SRE NEXT 2025 現地参加レポート
はじめに
2025 年 7 月 11 日、12 日に TOC 有明で開催された SRE NEXT 2025 に行ってきました。
SRE NEXT は 2022 年から毎年開催されていますが、現地参加するのは今回が初めてでした。
本カンファレンスは「Talk NEXT」をテーマに、SRE が担う幅広い技術領域や組織、人材育成について議論し、新たな知見を得ることを目的に開催されました。
今回のブログでは、聴講したセッションを掻い摘んでリキャップしようと思います。
【基調講演】Fast by Friday: Making performance analysis fast and easy
- Brendan Gregg
- Intel Fellow
今年の基調講演は Brendan Gregg 氏でした。 Brendan 氏といえば、Performance Engineering や Observability の第一人者としても有名ですが、なんと今回は直接来日して現地登壇されていました!
僕も最終日の懇親会では少しだけお話しすることができました 😇
Brendan 氏 の書籍:
セッション概要
基調講演では、「月曜日に報告されたパフォーマンス問題を金曜日までに解決する」という「Fast by Friday」についての講演でした。 「Fast by Friday」とはプログラミング言語のランタイムや OS に対する要件、思考様式、行動への呼びかけを含んだ「思考実験」であり「ビジョン」です。 最終的には SRE がダッシュボードを活用し、5 分で問題を解決できる「Fast by Five Minutes」が目指されています。
eBPF 等の最新技術を活用し、実際にシステムパフォーマンス分析を「見る(Seeing)」だけでなく「解決する(Solving)」フェーズへと進化させるための実践的なアプローチが紹介されました。
詳細
パフォーマンス分析の変遷
パフォーマンス分析の歴史を 4 つの時代に分類する。

