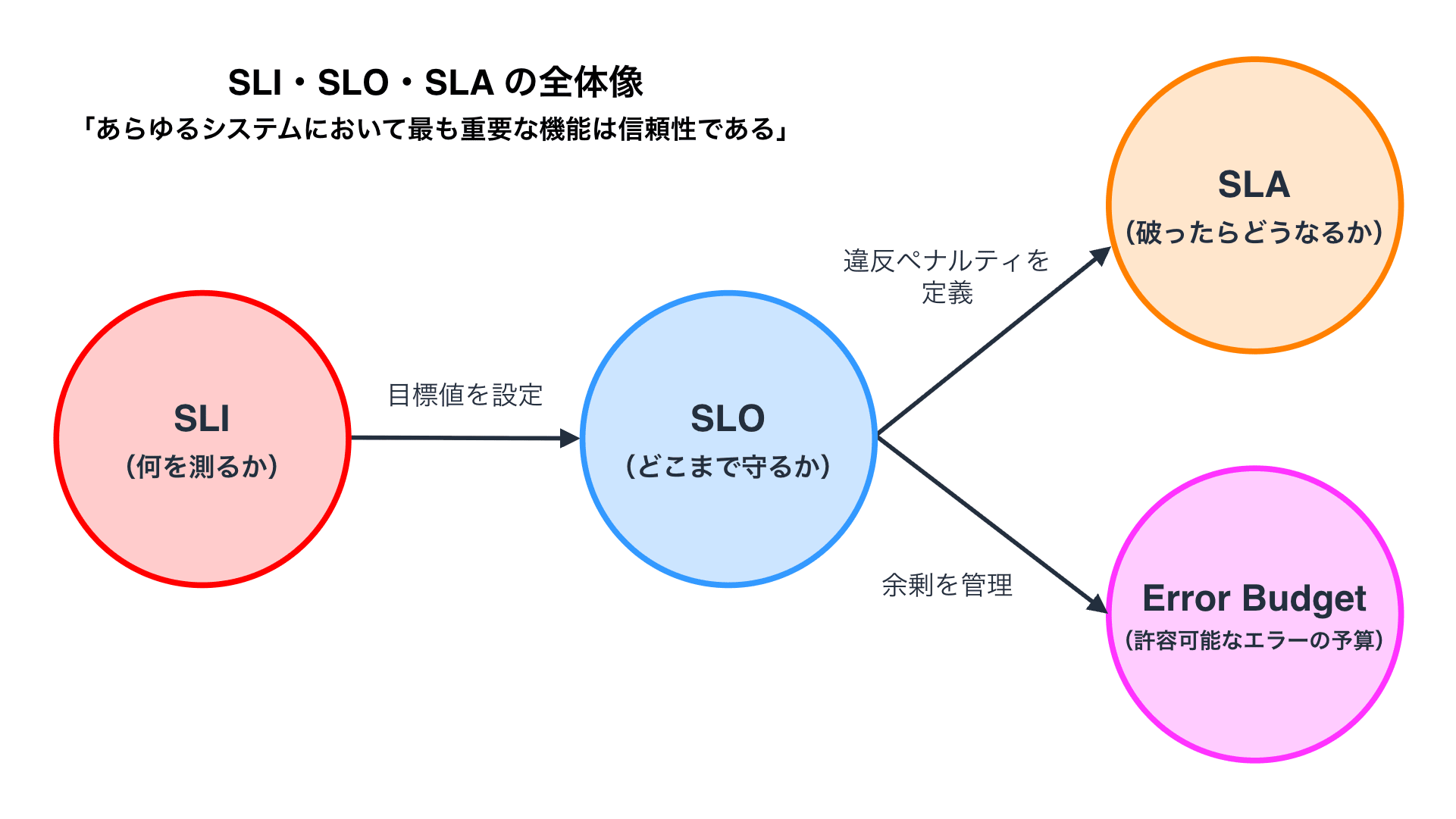
SLI・SLO・SLA はサービスの信頼性を管理するための 3 層構造を形成します。
| 指標 | 一言で言うと | 対象 |
|---|---|---|
| SLI(Service Level Indicator) | 計測値 | 社内 |
| SLO(Service Level Objective) | 内部目標 | 社内 |
| SLA(Service Level Agreement) | 外部契約 | 顧客向け |
SLI は「何を測るか」、SLO は「どこまで守るか」、SLA は「破ったらどうなるか」を定義します。 それぞれは独立した概念ではなく、SLI を測定し、SLO で目標を設定し、SLA で顧客との契約を結ぶという階層構造になっています。
SLI(Service Level Indicator)
SLI は ユーザ体験を反映する定量的な計測値 です。 基本の形は以下の式で表されます。
この式が示すように、SLI は常に 0〜100% の割合で表現されます。 「何件エラーが発生したか(絶対数)」ではなく「エラー率(割合)」で表すことで、トラフィック量が異なるサービス間での比較や、時系列での変化の把握が容易になります。
SLI の 4 つのカテゴリ
Google SRE では SLI を主に 4 つのカテゴリに分類しています。
| カテゴリ | 意味 | 対象システム例 |
|---|---|---|
| 可用性 | リクエストが成功したか | API、Web アプリケーション |
| レイテンシ | どれだけ速く応答したか | API、Web アプリケーション |
| 品質 | 劣化なく応答したか | 動画配信、検索 |
| データ鮮度 | データが最新か | バッチ、パイプライン |
すべてのカテゴリがすべてのサービスに必要なわけではありません。 ユーザが気にすること(関心事) に絞って SLI を選択することが重要です。
良い SLI と 悪い SLI
SLI の選び方を誤ると、数値を計測していても実際のユーザ体験とかけ離れた指標を追い続けることになります。
良い SLI の条件は以下の 3 つです。
- ユーザ体験と直接相関する
- 計測可能である
- 0〜100% の比率で表せる
また、よくあるアンチパターンを示します。
| やりがちな SLI | なぜ不適切か | 代替案 |
|---|---|---|
| CPU 使用率 | ユーザ体験と直接関係しない | レイテンシ p99 |
| 障害件数 | 影響の大小がわからない | エラー率(%) |
| 平均レイテンシ | 外れ値が隠れる(遅い 1% が見えない) | p95 / p99 |
CPU 使用率が高くてもユーザには影響がない場合もあれば、CPU 使用率が低くてもレイテンシが悪化している場合もあります。 障害の「件数」は規模感を伝えず、1 件の大規模障害と 100 件の軽微な障害を区別できません。 平均レイテンシは少数の遅いリクエストを隠してしまうため、外れ値が重要な意味を持つレイテンシ計測にはパーセンタイル(p95・p99)を用います。
どこで計測するか
