ブラウザ操作の自動化と Vercel agent-browser
はじめに
Playwright や Selenium に代表される従来のブラウザ操作ツールは、人間がテストコードを書くことを前提に設計されています。 これらのツールを使うには CSS セレクタや XPath で要素を特定し、TypeScript や Python でスクリプトを記述するプロセスが必要です。
AI エージェントにこのアプローチを取らせると、構造的な問題が生じます。
LLM はページの DOM を直接参照できないため、input[type='search'] や .hamburger-icon といった CSS セレクタを一般的な知識から推測して生成することになりますが、一般にサイト構造はプロジェクト毎に異なるため、推測ベースのセレクタは高い確率で失敗します。
加えて、コードを生成・実行し、エラーを解釈して修正するサイクルはトークンを浪費する課題もあります。
Vercel が公開した agent-browser はこうした課題に対して CSS セレクタの推測自体を不要にする アプローチを取っています。
agent-browser はページのアクセシビリティツリーからインタラクティブ要素を抽出し、@e1、@e2 のような Refs と呼ばれる参照を割り当てます。
LLM はコードを書く代わりに、この Refs を対象とした click @e1、fill @e2 "text" のようなシンプルなコマンドを実行するだけでブラウザを操作できます。
今回のブログでは、agent-browser の Refs や セマンティックロケータ といった基本概念を整理した上で、内部アーキテクチャやトークン削減の仕組みを深掘りしてみたいと思います。
ブラウザ操作における 2 つのアプローチ
AI エージェントがブラウザを操作する方法は、大きく 2 つに分かれます。
コードベースのアプローチ
Playwright や Puppeteer を使う場合、AI は以下のステップを踏みます。
- ページの HTML 構造を解析する
- 操作したい要素を特定する CSS セレクタや XPath を生成する
- コードを生成して実行する
- エラーが出れば解釈して修正する
CSS セレクタは Web サイトの更新によって無効になりやすく、生成コストも高くなります。 コード実行環境の管理や非同期処理のハンドリングも AI に委ねられるため、エラーが発生しやすいという課題があります。
コマンドベースのアプローチ
agent-browser を使う場合、AI は定義済みのコマンドを順番に実行するだけです。
CSS セレクタを生成する必要はなく、スナップショットで得た セマンティックロケータ(@e1, @e2 のような Refs 参照)を指定する だけで要素を操作できます。
セマンティックロケータは、DOM の構造ではなくアクセシビリティツリー上の要素に紐付けられた参照であり、ページの CSS クラス名やタグ構造に依存しません。
また、各コマンドはステートレスで独立しており、ブラウザインスタンスへの参照を保持する必要もありません。
| 観点 | コードベース | コマンドベース |
|---|---|---|
| 要素の特定方法 | CSS セレクタ / XPath を生成 | スナップショットの Refs を指定 |
| エラー処理 | AI がコードを修正して再実行 | コマンドを再実行するだけ |
| 状態管理 | ブラウザオブジェクトへの参照が必要 | ステートレス |
| トークン消費 | コード生成・修正で消費が多い | コマンドと Refs だけで完結 |
以降のセクションでは、agent-browser がこのコマンドベースの設計をどのようなアーキテクチャで実現しているのか、Refs 参照・セッション分離・JSON 出力の仕組みを順に見ていきます。
Playwright MCP とは何か
agent-browser を理解する前提として、Playwright MCP の概要を整理します。
Playwright MCP は Microsoft が公開した MCP を通じて LLM がブラウザを操作できるようにするツールです。
LLM は listTools() で利用可能なブラウザ操作ツールを取得し、callTool() でツールを呼び出すことでブラウザを制御します。
Playwright MCP の主な特徴は以下の通りです。
- MCP プロトコル(HTTP / SSE または stdio)でエージェントと通信する
- ページの状態をアクセシビリティスナップショット(アクセシビリティツリー全体)として返す
- Node.js で実装されており npm パッケージとして配布されている
Playwright MCP のトークン消費問題
Playwright MCP の課題は、browser_snapshot ツールの返却値にあります。
ページ全体のアクセシビリティツリーをテキストで返却するため、1 回のスナップショットで数千〜数万トークンを消費することがあります。
Agent Loop では各イテレーションで LLM がページ状態を確認するためにスナップショットを取得します。 イテレーション数が増えるほど Context Window の消費が加速し、長いタスクでは LLM の入力コンテキストの大部分をスナップショットデータが占めることになります。
Agent Loop や Context Window の概念については こちらのブログ でまとめています。
agent-browser のアーキテクチャ
agent-browser は Vercel が開発したブラウザ自動化のための OSS(Apache-2.0 ライセンス)です。 GitHub では 28,000 を超えるスターを獲得しており、AI エージェント開発者の間で注目を集めています。
※ 名前に「browser」と付いていますが、ブラウザそのものではなく実体は CLI です。
Browser automation CLI for AI agents. Fast native Rust CLI.