- 第 1 期(1950s - 1960s 初頭):シリアルコンピューティング時代
ソフトウェアメトリクスはほとんど存在せず、ハードウェア最適化が中心となった時代。
- 第 2 期(1960s - 2000s):タイムシェアリング OS の登場
Multics や時分割 OS(Apollo 月着陸船誘導コンピュータ等)の登場により、ソフトウェアメトリクスが誕生。
この時代になると、複数のタスクを同時に実行する際のパフォーマンス問題(例:Apollo 月着陸船の 1201/1202 アラーム)が特定され始め、スケジューラの実行キュー長やディスク IOPS 等の新しい種類のソフトウェアメトリクスが登場。 パフォーマンスエンジニアは、少数のメトリクスからカーネル内部等の見えない部分を推測する能力に優れていた。
- 第 3 期(1990s 初頭 - 現在):「Seeing Everything(すべてを見る)」時代
DTrace や eBPF 等の動的 Instrumentation の開発が始まる。
OSS が不可欠となり、コンピュータ内部のすべてを見ることができるようになった。
ちなみに、Brendan 氏は DTrace Toolkit を 2000 年代から普及させ、現在では 500 以上のパフォーマンス分析ツールを公開しているみたいです。(やばすぎる...。)
- 第 4 期:「Solving Everything(すべてを解決する)」時代
そして、ここが今回のテーマである「Fast by Friday」です。
「見る」だけでなく「解決する」ことに焦点を当ててます。 Brendan 氏は Netflix での経験から、専門家でないエンジニアでも使いやすいソリューションベースのツールの必要性が増したと話していました。
現代の課題:なぜ解決に時間がかかるのか
現代のコンピューティング環境は、以前に比べて格段に複雑化している。
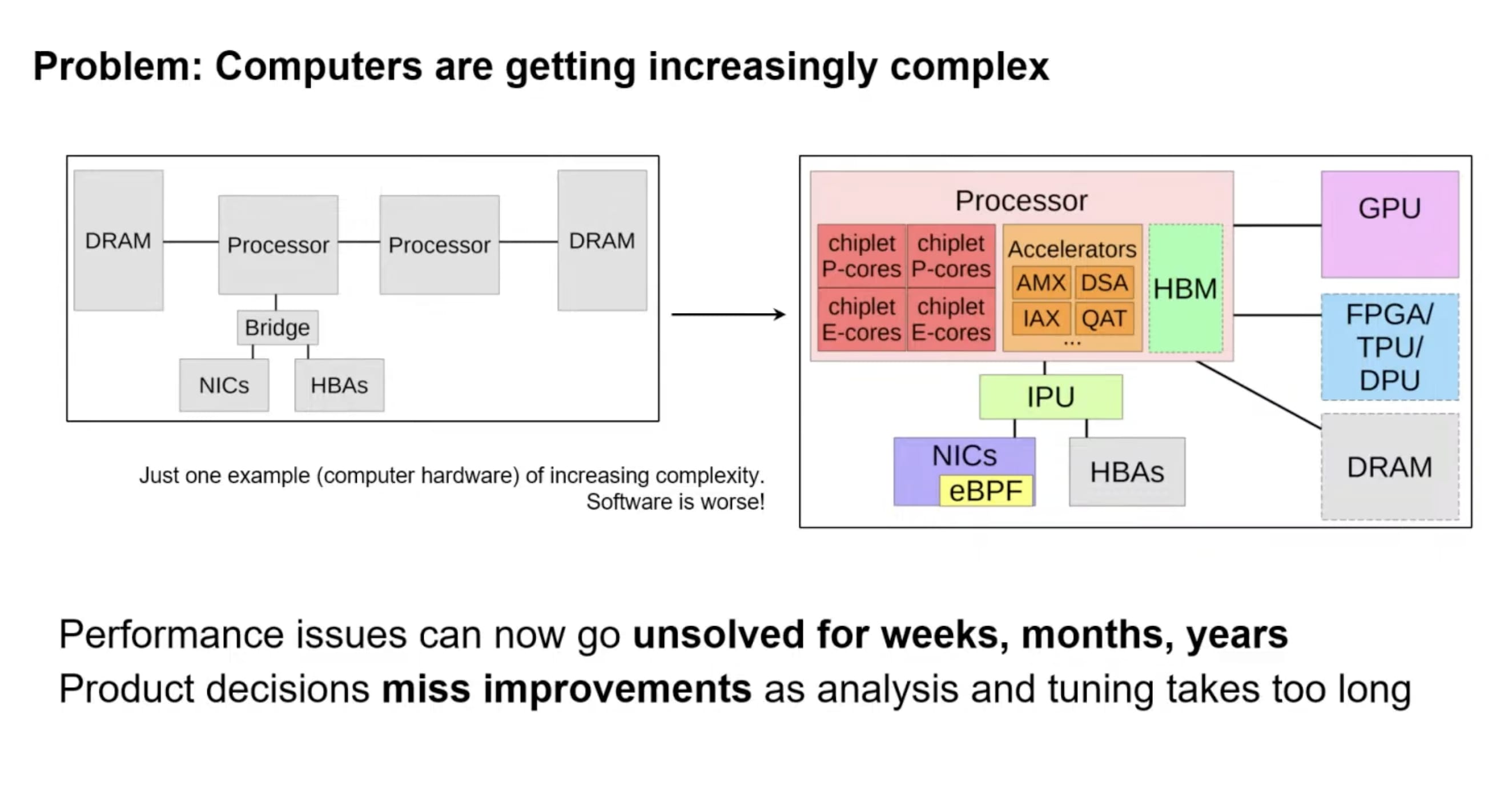
- ハードウェアの複雑化
