LLM Agent Orchestrator の設計概念を整理する
はじめに
LLM を中心とした Agent システムの実装では、ReAct パターン・Tool Use・MCP・Agent Loop・Guardrails といった多くの設計概念が登場します。 これらの概念はそれぞれ独立したものではなく、Agent がゴールに向かって自律的に動作するための仕組みとして互いに依存しています。
例えば、LLM がツールを呼び出す Tool Use は、どのツールをどの順番で呼ぶかを決める ReAct パターンの中で動作し、ツール呼び出しの結果を次の判断に使う Agent Loop の一部として機能します。
MCP はツール定義のインターフェースを標準化し、Guardrails は Agent Loop の各イテレーションで出力の安全性を検証します。 こうした概念間の関係を把握しないまま個別に導入すると、設計の全体像が見えず、どこに何を組み込めばよいかの判断が難しくなります。
今回のブログではこれらの概念を以下の 4 つのカテゴリに分類し、Agent システムの Orchestrator を軸にそれぞれの役割と関係を整理してみたいと思います。
| # | カテゴリ | 扱う概念 |
|---|---|---|
| 1 | Agent の実行モデル | ReAct パターン・Tool Use・Agent Loop |
| 2 | ツール連携の標準化 | MCP・Schema Adaptation |
| 3 | Agent の品質と安定性 | System Prompt・Context Window・Guardrails・Nudging・Error Recovery |
| 4 | 可観測性 | Observability |
なお、このブログでは、AI Agent によるブラウザ操作の自動化を具体例として取り上げますが、各概念は汎用的な Agent システムの設計に広く適用できるかと思います。
Orchestrator とは
Agent システムにおける Orchestrator は、LLM・ツール・ストレージといった複数のコンポーネントを協調動作させる中央制御者で、いわばシステムの頭脳に当たります。 与えられたゴールに対して適切なタイミングで各コンポーネントへ指示を出し、処理全体の流れを管理します。
重要なのは、Orchestrator 自身はビジネスロジックを持たない という点です。 「何をすべきか」の判断は LLM が行い、「どのように実行するか」はツールが担います。 Orchestrator はその橋渡し役として制御フローのみを管理します。
この責務分離によって、LLM の変更やツールの追加に対して Orchestrator のコードを変更せずに対応できるため拡張性の高い構造が実現します。
1. Agent の実行モデル
Agent がゴールを達成するまでの実行モデルは、ReAct パターンを基盤とした Agent Loop として実装されます。 このセクションでは ReAct パターン・Tool Use・Agent Loop の 3 つの概念を順に説明します。
ReAct パターン(Reasoning + Acting)
ReAct パターンは、2022 年に発表された論文 ReAct:Synergizing Reasoning and Acting in Language Models で提案された LLM エージェントの最も基本なパターンです。
LLM が Thought(推論)→ Action(行動)→ Observation(観察) のサイクルを繰り返すことで、複雑なタスクを段階的に解決します。
ブラウザ操作テストを例にすると、1 サイクルは以下のような流れになります。
ReAct パターンの特徴は 事前に全手順を計画しない 点にあります。 各ステップの実行結果(Observation)を見てから次の行動を決めるため、動的に変化する状況への適応が可能です。