AI にとって扱いやすいコマンド体系と、複雑な DOM 操作を不要にする Refs システムが大きな特徴です。 agent-browser は Rust で実装されたネイティブバイナリとして動作し、Unix ソケット経由で Daemon プロセスと通信します。
構成要素
agent-browser は 3 つの主要コンポーネントで構成されています。
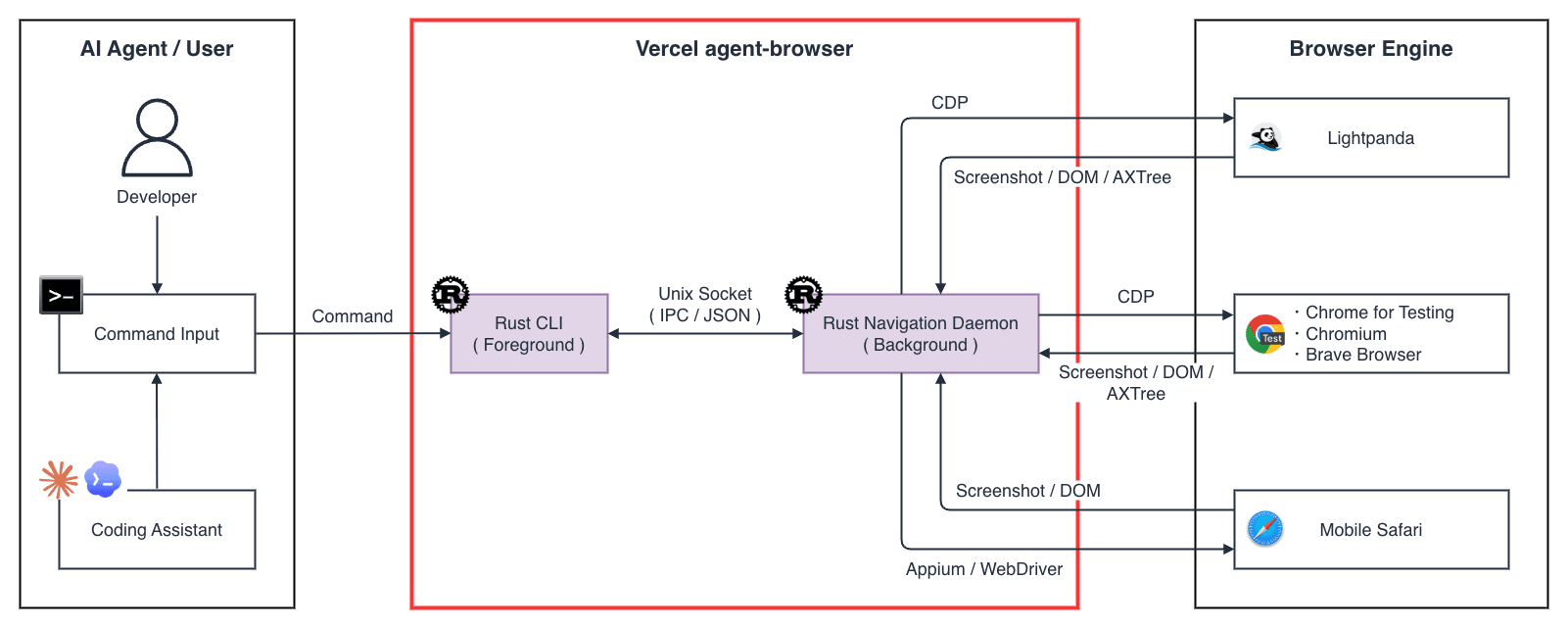
サポートしているブラウザエンジンは以下の通りです。
| エンジン | 通信方式 | 概要 |
|---|---|---|
| Chrome(デフォルト) | CDP | Chrome for Testing、Chromium、Brave 等の CDP 対応ブラウザを自動検出・起動する |
| Lightpanda | CDP | Zig 製の軽量ヘッドレスブラウザ。Chrome と同じ CDP パスで動作する |
| Mobile Safari | Appium + XCUITest | iOS Simulator 上の Safari。CDP ではなく WebDriver 経由で通信する |
--engine フラグで Chrome と Lightpanda を切り替えることができ、iOS Simulator は --device フラグで指定します。
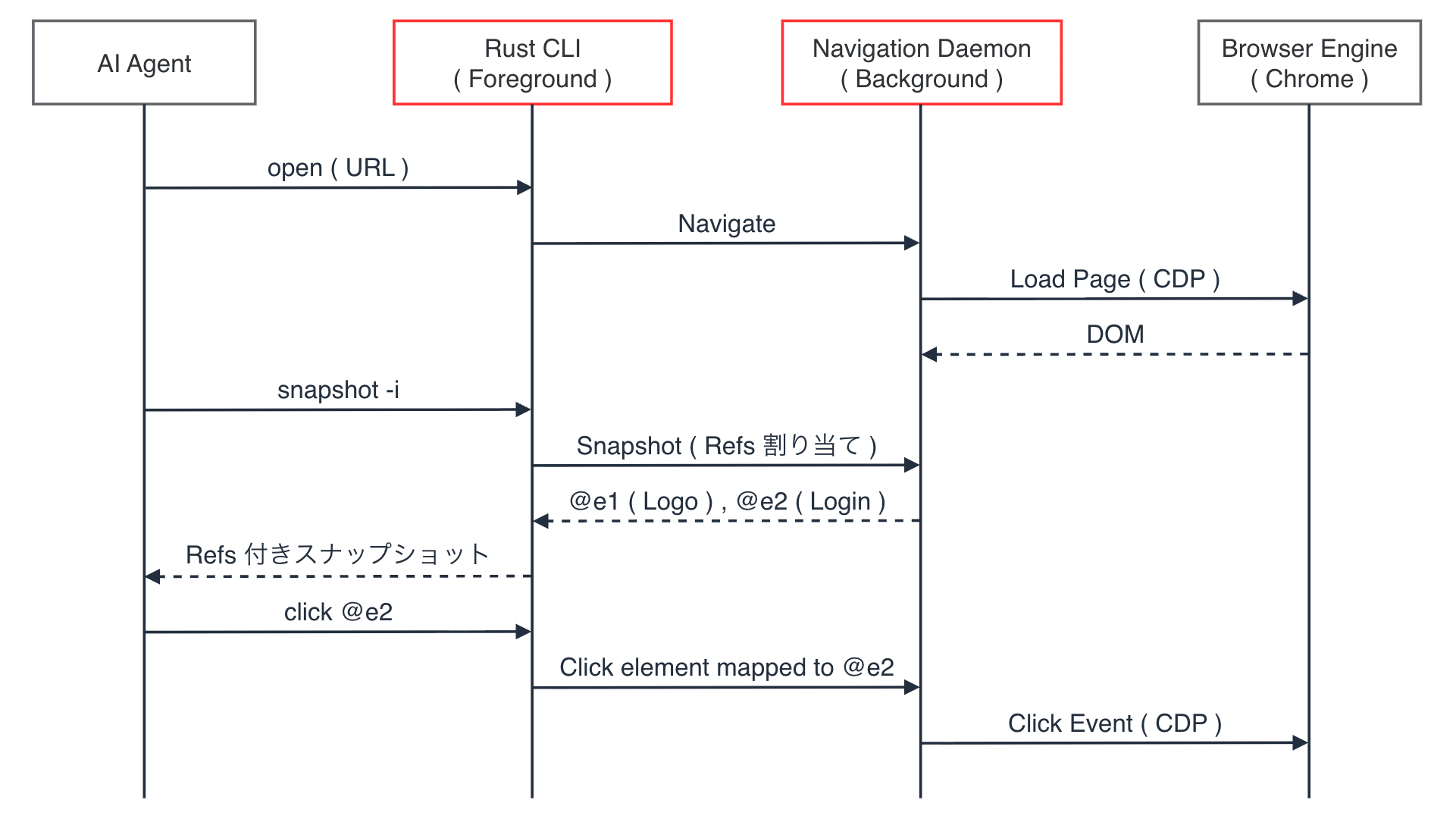
以下は、AI エージェントが agent-browser を通じてブラウザを操作する際の処理フローです。
CLI(Rust バイナリ)
エージェントや AI コーディングアシスタントが直接呼び出すコマンドラインツールです。
ホストマシン上でフォアグラウンドプロセスとして実行され、コマンドの発行と結果の受け取りを担います。
agent-browser open・agent-browser snapshot・agent-browser click @e1 のようにコマンドベースで Daemon に指示を出します。
Daemon(バックグラウンドプロセス)
CLI と同じホストマシン上でバックグラウンドプロセスとして動作し、CLI から受け取ったコマンドを解釈して CDP(Chrome DevTools Protocol) 経由で Chrome を制御します。
CLI からの最初の呼び出し時に自動起動してセッション中は Daemon プロセスとして常駐し、ソケットファイルは ~/.agent-browser/sessions/<session>/daemon.sock に配置されます。
Chrome for Testing
agent-browser が操作するブラウザプロセスです。
ローカル実行の場合はホストマシン上で、クラウドプロバイダ利用時はリモートサーバ上で動作します。
インストール時に agent-browser install を実行することで Chrome for Testing からダウンロードされます。