以前のような、メモリ(P-core / E-core / IPU / HBM)、アクセラレータ(QAT / IAX)、プロセッサ(GPU / FPGA / TPU)等、シンプルなアーキテクチャとは異なり、これらの機能が利用されているか、性能向上に貢献しているかを把握することが困難になっている。
- ソフトウェアの複雑化
Kubernetes、Docker、サイドカー、多重レイヤと抽象化等が絡み合う。
これらの要因により、分析に時間が掛かり過ぎたり、リグレッションが解決されなかったりする事態が発生しており、パフォーマンス問題の解決に数ヶ月を要することも珍しくない。
Fast by Friday の実践フロー
Fast by Friday における日毎の具体的なアクティビティは以下の通り。

事前準備(Before Monday):重要な分析ツールのインストール
問題発生時に apt get update をしている時間はない。
sysstat等の必須ツールのインストール- スタックトレースとシンボルの修正
- コンテナや Kubernetes での eBPF / トレースオプションの有効化
- パフォーマンスエンジニアへの SSH ルートアクセスの確保
- システム機能図の把握
月曜日:問題の定量化と初期診断
- Problem Statement Method による問題の定量化:ログインせずにパフォーマンス問題を明確する。「なぜ問題だと思うのか?」「最近の変更は?」「問題をレイテンシや実行時間で表現できるか?」等を問う。
- 静的パフォーマンスチューニング:負荷がかかっていないシステムで、ハードウェア / ソフトウェアのバージョン、過去のエラー、設定等を確認する。
- 負荷 vs 実装の問題:パフォーマンス問題が単なる負荷の増加によるものか、実装の問題かを判断する。
火曜日:原因コンポーネントの特定
- 最近の問題チェックリスト/ダッシュボード:過去のトップの問題や既知の問題を確認する。
- サブシステムの排除:限られた時間で全てを詳細に分析することは困難なため、Health Traffic Lights 等を用いて健全な部分を無視し、問題のある部分に焦点を当てる。