対比されるアプローチとして Plan-then-Execute(全手順を先に計画してから実行する)がありますが、こちらは中間の状態変化に対応できない弱点があります。 UI の状態が実行の度に微妙に変化する Web アプリケーションのテストでは、ReAct パターンが固定スクリプトよりも柔軟に対応することができます。
ただし、ReAct パターンは各イテレーションで LLM を呼び出すため、イテレーション数に比例してレイテンシとコストが増加する 点に注意が必要です。
Tool Use / Function Calling
LLM はテキストの生成しか直接行えません。 ブラウザ操作・ファイル読み書き・API 呼び出しといった外部アクションは、Tool Use(Function Calling とも呼ばれる)を通じて実現します。
Orchestrator はまず利用可能なツール一覧を LLM に提示します。 LLM はその中から適切なツールを選び、呼び出し方法を構造化されたデータとして出力します。
ツールの定義には名前・引数スキーマ・説明文を含める必要があります。
説明文の品質が LLM によるツール選択の精度に直結するため、各ツールが何をするものかを明確に記述することが重要です。 説明文が曖昧だと LLM が誤ったツールを選択したり、不適切な引数を渡したりする原因になります。
Agent Loop
Agent Loop は ReAct パターンの実装形態であり、終了条件を満たすまで LLM との対話を繰り返す制御ループです。
Anthropic が公開した「Building Effective Agents」では、Agent を「LLM が環境からのフィードバックに基づいてツールをループ内で使用するシステム」と定義しています。 同記事では、手順が事前に定義された Workflow と、LLM が自律的にプロセスを制御する Agent を明確に区別しており、Agent Loop はこの Agent 側の中核的な実行構造に該当します。
終了条件には以下のようなものがあります。
- ゴールの達成
- 最大イテレーション数への到達
- タイムアウトの発生
- 回復不可能なエラーの発生
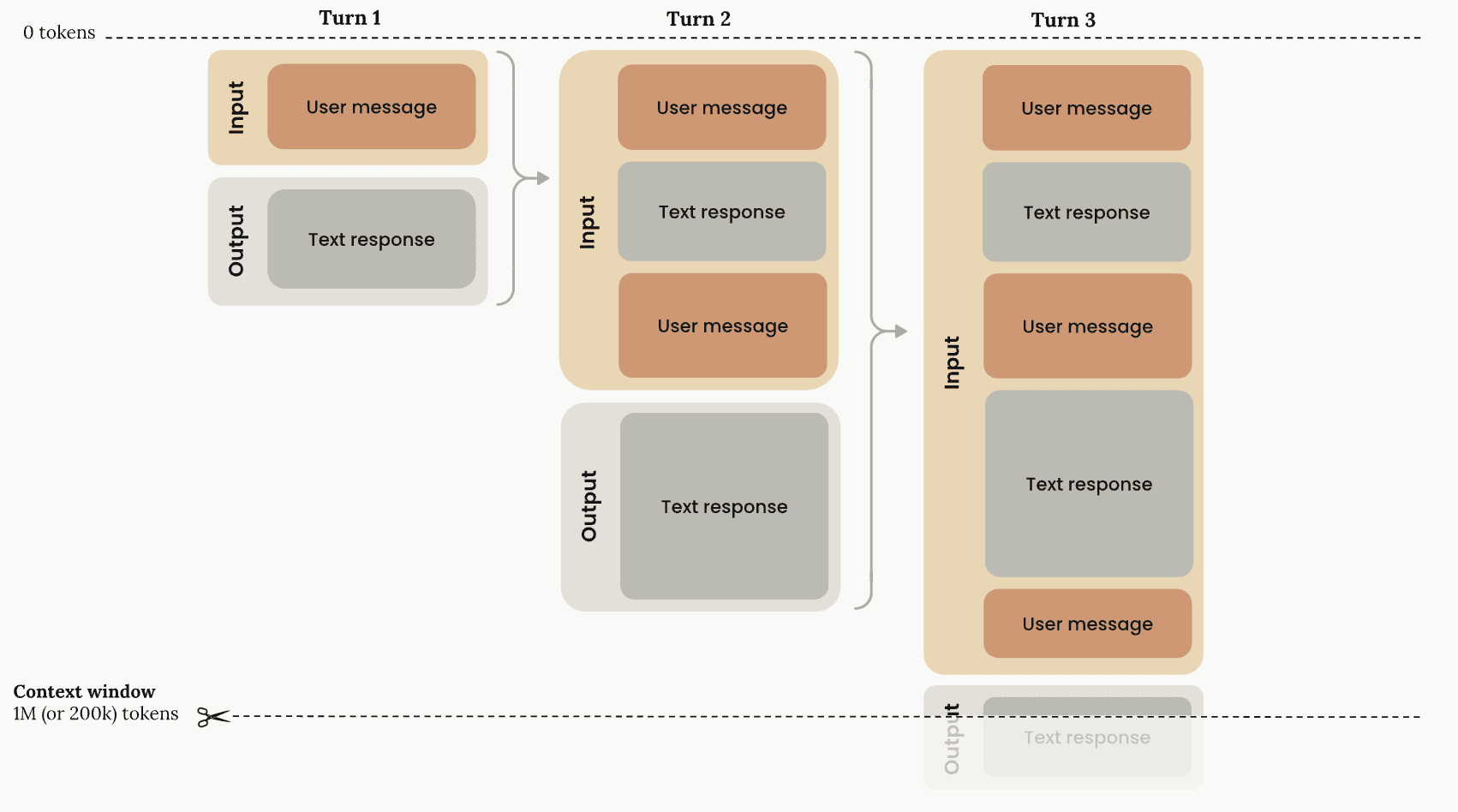
各イテレーションでは、ツール実行結果を「Observation(観察)」として LLM のメッセージ履歴に追加します。 LLM はその履歴全体を見て次の Thought と Action を生成するため、ループが進むほどコンテキストが蓄積されます。
このメッセージ履歴の積み上がりが Context Window の消費につながるため、Agent Loop と後述の Context Window 管理は密接に関係します。
2. ツール連携の標準化
Agent がどのように外部ツールと連携するかを定義するレイヤです。 MCP がツール接続の標準インターフェースを提供し、Schema Adaptation が LLM プロバイダ間の差異を吸収します。
MCP(Model Context Protocol)
MCP は Anthropic が提唱した LLM とツールを接続するための標準プロトコルです。 ブラウザ・モバイル・ファイルシステム等、異なるツールを統一的なインターフェースで扱えるように設計されています。
MCP を採用する利点は ツール提供者と利用者の疎結合 にあります。
ツール提供者は MCP サーバを実装するだけでよく、Agent 側はどんなツールでも同じ listTools() / callTool() インターフェースで呼び出せます。
MCP が普及する以前は、各 Agent がツールを直接呼び出す固有のコードを実装する必要がありました。 MCP によって ツールの定義と実装をサーバに集約し、クライアントは標準インターフェースで呼び出す というクライアント・サーバ型モデルに基づいた分離が実現しており、ツールエコシステムの拡大に貢献しています。