Playwright が同梱する Chromium とは独立した管理になるため、既存の Playwright 環境と干渉しません。
AI ネイティブ設計の 3 つの特徴
agent-browser の設計には、AI エージェントとの連携を前提にした 3 つの特徴があります。
1. ステートレスなコマンド設計
各コマンドは独立して実行できます。
Playwright では browser.newPage() で取得した page オブジェクトを保持し、page.click() のようなオブジェクト指向 API でメソッドを呼び出す必要がありますが、agent-browser では click @e1 のようにコマンドを発行するだけで済みます。
これにより、LLM がオブジェクトの参照や非同期処理の状態を追跡する必要がなくなるため、Context Window の負担を軽減できます。
2. 機械可読な JSON 出力
--json オプションを付けると、全てのコマンドの実行結果が JSON 形式で返却されます。
成否を示す success フラグや、スナップショット・取得テキスト等のデータが構造化されているため、LLM は結果をそのまま次のアクション判断に利用できます。
3. セマンティックロケータによる間接参照
snapshot -i で取得した Refs(@e1, @e2 等)は セマンティックロケータ と呼ばれ、セッション内で再利用できます。
LLM は CSS セレクタを推測する代わりに、ページのアクセシビリティツリーから割り当てられた Refs を使って操作対象を指定します。
毎回ページ全体を再取得する必要がないため、Agent Loop でのトークン消費を抑えることができます。
本サイト(ren510.dev)の場合
セッション管理
agent-browser はセッション単位でブラウザインスタンスを管理します。
--session フラグでセッションを指定することで、複数のセッションが独立したブラウザインスタンスを持つことができます。
各セッションの Daemon プロセスは独立したソケットファイルを持ち、user-data-dir も分離されます。
このため、Playwright MCP の SingletonLock 問題(後述)が根本的に発生しない構造になっています。
Refs 参照によるトークン削減
agent-browser の設計において最も重要な概念が セマンティックロケータ による Refs 参照です。
Playwright MCP がページ全体のアクセシビリティツリー(1 ページあたり 3,000 - 5,000 トークン程度)を毎回返却するのに対し、agent-browser の snapshot -i はインタラクティブ要素のみを Refs 付きで返却するため、1 ページあたり 200 - 400 トークン程度に収まります。
インタラクティブ要素のみを抽出
snapshot -i はクリック・入力・選択が可能なインタラクティブ要素のみを返します。
多くのページではコンテンツ要素(段落テキスト・見出し・リスト等)が全体の大部分を占めますが、AI エージェントが操作するために必要なのは基本的にインタラクティブ要素のみ です。