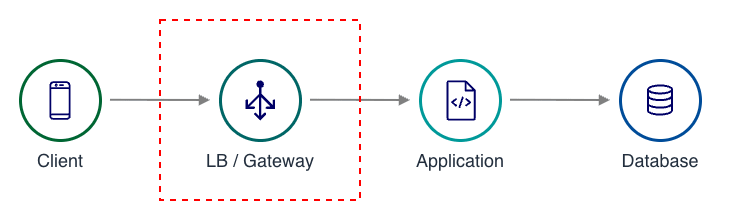
SLI の計測ポイントの選択は、どれだけユーザ体験に近い値を取れるかに影響します。
| 計測ポイント | メリット | デメリット |
|---|---|---|
| LB / API Gateway(推奨) | ユーザに最も近い値が取れる | アプリケーション内部の詳細が見えない |
| アプリケーション | 詳細な計測が可能 | ネットワーク遅延が含まれない |
| クライアント | 最もリアルな値 | 計測実装が難しい |
原則として、ユーザに近い場所で計測する ことが推奨されます。
SLI の定義例
API サービスの SLI を定義する例をみてみましょう。
バッチ処理やデータパイプラインの SLI の例も示します。
この定義を SLO ドキュメント として文書化し、チームで共有しておくことが重要です。 SLI の定義が曖昧だと、SLO 達成の判断基準が人によって変わってしまいます。 「何が良いイベントで、何が全イベントか」を明文化することが正確な計測の前提条件です。
SLO(Service Level Objective)
SLO は SLI に対して設定する内部的な目標値と計測期間の組み合わせ です。
ここで重要なのは、100% の信頼性は目指すべきではないという点です。 The Art of SLOs でも以下のように述べられています。
「100% はほぼすべてのサービスにとって間違った信頼性の目標である」
ー 100% is the wrong reliability target for basically everything ー
可用性毎のダウンタイムを見ると、その理由が明確に分かります。
| 可用性 | 年間ダウンタイム | 月間ダウンタイム | 実現難易度 |
|---|---|---|---|
| 99%(Two Nines) | 3 日 15 時間 | 7 時間 18 分 | 容易 |
| 99.9%(Three Nines) | 8 時間 46 分 | 43 分 50 秒 | 標準的 |
| 99.99%(Four Nines) | 52 分 34 秒 | 4 分 23 秒 | 困難 |
| 99.999%(Five Nines) | 5 分 15 秒 | 26 秒 | 非常に困難 |
99.9% から 99.99% に引き上げるコストは桁違いに高く、また多くのユーザの接続環境自体が 100% ではありません。
「ちょうどよい信頼性」を見つける ことこそが SLO を設定する目的です。
例えば、EC サイトの決済 API に対して以下のような SLO を設定するとします。
過去 28 日間のレスポンスの 99.9% が HTTP 2xx / 3xx / 4xx ステータスコードを返す
この場合、SLI の目標値が「99.9%」、計測ウィンドウが「過去 28 日間」に該当します。 つまり SLO とは「どの指標を、どの期間で、どこまで守るか」を 1 つの文で定義したものです。
SLO を設定する際は以下の点を意識する必要があります。
- 技術的な限界ではなく、ユーザの期待とビジネス要件から逆算して設定する