- コンポーネントの無実化(Exoneration):実験的テストやマイクロベンチマーク、eBPF ツール(
BIO snoop,exec Snoop等)を実行して特定のコンポーネントが健全であることを証明する。
水曜日:コードパスの特定
- Profiling:多くのパフォーマンス問題を解決する。
- Flame Graphs:ソフトウェアの全体像を把握する。
木曜日:レイテンシとクリティカルパス分析
- レイテンシのドリルダウン:
biodis等のツールでレイテンシ分布を確認する。 - クリティカルパス分析:環境内や Web サイトのロードにおけるすべての接続を調査してエンドユーザのパフォーマンスに影響を与えるレイテンシに焦点を当てる。
- ゼロ Instrumentation ツール:eBPF と Uprobes を使用し、ソフトウェアを変更せずにライブラリや API コールを Instrumentation する。
金曜日:アルゴリズムの効率性
- 効率的なアルゴリズムの採用:コードの効率性を改善することで、最大のパフォーマンス向上を得られる可能性がある。(※ 業界全体として未熟な分野)
- 効率性の比較の難しさ:実際の顧客環境では比較対象データが不足しており、自分のコードがどの程度効率的かを判断するのが困難。
- 「これは 8 倍速くなるはずだ」といった具体的な改善点を示すツールや、「リクエストあたりの炭素排出量」の測定等が望まれる。
パフォーマンスマントラ
根本原因特定後、どう対処すべきかの 7 つの修正指針(マントラ)の紹介。

- Don't do it(やらない):不必要な作業を排除する。コードが必要なければ削除するのが最も効果的。
- Do it, but don't do it again(二度とやらない):キャッシュを活用し、一度行った作業を再利用する。
- Do it less(回数を減らす):I/O をまとめて大きな単位で処理する等。
- Do it later(後でやる):非同期 I/O やバックグラウンドでの書き込み等、作業を遅延させる。