agent-browser の実装 を確認してみると、CLI の INTERACTIVE_ROLES では特定のロール(18 種類)がインタラクティブ要素として定義されていることが分かります。
snapshot -i はこれらのロールに該当する要素のみを抽出して返却します。
DOM 全体を渡す従来のアプローチでは、以下のような HTML がそのまま LLM に渡されていました。
LLM はこの HTML を解析して CSS セレクタを推測する必要がありますが、通常 クラス名やタグ構造はプロジェクト毎に異なるため、推測が外れて操作に失敗する ケースが多くなります。
agent-browser のセマンティックスナップショットでは、同じページが以下のコンパクトな形式で表現されます。
従来の Playwright ベースのアプローチでは、LLM は以下のようなコードを推測生成する必要がありました。
ここで input[type="email"] や button.login-btn は LLM が HTML 構造から推測したセレクタであり、実際の DOM と一致する保証はありません。
agent-browser では、LLM はスナップショットで得た Refs を指定するだけで同じ操作を実行できます。
Refs はスナップショット上の要素と 1 対 1 で対応しているため、セレクタを推測する必要がありません。
トークン消費の比較
Playwright MCP と agent-browser のトークン消費の違いを比較してみます。
| 方式 | 1 ページあたりの消費量 | 3 ページ遷移時の累積 |
|---|---|---|
| Playwright MCP | 3,000 - 5,000 トークン | 9,000 - 15,000 トークン |
| agent-browser(Refs) | 200 - 400 トークン | 600 - 1,200 トークン |
こちらの記事 では Playwright MCP と比較して Context Window の消費量が約 93% 削減 されると言及されています。
agent-browser では一度取得した Refs をセッション内で再利用できるため、操作の度にスナップショット全体を再取得する必要はありません。 ページ構成が変化しない限り、Refs を指定してコマンドを発行するだけで済むため、イテレーションを重ねてもトークン消費の増加が緩やかになります。
削減率はページの複雑さに依存しますが、要素数が多くコンテンツテキストが豊富なページほど削減効果が大きく なる特徴があります。
diff モードによる差分取得
agent-browser はスナップショットの差分取得(snapshot --diff)にも対応しています。
操作後に変化した部分のみを取得することで、どの要素が追加・変更されたかをより少ないトークンで把握することができます。
フォーム送信後のエラーメッセージの確認やページ遷移後に変化した要素の把握といった、変化した箇所だけを知りたい場面で有効です。