- 最初から完璧な値を目指す必要はなく、運用しながらイテレーティブに調整していく
- SLO は必ず文書化し、チームで合意を取る
SLO を決める 4 ステップ
Step 1:現状を知る
過去のデータから現在の SLI の実績値を算出します。 例として、過去 30 日の可用性が 99.95% だった場合、これが出発点になります。
Step 2:ユーザの期待を理解する
ユーザがどこまで許容するかを把握します。 競合サービスの水準や、ダウンタイムがビジネスに与えるインパクトも参考になります。
Step 3:SLO を仮設定する
現状の実績値より少し厳しめに設定します。 最初は完璧を目指さず、仮置きで始めることが重要です。
Step 4:運用しながら調整する
SLO が厳しすぎると開発が止まります。 緩すぎるとユーザ不満が蓄積します。 実運用を通じて適切な値を探し続けます。
SLO ドキュメント
SLO は口頭の約束ではなく、レビュー可能なドキュメント として残します。
| 項目 | 値 |
|---|---|
| サービス名 | Payment API |
| SLI | 非 5xx レスポンスの割合 |
| SLO | 28 日間で 99.95% |
| 計測方法 | LB のアクセスログ |
| 対象 | /api/v1/payments/* |
| 除外条件 | 計画メンテナンス、4xx |
| ウィンドウ | 28 日ローリング |
| レビュー | 四半期毎 |
計測ウィンドウの種類
SLO の計測期間には「ローリングウィンドウ」と「カレンダーウィンドウ」の 2 種類があります。
ローリングウィンドウ(推奨)
直近の一定期間(例:28 日間)を常に評価します。 評価の対象は毎日スライドするため、常に最新の状態が反映されます。
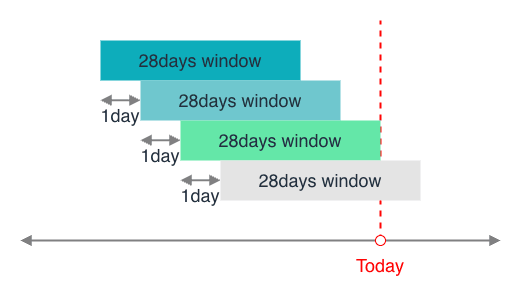
カレンダーウィンドウ
月初〜月末の固定期間で評価します。 月末にリセットされるため、月初にリリースを集中させやすい問題があります。 「月初に障害を起こしても月末までに回復すればよい」というインセンティブが生まれることも指摘されています。
このため、Google SRE では 28 日間のローリングウィンドウが推奨 されています。
SLA(Service Level Agreement)
SLA は SLO を下回った場合のペナルティを含む、顧客との外部契約 です。 SLO との関係を整理すると、SLA は SLO より緩く設定することが基本です。
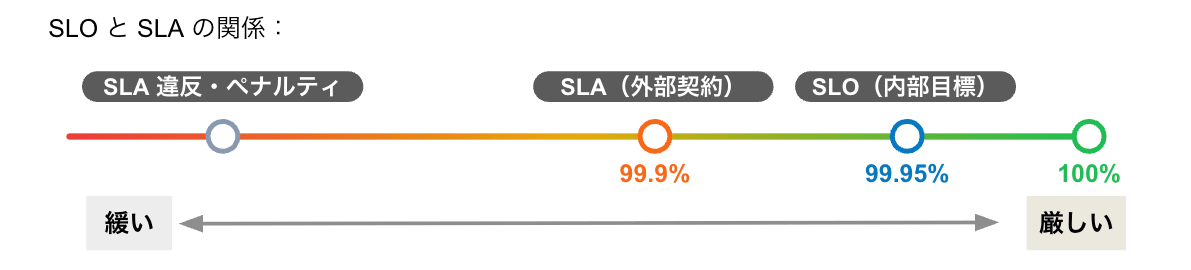
SLO を守れていれば SLA 違反は起きません。 SLO は SLA へのバッファとして機能するため、SLO が適切に設定・遵守されていれば、顧客への影響を事前に防げます。
SLA は顧客向けに公開する外部契約ですが、SLA がなくても SLO は必ず設定すべきです。 SLO は組織内部での品質管理の基準として機能するため、外部契約の有無に関わらず重要です。
主要なクラウドプロバイダの SLA 例を示します。