MCP サーバは、通常プロセス間通信(stdio)または HTTP(SSE)で通信するため、Node.js・Python・Rust 等の言語を問わず実装することができます。 Playwright・GitHub・Slack・Google Maps といった多数の MCP サーバが既にオープンソースとして公開されています。
Schema Adaptation
MCP のツール定義(JSON Schema 形式)と LLM の Function Calling 定義はフォーマットが異なるため、変換レイヤが必要になります。
Claude、GPT-4、Gemini ではそれぞれツール定義のフォーマットが異なります。
例えば Anthropic の Claude ではツール定義に input_schema フィールドを使いますが、OpenAI の GPT-4 では parameters という形式になります。
Schema Adaptation レイヤを設けることで、LLM プロバイダの切り替えを Orchestrator のコードを変更せずに実現できます。
3. Agent の品質と安定性
Agent システムを本番運用するためには、LLM の振る舞いを制御し、安定した動作を担保する仕組みが必要です。 このセクションでは System Prompt・Context Window・Guardrails・Nudging・Error Recovery の 5 つの概念を紹介します。
System Prompt
System Prompt は LLM に「あなたは何者で、何をすべきか」を伝える初期指示です。 Agent の 振る舞いを最も大きく左右する要素のひとつ であり、慎重に設計する必要があります。
- 例:AI Agent に QA のためのブラウザ操作をさせる場合の System Prompt
System Prompt はコードに埋め込まず外部で管理することで、プロンプトの改善やチューニングの度にコードをデプロイする必要がなくなります。
OpenAI は Prompt Management 機能でダッシュボード上でのプロンプト管理を提供しており、Anthropic も「Effective Context Engineering for AI Agents」で System Prompt を <instructions> や ## Tool guidance のようなセクションに構造化して管理することを推奨しています。
有効な System Prompt の設計原則は以下の通りです。
| 原則 | 説明 |
|---|---|
| 役割の明示 | Agent が何者で何をするかを冒頭で定義する |
| 入出力の形式を指定 | ツールを呼ぶかテキストで返すかの優先順位を明示する |
| 禁止事項の明示 | してはいけない操作を具体的に列挙する |
| 失敗時の振る舞いを指定 | エラー発生時にどう行動すべきかを記述する |
| 簡潔に保つ | 長すぎる System Prompt は LLM の注意を分散させる |
LLM プロバイダを切り替えた際には System Prompt の解釈に差異が生じることがあるため、動作確認が必要です。
Context Window
Context Window は LLM が一度に処理できるトークン数の上限です。 Agent Loop ではイテレーションの度にメッセージ履歴が蓄積されるため、長時間実行や複雑なタスクではすぐに上限に達する問題があります。
上限を超えると LLM はエラーを返すか、古い文脈を失って品質が極端に低下します。 以下の手法でコンテキストを管理します。
| 手法 | 説明 | 適したタスク |
|---|---|---|
| トランケーション(Truncation) | ツール結果を一定文字数に切り詰める | 大量データを返すツールの呼び出し |