annotated スナップショットの活用
--annotate フラグを使うと、インタラクティブ要素に番号ラベルを重ねたスクリーンショットを取得できます。
テキストだけでは判別しにくい複雑なレイアウトや、同じ名前のボタンが複数存在する場合でも、視覚情報と Refs を組み合わせることで正確な要素の特定ができます。
Playwright MCP との設計比較
agent-browser と Playwright MCP は、どちらも AI エージェントのブラウザ操作を支援するツールですが、設計思想と接続方式に大きな違いがあります。
通信プロトコルの違い
- Playwright MCP(@playwright/mcp)
- agent-browser
| 項目 | @playwright/mcp | agent-browser |
|---|---|---|
| プロトコル | MCP over SSE / stdio | CLI + Unix Socket |
| 実装言語 | Node.js | Rust(CLI + Daemon) |
| セッション管理 | 固定 user-data-dir で 1 ブラウザ | --session フラグでセッション別に分離 |
| 並行セッション | 不可(SingletonLock) | 可能(セッション毎に独立) |
| ページ状態の取得 | アクセシビリティツリー全体 | セマンティックロケータ付きスナップショット |
| LLM の操作方式 | CSS セレクタベース | @e Refs 参照(セレクタ推測不要) |
| トークン効率 | 3,000 - 5,000 tokens / ページ | 200 - 400 tokens / ページ(約 93% 削減) |
| MCP 対応 | 対応 | 非対応(CLI 直接呼び出し) |
| コマンド参照 | プロンプトにハードコード | --help 出力からの動的注入が可能 |
| メモリ消費(Daemon) | 約 140MB(Node.js + V8) | 約 7MB(Rust バイナリ) |
SingletonLock 問題
Playwright MCP で複数の並行テストが同一の user-data-dir を共有する構成では、Chrome の SingletonLock 問題が発生します。
Chromium の ProcessSingleton は、同一の user-data-dir に対して複数のブラウザプロセスが同時に起動することを防ぐ排他制御の仕組みです。
同じディレクトリを指定した 2 つ目のプロセスは、既存プロセスにプロセス間通信(IPC:Inter-Process Communication)でシグナルを送り即座に終了するため、Playwright はこれを CDP 接続前にプロセスが消えたと判定してエラー を返します。
agent-browser はセッション毎に独立した Daemon プロセスと user-data-dir を持つため、この問題が 構造的に発生しません。