これらの SLA は、各プロバイダが内部で SLO として管理している値より緩く設定されています。 自社サービスの SLA を設定する際も、同様に内部目標(SLO)との間にバッファを持たせることが重要です。
Error Budget
Error Budget は SLO を満たしつつ、許容できるエラーの量を定量化した概念 です。 言うならば 信頼性を犠牲にできる余裕を数値化したもの になります。
例えば SLO が 99.9% であれば、残りの 0.1% 分はエラーが発生しても SLO 違反にならないことを意味します。 この 0.1% の余裕が Error Budget です。
Error Budget の計算
Error Budget は以下の式で計算されます。
具体例で示します。
- SLO:99.9%(28 日間)
- 28 日間の総リクエスト数:1,000,000 件
この 1,000 リクエスト分の「失敗」が予算です。 この予算を新機能のリリースやインフラ変更に 戦略的に利用 します。
Error Budget の使い方
Error Budget の残量に応じて、開発チームの行動指針が変わります。
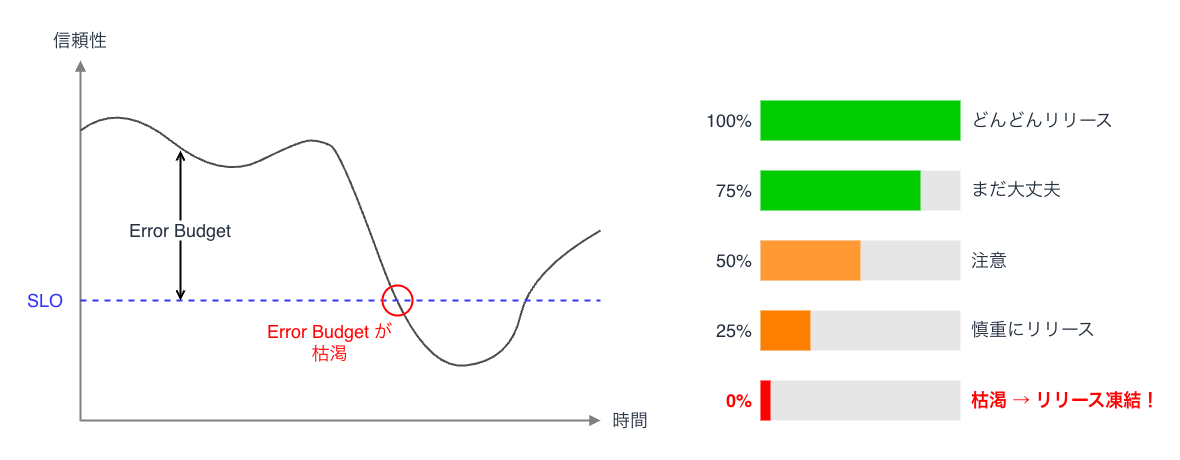
| Budget 状態 | 開発チームのアクション |
|---|---|
| 十分 | 新機能リリース、実験的デプロイ可 |
| 減少中 | リリース頻度を下げ、ロールバック準備 |
| 枯渇 | リリース凍結し、信頼性改善に集中 |
このモデルの重要な点は、Error Budget が「どこまでリスクを取ってよいか」の共通基準になることです。 開発チームは「Budget が残っているうちはリリースしてよい」、運用チームは「Budget が尽きたらリリースを止める」というルールに基づいて、定性的な判断ではなく、定量的な数値で意思決定 することができます。
Burn Rate アラート
Burn Rate は Error Budget の消費速度 を表します。 Burn Rate 1 は「ちょうど SLO 期間が終わった時点で Budget を使い切るペース」を意味します。 Burn Rate に基づいたアラートは、従来の閾値アラートと比較して ユーザ影響がある時、またはその可能性が高確率である場合のみ通知する という特徴があります。
Burn Rate の計算例を示します。
- SLO:99.9%(28 日間)
- Error Budget:0.1%(28 日間)= 40.32 分
| Burn Rate | 消費速度 |
|---|---|
| 1 | 28 日間 で 40.32 分を使い切るペース |
| 2 | 14 日間 で 40.32 分を使い切るペース(2 倍の速度) |
| 14.4 | 2 日間 で 40.32 分を使い切る猛烈なペース(14.4 倍の速度) |
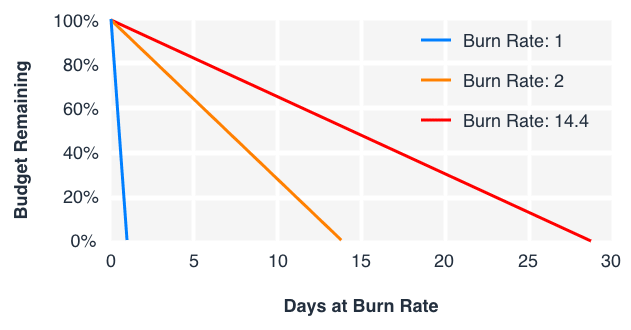
Burn Rate が高いほど、すぐに介入が必要な状態であることを示します。
Fast Burn と Slow Burn
Burn Rate に基づくアラートは、消費速度に応じて Fast Burn と Slow Burn の 2 段階に分けて設計します。