| 履歴リセット(History Reset) | ステップ間でメッセージ履歴をクリアする | 独立したステップの繰り返し |
| 要約(Summarization) | 過去の履歴を LLM に要約させて圧縮する | 会話の継続性が求められるタスク |
| スライディングウィンドウ(Sliding Window) | 直近 N 件のメッセージのみ保持する | 長時間実行タスク |
各 LLM プロバイダのコンテキストサイズの目安は以下の通りです(2026 年 3 月時点)。
| モデル | コンテキストサイズ | 出典 |
|---|---|---|
| Claude Sonnet 4.6 | 1,000,000 トークン | Context windows - Claude API Docs |
| GPT-4.1 | 1,000,000 トークン | Models - OpenAI API |
| Gemini 2.5 Pro | 1,000,000 トークン | Long context - Gemini API |
コンテキストサイズが大きいモデルでも、適切なコンテキスト管理は引き続き重要です。
例えば、Lost in the Middle 問題 では、LLM が長いコンテキストの先頭と末尾に配置された情報にはよくアクセスできる一方、中間部分に配置された情報への性能が著しく低下することが報告されています。 この傾向はロングコンテキスト対応を謳うモデルでも確認されており、コンテキストウィンドウが大きいことと、その全体を均等に活用できることは別の問題です。
Agent Loop ではイテレーションを重ねる度にメッセージ履歴が蓄積されるため、重要な情報がコンテキストの中間に埋もれないよう管理する必要があります。
Guardrails
Guardrails(ガードレール)は LLM の行動を安全な範囲に制限する仕組みの総称です。 LLM は確率的な性質上、予測不可能な行動をとる可能性があるため、Orchestrator 側で制約を強制することが重要です。
| ガードレール | 目的 |
|---|---|
| イテレーション上限 | 無限ループの防止 |
| タイムアウト | 長時間実行の防止 |
| ツールブロック | 危険な操作(browser_close 等)の禁止 |
| 連続失敗中断 | 壊れた状態での無駄な実行防止 |
| コスト上限 | トークン使用量の制御 |
Guardrails の評価は Agent Loop の先頭で実施するのが基本 です。
ツール呼び出しの制限では、Allowlist 方式(使用を明示的に許可したツールのみ呼び出せる)を採用することが推奨されます。
OWASP Top 10 for LLM Applications では「Excessive Agency」(過剰な権限委譲)を主要リスクの一つとして挙げており、Agent が呼び出せるツールを必要最小限に制限し、最小権限の原則(PoLP:Principle of Least Privilege)を適用することを推奨しています。
Denylist 方式(禁止リストに含まれないツールはすべて許可)は、新しいツールが追加された際に意図せず危険な操作が実行されるリスクがあるため基本的に避けるべきです。
Nudging
Nudging(ナッジング)は LLM が期待通りに動かない場合に、追加の指示を動的に注入して軌道修正するテクニックです。
LLM は「計画を語るだけで実行しない」「同じ操作を繰り返す」「ツールを呼ばずテキストのみを返す」といった期待から逸脱した挙動を取ることがあります。 Nudging はそれを検出し、プロンプトへの追加指示(フィードバック)によって適切な行動を促します。
Nudging のロジックは Orchestrator 側に実装し、LLM の挙動パターンを監視しながら条件に応じてメッセージを注入 します。 Nudging の条件設計には、後述の Observability で収集した実行ログの分析が有効です。