MCP 非対応という制約
agent-browser の注意点として、MCP プロトコルに対応していないことが挙げられます。
LLM エージェントが MCP クライアントとして動作する実装(MCPBridgeClient 等)では、そのまま agent-browser を差し込むことができません。
agent-browser は CLI として直接呼び出す設計を取っています。
Claude や Codex のようなコーディングアシスタントから直接呼び出す場合は、agent-browser --help の出力をスキルとして与えることで LLM にコマンド体系を学習させ、CLI を直接実行させるアプローチが想定されています。
この --help 出力を起動時に動的に取得して LLM のプロンプトに注入する方法を取ると、agent-browser がアップデートされて新しいコマンドが追加された場合にも自動で対応できるため、プロンプトのハードコードによるメンテナンス負荷を低減できます。
既存の MCP ベースのエージェント実装から移行する場合は、エージェントの実行層を CLI コマンド呼び出しに変更する必要があります。
batch コマンドによるレイテンシ削減
CLI ベースの設計ではコマンドを 1 つずつ実行する度に往復のオーバーヘッドが発生しますが、batch コマンドを使うことで複数のコマンドを 1 回の呼び出しにまとめることができます。
バッチ実行を使うことで、LLM が生成した一連の操作コマンドをまとめて送信でき、コマンド毎の往復レイテンシを削減できます。
主要コマンドと AI エージェントのワークフロー
基本ワークフロー
AI エージェントが agent-browser を使う際の基本パターンは以下の通りです。
このワークフローにおいて、LLM は snapshot -i の出力(Refs リスト)と各コマンドの実行結果のみをコンテキストに保持すればよく、ページ全体の DOM やアクセシビリティツリーを保持する必要がありません。
セッションの並列実行
複数の独立したセッションを並列に実行する場合、--session フラグでセッションを分離します。
各セッションは独立した Daemon と Chrome インスタンスを持つため、互いに干渉しません。
クラウドブラウザプロバイダとの統合
agent-browser はローカル Chrome だけでなく、複数のクラウドブラウザプロバイダと統合できます。
| プロバイダ | 用途 |
|---|---|
| Browserless | クラウドブラウザインフラ(セルフホスト対応) |
| Browserbase | リモートブラウザインフラ(エージェント向け) |
| Browser Use Cloud | AI エージェント向けクラウドブラウザ |
| AWS Bedrock AgentCore | AWS 統合のクラウドブラウザセッション |
| iOS Simulator | モバイル Safari のテスト(macOS + Xcode 必須) |