Fast Burn は、デプロイ直後の障害や依存サービスの大規模ダウン等によって、短時間で Budget を大量に消費するパターン です。 Burn Rate が高く(例:14 以上)、数時間で Budget が枯渇するペースのため、即時のオンコール対応が求められます。
Slow Burn は、間欠的なタイムアウトや特定条件でのみ発生するエラー等によって、じわじわと Budget を消費し続けるパターン です。 Burn Rate は低め(例:2 〜 6 程度)ですが、放置すると数日で Budget が枯渇するため、翌営業日にチケットを起票するなどして対応します。
| 分類 | Burn Rate 目安 | Budget 枯渇までの時間 | 対応 |
|---|---|---|---|
| Fast Burn | 14 以上 | 数時間 | 即時ページ、オンコール対応 |
| Slow Burn | 2 〜 6 | 数日 | 翌営業日にチケット対応 |
従来のアラートの問題点
CPU > 80%:ノイズが多く、ユーザ影響と直結しないエラー数 > 10 件 / 分:ユーザ影響の大小がわからない
このため、通知の頻度が高くなることで重要なアラートが埋もれてしまう問題、いわゆるアラートの形骸化が起きやすくなります。
Burn Rate アラートの特徴
Burn Rate アラートは Budget の消費速度が異常な場合にのみ通知するため、従来のアラートと比較してノイズが大幅に少なくなります。 前述の Fast Burn / Slow Burn の分類に応じて緊急度を判断できるため、深夜に対応不要なアラートで起こされるといった問題も軽減されます。
Error Budget ポリシ
Error Budget ポリシとは、Budget が枯渇した際にチーム全体が従うべきルールを事前に合意したもの です。
代表的なポリシの例を示します。
- 新機能のリリースを凍結する
- チームの工数の少なくとも 50% を信頼性改善に充てる
- ポストモーテムを実施し再発防止策を立てる
- Budget が回復するまで凍結を継続する
このポリシを事前に合意しておくことが重要です。 Budget 枯渇という客観的な事実に基づいてリリース凍結を発動できるため、特定のチームや個人への責任追及ではなく、組織全体での問題解決に向けた議論が生まれます。
Google SRE の The Art of SLOs でも以下のように述べられており、「超過時にどうするか」を経営層がコミットしてこそ組織的な意思決定ツールとして機能するという点が強調されています。
「Error Budget はそれを使い果たした場合に経営陣の後ろ盾があって初めて組織の緊張を解くことができる」
ー SLO targets need to be set with your users in mind and error budgets can only resolve organizational tensions if the consequences for exceeding them have executive backing. ー
SLO が組織にもたらすもの