Error Recovery
Error Recovery は Agent のエラーを「回復可能」と「回復不可能」に分類し、回復可能なエラーは LLM 自身にリカバリを委ねるパターンです。
ReAct パターンの強みは、エラーも Observation として LLM にフィードバックできる点にあります。 LLM はエラーの内容を把握した上で自律的にリカバリ戦略を考え、次のアクションを選択できます。
エラー分類の設計例を示します。
| エラー種別 | 分類 | 対応 |
|---|---|---|
| 要素が見つからない | 回復可能 | LLM にフィードバックし別セレクタを試みる |
| ネットワークタイムアウト | 回復可能 | リトライを促す |
| ページ読み込み失敗 | 回復可能 | リロードを指示する |
| 認証トークンの失効 | 回復不可能 | セッションを終了する |
| ブラウザプロセスのクラッシュ | 回復不可能 | セッションを終了する |
| 最大イテレーション到達 | 回復不可能 | Guardrails が中断 |
Error Recovery の設計で重要なのは LLM に渡すエラーメッセージの品質 です。 スタックトレースや内部エラーコードをそのまま渡しても LLM は適切なリカバリ戦略を立てられません。 「何が起きたか」「どの操作で失敗したか」を人間が読んでわかる形式で要約してフィードバックすることで、LLM のリカバリ精度が向上します。
4. 可観測性(Observability)
Observability は Agent の内部動作を事後に検証可能にする仕組みです。 LLM の判断はブラックボックスになりがちなため、Agent が期待通りに動作しなかった場合の原因調査において特に重要な役割を果たします。
| 成果物 | 役割 |
|---|---|
| 実行ログ(ExecutionLog) | どのツールをいつ・どの引数で呼んだか |
| スクリーンショット | 各操作時点の画面状態 |
| 動画 | 操作の一連の流れ |
| LLM の応答テキスト | LLM がなぜその行動を選んだかの根拠 |
各イテレーションでのツール呼び出し記録・LLM の推論テキスト(ReAct の Thought に相当)・スクリーンショットの 3 点が揃うことで、Agent の意思決定プロセスを追跡できます。 特に LLM の推論テキストは「なぜその行動を選んだか」の根拠を示すため、Nudging の条件設計やプロンプト改善の手がかりとしても活用することができます。
- 実行ログの構造例:
構造化されたログにより、セッション単位・イテレーション単位での集計や失敗パターンの分析が容易になります。
概念の全体像
まとめると、各概念はおよそ以下の通り組み合わさって動作します。
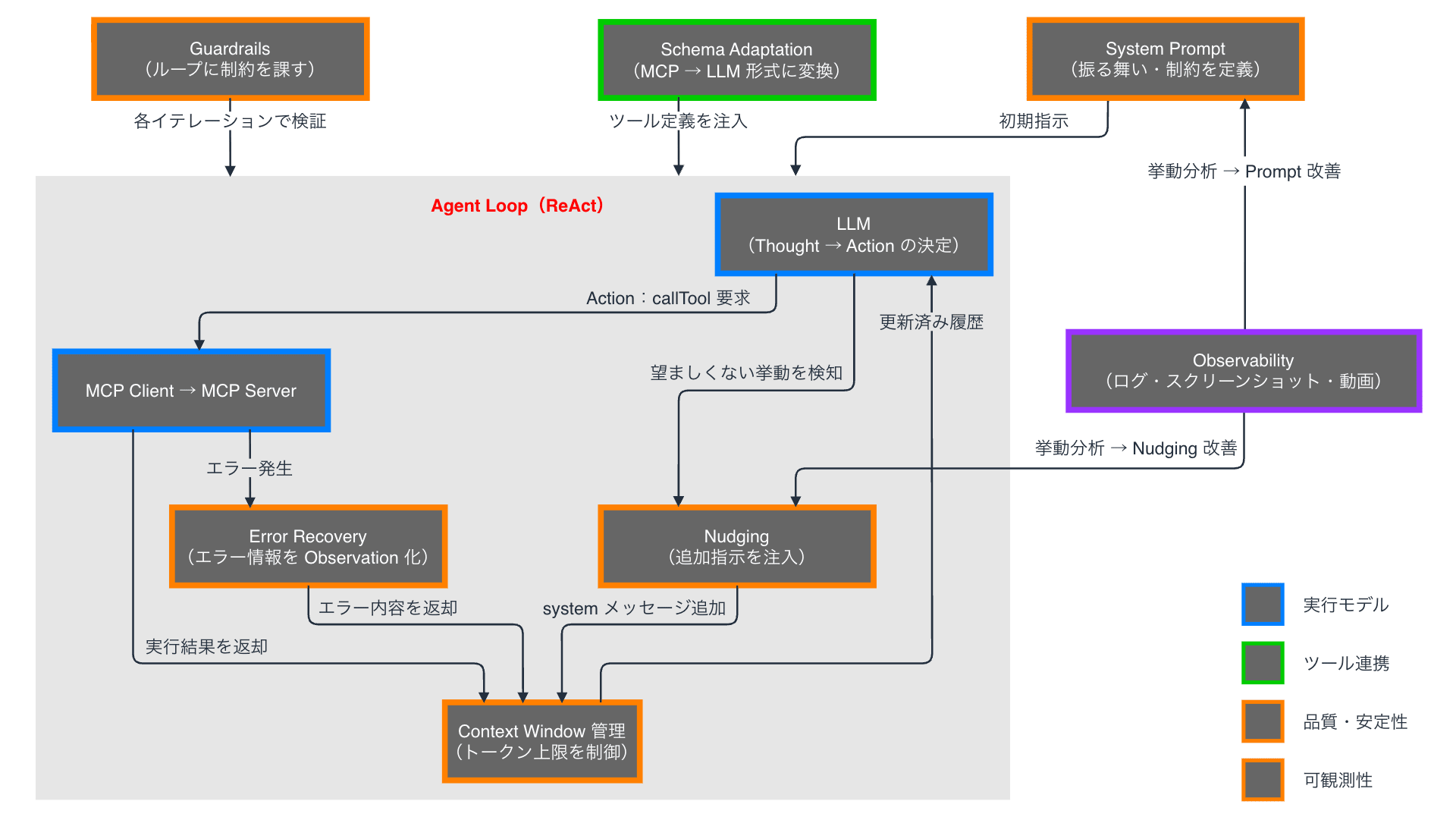
各コンポーネントの責務を改めて整理します。
| カテゴリ | コンポーネント | 役割 |
|---|---|---|
| 実行モデル | ReAct / Agent Loop | Thought → Action → Observation のサイクルを制御する |
| ツール連携 | Tool Use / MCP | 外部ツールを統一インターフェースで呼び出す |
| ツール連携 | Schema Adaptation | MCP スキーマを LLM プロバイダのフォーマットに変換する |
| 品質・安定性 | System Prompt | Agent の振る舞いと制約を定義する |
| 品質・安定性 | Context Window 管理 | トークン上限を超えないよう履歴を調整する |
| 品質・安定性 | Guardrails | 安全な範囲でのみ動作するよう制約する |