プロバイダの切り替えは -p フラグか環境変数で行います。
コマンド体系は変わりません。
ローカル実行時と同じコマンドが使えるため、例えば、ローカルで開発して CI/CD はクラウドブラウザで実行するといったワークフローをシームレスに実現することができます。
Rust ネイティブ実装の性能特性
agent-browser の CLI と Daemon は Rust で実装されています。
初期バージョンでは CLI が Rust、Daemon が Node.js + Playwright という構成でしたが、v0.20.0 以降では Daemon プロセスも Rust ネイティブに移行され、Playwright を経由せず CDP で直接ブラウザと通信する構成に変わっています。
| 指標 | Node.js Daemon(旧) | Rust ネイティブ Daemon(現行) |
|---|---|---|
| Daemon RSS | 約 140MB | 約 7MB |
| コールドスタート | Node.js 起動時間あり | 単一バイナリで高速 |
| 配布サイズ | npm + Playwright Chromium 含む | バイナリ + Chrome for Testing のみ |
RSS(Resident Set Size):プロセスが実際に物理メモリ上に確保しているメモリ量を表す指標
コマンドレイテンシ(navigate・snapshot・click 等)の大部分は Chrome の CDP 処理時間に依存するため、Daemon の実装言語による差は小さいと報告されています。
Rust 実装の主なメリットはメモリ消費とコールドスタート速度にあります。
Command latency is dominated by Chrome (CDP round-trips), not the daemon. Both daemons are thin relays between the CLI and Chrome, so per-command speedups are typically small.
特に長時間動作する CI 環境やメモリが制約されたコンテナ環境では、Daemon が 7MB で動作することの恩恵が大きくなります。
CI 環境でテストケース毎に新しいセッションを立ち上げる場合、コールドスタートのコストがテスト全体の実行時間に蓄積されます。 特に多数の短いテストケースを逐次実行するシナリオでは、コールドスタート速度がスループットに直結します。
Observability ダッシュボード
agent-browser には v0.25.1 以降で Observability ダッシュボードが組み込まれています。
agent-browser stream enable でリアルタイムの WebSocket ストリーミングを有効化し、ブラウザ上でセッションの状態・コマンド履歴・LLM との対話を確認することができます。
ダッシュボードには AI チャット機能も統合されており、自然言語でブラウザ操作を指示することもできます。