SLO と Error Budget を導入することで、組織のコミュニケーション構造が変わります。
SLO 導入前:『定性的な主観』に基づいた議論
SLO がない組織では、リリースの可否やインシデント対応の判断が定性的な議論に終始しがちです。 開発チームは施策の優先度からリリースを急ぎたい一方、運用チームは障害リスクを懸念してリリースを止めたいと考えます。
双方の主張にはそれぞれ合理性がありますが、判断を裏付ける共通の指標がないため、最終的にはその場の力関係や声の大きさで意思決定が左右 されやすくなります。
SLO 導入後:『定量的な指標』に基づいた判断
SLO と Error Budget を導入すると、「リリースしてよいかどうか」を Budget の残量という数値で判断できるようになります。 例えば、Error Budget が 70% 残っている状態であればリリースを進め、30% を下回ったらリリースを控えて信頼性改善に集中する、といったルールをチーム全体で共有できます。
開発・運用・PM が同じ指標を見て議論するため、属人的な判断ではなく、定量的な根拠に基づいた意思決定が可能 になります。
SLO がもたらす 3 つの効果
1. 客観的な判断基盤
「リリースしてよいか?」が Budget 残量という数値で判断できます。 障害時の対応判断も Budget 消費量に基づくため、属人的な判断を減らせます。
2. 開発速度と信頼性のバランス
Budget に余裕があるときは開発速度を優先してどんどんリリースし、Budget が逼迫したら信頼性改善に集中するという切り替えが明確になります。 「完璧を目指して開発が止まる」という状況を防ぎ、適切なリスクテイクを促します。
3. 組織横断のコミュニケーション
開発・運用・PM・経営が同じ指標で議論できるようになります。 「なんとなく不安」という感覚ではなく「SLI が % で SLO 未達」という形で状況を伝えられるため、適切な意思決定と優先度付けが可能になります。
導入のロードマップ
SLI・SLO・Error Budget の導入は段階的に進めることが推奨されます。 最初から全サービスに完璧な SLO を設定しようとするのではなく、小さく始めて価値を実感してから広げるアプローチが現実的です。
4 つのフェーズ
- Phase 1:計測を始める(1〜2 週間)
最初から全サービスを対象にせず、1 つのサービスで SLI を定義します。 可用性 SLI だけでも始められます。 既存のモニタリング基盤(Prometheus、Datadog 等)を活用します。
- Phase 2:SLO を仮設定する(2〜4 週間)
過去データから SLI の実績値を確認し、それをもとに SLO を仮決めします。 SLO ドキュメントを作成し、ダッシュボードで Error Budget を可視化します。
- Phase 3:Error Budget 運用を開始する(1〜3 ヶ月)
Error Budget ポリシを策定し、チームで合意します。 アラートを SLO ベース(Burn Rate)に移行し、月次で SLO の達成状況をレビューします。
- Phase 4:定着・拡大(継続)