| 品質・安定性 | Nudging | LLM の挙動を動的に軌道修正する |
| 品質・安定性 | Error Recovery | エラーをフィードバックし自律的なリカバリを促す |
| 可観測性 | Observability | 内部動作を記録し事後検証を可能にする |
Agent フレームワーク
これらの概念を一から実装するのは相応の手間がかかります。 現在は Agent Loop・Context Window 管理・Observability 等を標準コンポーネントとして提供するフレームワークが複数あり、ボイラープレートの大部分を省略できます。
Google ADK(Agent Development Kit)
Google ADK は Google が 2025 年にオープンソースとして公開した Python 製の Agent フレームワークです。 単一の Agent から複数 Agent を階層化したマルチエージェント構成まで、柔軟なアーキテクチャをサポートしています。
Agent Loop と ReAct
ADK の LlmAgent クラスが ReAct スタイルの Agent Loop を自動管理します。
開発者は LLM モデルとツール・System Prompt を定義するだけで、Thought → Action → Observation のサイクルを実装できます。
マルチエージェント構成
ADK では複数の Agent を階層化して Orchestrator として機能させることができます。
SequentialAgent や ParallelAgent といったビルトインの Orchestrator Agent を使うことで、複数の Sub-Agent を逐次または並列に実行するパイプラインを宣言的に定義できます。
MCP との統合
ADK は MCPToolset を提供しており、MCP サーバのツールを Agent に組み込む際のプロトコル処理やスキーマ変換(Schema Adaptation)を自動で行います。
このため、Schema Adaptation の実装を手動で書く必要がなくなります。
Observability
ADK は実行トレースとイベントログを標準で提供します。 各 Agent の呼び出し・ツール実行・LLM の応答が自動でトレーシングされ、デバッグや品質改善に活用できます。
上で整理した概念と ADK の実装の対応は以下の通りです。
| 概念 | ADK の実装 |
|---|---|
| Orchestrator | Agent クラスが制御フローを管理する |
| ReAct / Agent Loop | LlmAgent がループを自動管理する |
| Tool Use | FunctionTool / AgentTool でツールを定義する |
| MCP | MCPToolset で MCP サーバのツールを読み込む |
| System Prompt | Agent の instruction パラメータで定義する |
| Context Window | セッション管理機能がコンテキストを自動保持する |
| Guardrails | コールバックフック(before_model_callback 等)で制約を実装する |
| Observability | トレーシング・イベントログが標準で提供される |
| マルチエージェント | SequentialAgent / ParallelAgent で階層化を実現する |
Microsoft AutoGen
AutoGen は Microsoft が開発した、複数の Agent が対話しながらタスクを解決するフレームワークです。 LLM の呼び出しだけでなく、コードの実行やヒューマンインザループ(人間の承認ステップを挟む)もサポートしています。
マルチエージェント対話モデル
AutoGen の特徴は エージェント同士が会話してタスクを解決する というアーキテクチャにあります。