AI チャットによるブラウザ操作
agent-browser の chat コマンドを使うと、自然言語の指示から agent-browser のコマンドを自動生成・実行できます。
この機能は Vercel AI Gateway を経由して LLM を呼び出すため、事前に API キーの設定が必要です。
AI Gateway の利用にはクレジットが必要ですが、登録時に $5.00 分のディスカウントが付与されるため、試用の範囲であれば無料で利用できます。
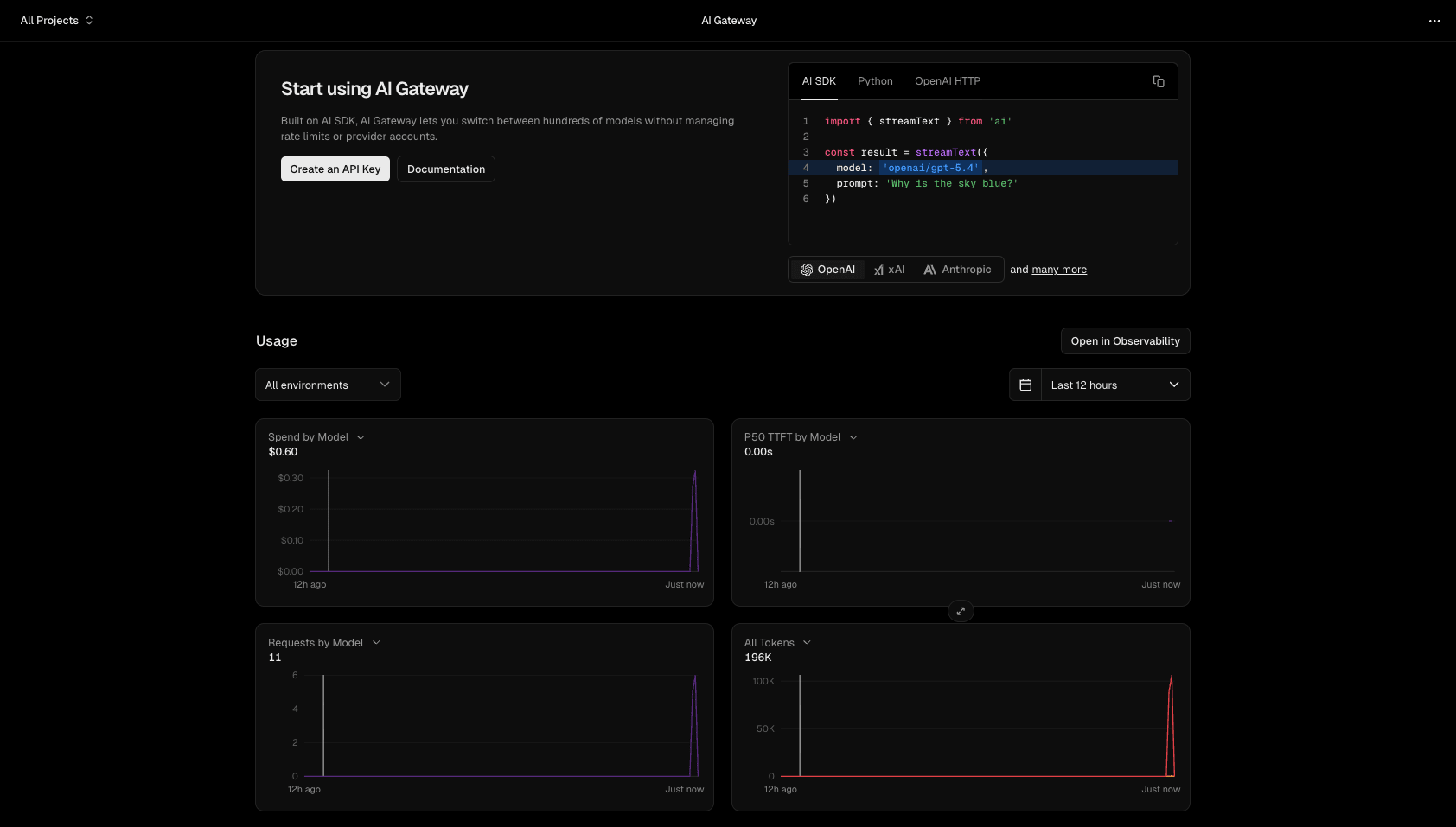
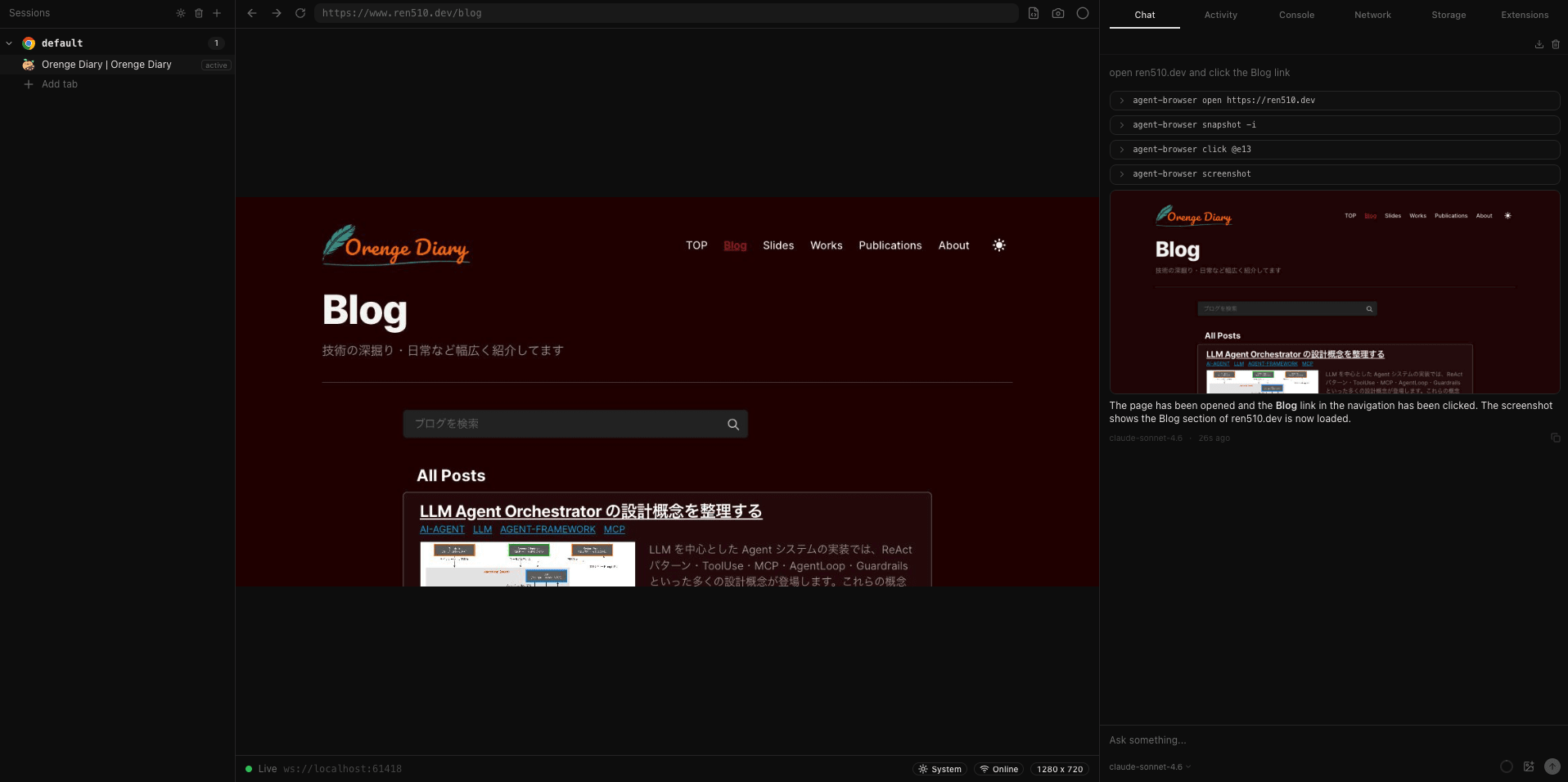
以下は、実際に chat コマンドで本サイト(ren510.dev)のブログページに遷移した例です。
「open ren510.dev and click the Blog link」という自然言語の指示から、LLM が open → snapshot -i → click @e13 → screenshot の 4 コマンドを自動生成し、順番に実行しています。
snapshot -i で取得した Refs から Blog リンクに該当する @e13 を特定し、クリックしていることが分かります。
実際に snapshot -i を実行してみると、以下の通り、Blog へのリンクが @e13 として Refs 付きで返却されていることが確認できます。
CLI での chat コマンドに加え、ダッシュボード(デフォルト http://localhost:4848)の Chat タブからも同じ操作が可能です。
- 初期画面
- Chat から指示を出した後
おわりに
AI エージェントによるブラウザ操作では、CSS セレクタの推測生成やトークンの浪費が構造的な課題となっていました。
agent-browser は、アクセシビリティツリーから Refs を割り当てることでセレクタの推測を排除し、snapshot -i によるインタラクティブ要素の絞り込みでトークン消費を削減しています。
agent-browser が採用しているアクセシビリティツリーベースの要素参照やトークン削減の概念自体は、Building Browser Agents や WebGames ベンチマーク といった論文で研究されている手法に基づいています。 agent-browser はこれらの知見を CLI ツールとして実装したプロジェクトで、今年 1 月にリポジトリが公開されたばかりです。 2026 年 4 月時点では GA しておらず情報量が少ないのが実情です。
本ブログでは Playwright MCP との比較についても触れましたが、両者は設計思想が異なります。 Playwright MCP はブラウザ操作を MCP プロトコルで標準化することに主眼を置いており、agent-browser は AI エージェント向けのトークン効率とセレクタ推測の排除に焦点を当てています。 自身のエージェントがどのような実行方式を取っているかに応じて、適した方を選択してみてください。