四半期レビューで SLO を見直し・調整します。 他サービスへ横展開し、SLO レビューを定例ミーティングに組み込みます。
明日からできる SRE
SLO の導入を具体的に始めるためのアクションとして以下のステップが推奨されています。
以下の表では担当ロールを記載していますが、専任の SRE チームやプラットフォームチームが存在しない組織も多くあります。 その場合は、インフラに詳しいエンジニアが「SRE / インフラ」のロールを、テックリードやマネージャが「リード」のロールを兼任する形になります。 重要なのはロールの名称ではなく、各アクションの責任者を明確にすることです。
| やること | 所要時間 | 担当 | 補足 |
|---|---|---|---|
| 自チームで最も重要な API を 1 つ選ぶ | 10 分 | チーム全員 | ユーザ影響が最も大きいエンドポイントを選定する |
| そのエラー率を過去 28 日分集計する | 30 分 | SRE / インフラ | 既存のモニタリング基盤(Prometheus、Datadog 等)から取得する |
| 「SLO をいくつに設定するか?」を議論する | 30 分 | チーム全員 | 過去の実績値をベースに、ユーザの期待と照らし合わせて決める |
| SLO ドキュメントのドラフトを書く | 30 分 | リード | 上でも記載した SLO ドキュメントのフォーマットを作成する |
最初の一歩は「1 つのサービスの 1 つの SLI」からで十分です。 重要なのは 「完璧な SLO」を作ることより、数値を計測してチームで議論するプロセスを始める ことです。 SLO の初期値が多少ずれていても、運用を通じて調整できます。
おわりに
今回のブログでは、信頼性の議論を定性的な感覚から定量的な指標に変えるための仕組みとして、SLI・SLO・SLA・Error Budget の概念と実践方法を整理しました。
押さえておきたいポイントは以下の通りです。
- SLI はユーザ体験を数値化する指標であり、CPU 使用率ではなくレイテンシやエラー率のようにユーザ視点で選ぶ
- SLO は SLI の目標値と計測期間の組み合わせであり、100% ではなく「ちょうどよい信頼性」を見つけることが目的となる
- Error Budget は SLO の裏返しとして「許容できるエラーの量」を予算化し、Budget の残量でリリースの可否を判断する
- Burn Rate(Fast Burn / Slow Burn)に基づくアラート設計により、従来の閾値アラートのノイズ問題を軽減できる
- Error Budget ポリシを事前に合意しておくことで、枯渇時のリリース凍結を客観的な数値に基づいて発動できる
これらの仕組みにより、開発・運用・PM が同じ指標を見て意思決定できるようになり、「リリースしてよいか」「今の信頼性は十分か」という問いに対して客観的な根拠を持てるようになります。 導入は 1 つのサービスの 1 つの SLI から始めれば十分で、後は運用を通じて SLO を調整していくことで組織に合った信頼性管理の基盤が育っていきます。
本ブログの内容をスライドにもまとめてみたので、是非覗いてみてください!