GroupChat を使うことで複数の Agent がラウンドロビン形式または LLM が決定する方式でターンを回しながら問題を解決します。
ヒューマンインザループ
UserProxyAgent を用いることで、エージェントの実行中に人間の入力や承認を挟むことができます。
特に本番データへのアクセスや不可逆な操作を含む Agent フローでは、自動実行に人間の確認ステップを組み込むことが安全性の観点から重要です。
Tool Use
AutoGen では @tool デコレータで Python 関数をツールとして登録します。
MCP サポートも提供されており、MCP サーバのツールを Agent に組み込むことができます。
上で整理した概念と AutoGen の実装の対応は以下の通りです。
| 概念 | AutoGen の実装 |
|---|---|
| Orchestrator | GroupChatManager が複数 Agent のターンを調整する |
| ReAct / Agent Loop | AssistantAgent がループを内部管理する |
| Tool Use | @tool デコレータでツールを登録する |
| System Prompt | system_message パラメータで定義する |
| Guardrails | max_turns でイテレーション上限を設定する |
| ヒューマンインザループ | UserProxyAgent で人間の介入を組み込む |
| マルチエージェント | GroupChat で複数 Agent の対話を実現する |
フレームワーク選択の観点
| 観点 | Google ADK | Microsoft AutoGen |
|---|---|---|
| 言語 | Python | Python |
| 主な LLM | Gemini(他プロバイダも対応) | OpenAI・Azure(他プロバイダも対応) |
| クラウド統合 | Vertex AI | Azure AI Foundry |
| マルチエージェントのモデル | 階層化 Agent の委譲 | 対話型 Agent の議論 |
| MCP サポート | MCPToolset | MCP アダプタ |
| ヒューマンインザループ | コールバックで実装 | UserProxyAgent で標準サポート |
フレームワークを採用する場合でも、本ブログで整理した各概念の意味と役割を理解しておくことは重要です。 内部で何が起きているかを把握していなければ、意図しない挙動が発生した際のデバッグや設定の最適化が困難になります。
おわりに
今回のブログでは、LLM Agent Orchestrator の設計に関わる概念を実行モデル・ツール連携・品質と安定性・可観測性の 4 カテゴリに分類し、それぞれの役割と相互の関係を整理しました。
押さえておきたいポイントは以下の通りです。
- Orchestrator 自身はビジネスロジックを持たず、LLM・ツール・ストレージの橋渡しに徹する
- ReAct パターンの Thought → Action → Observation サイクルが Agent Loop の基盤となる
- MCP と Schema Adaptation によりツール定義と LLM プロバイダの差異を吸収する
- Guardrails・Nudging・Error Recovery は Agent Loop の各イテレーションに組み込む安全機構として機能する
- Observability で収集したデータが System Prompt や Nudging の改善を駆動する
Agent システムの挙動は LLM の確率的な性質上、事前に完全に予測することは困難です。 Observability で収集したデータをもとに System Prompt や Nudging を反復的に改善していくアプローチが現実的です。