- Do it when they're not looking(ユーザがいないときにやる):バックアップを夜間に行う等、ユーザ体験に影響しない時間帯に行う。
- Do it concurrently(並行してやる):並行処理を活用する。
- Do it cheaper(安くやる):より安価な方法やリソース効率の良い方法で行う。
所感
「Fast by Friday」には月曜から金曜まで何を実践すべきかという具体的なエンジニアリングプロセスが盛り込まれています。 特に「コンポーネントの無実化(Exoneration)」という考え方は、複雑な分散システムにおいてトラブルシューティングを迅速化する鍵だと感じました。
また、「Fast by Five Minutes」に対しては、今後 AI の活用等も盛り込まれてくるのではないかと思います。
Day 1 セッション
SRE へのサポートケースを AI に管理させる方法
- Ubie 株式会社
- 飯國 隆志
セッション概要
医療領域に特化したプロダクトを展開する Ubie において、SRE チームへの問い合わせ対応(Toil)を生成 AI を活用して効率化した事例紹介です。
月間 1,200 万人以上が利用する生活者向けサービスや 15,000 件以上の医療機関向けサービスを支える中で、インフラへの問い合わせ対応が SRE の稼働を圧迫している現状がテーマとなっていました。
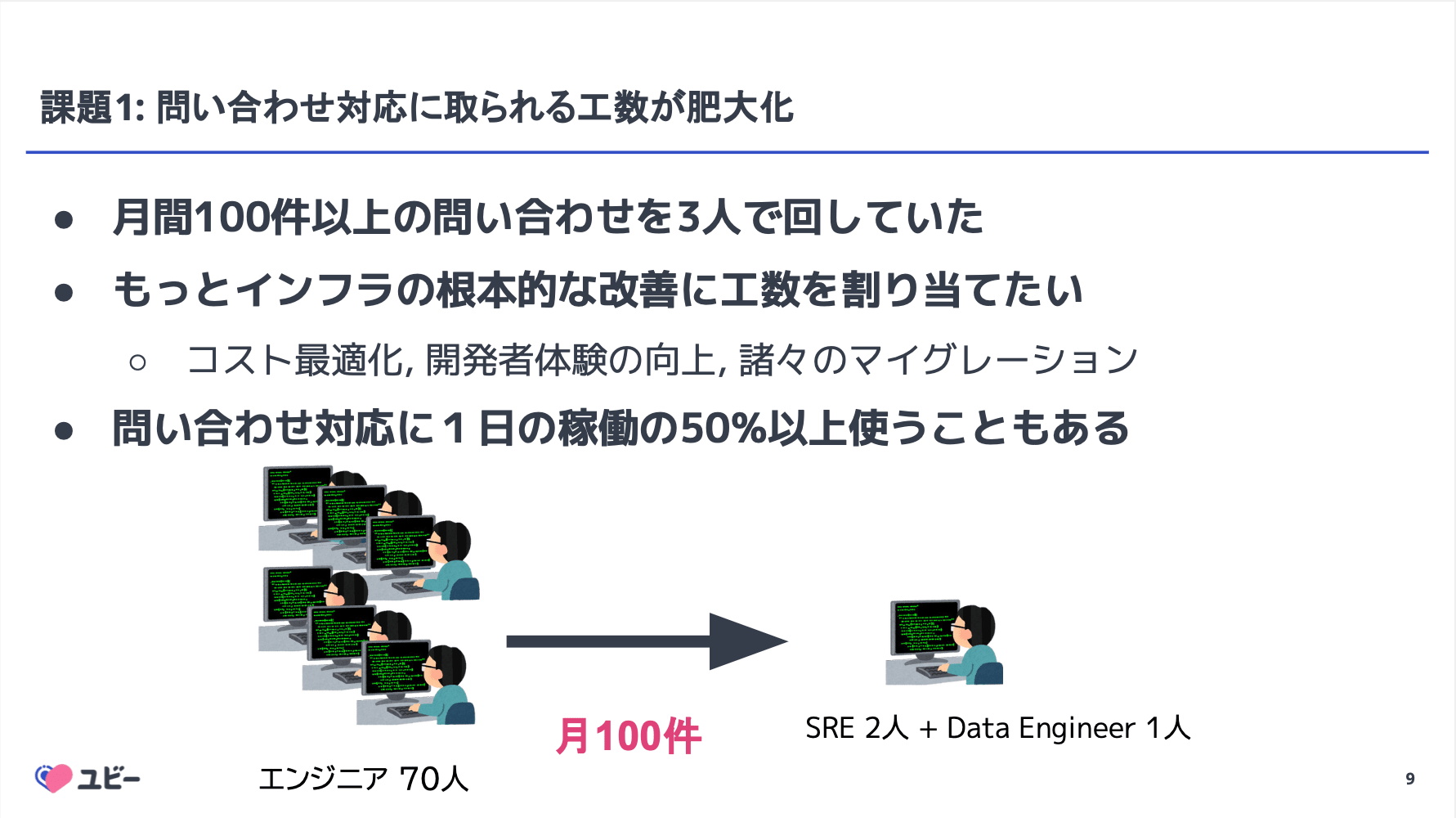
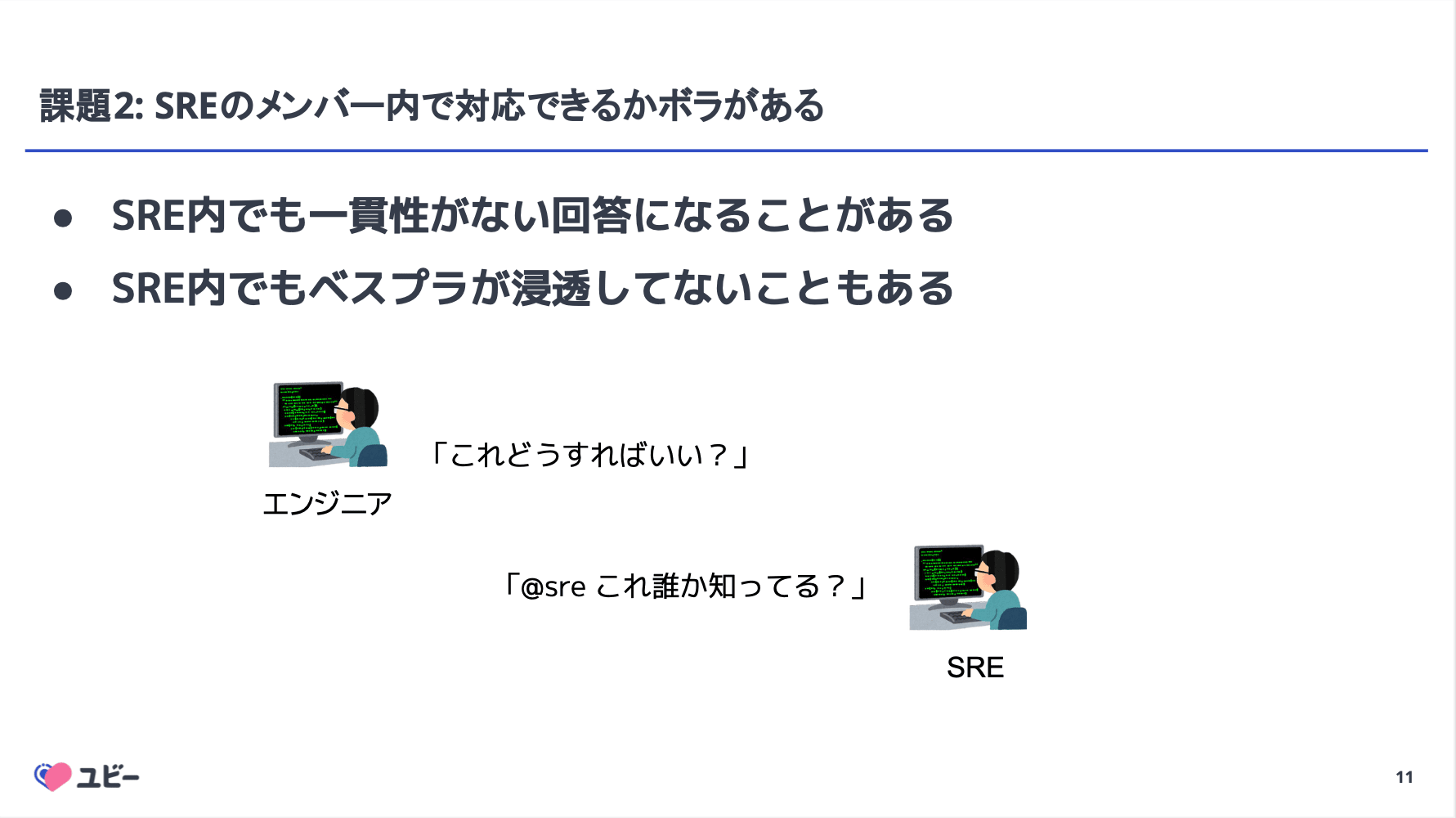

この課題に対し、Ubie では自社開発の AI チケット管理システム「infra-help-otter」を導入。 Slack スレッド作成をトリガにチケットを自動生成し、AI が過去のサポートケースや社内ドキュメントを検索して回答案を提示する仕組みを構築しました。 これにより、優先度判定やアサインの自動化、ステータス管理の Bot 化を実現し、管理工数の大幅な削減に成功したとのことです。
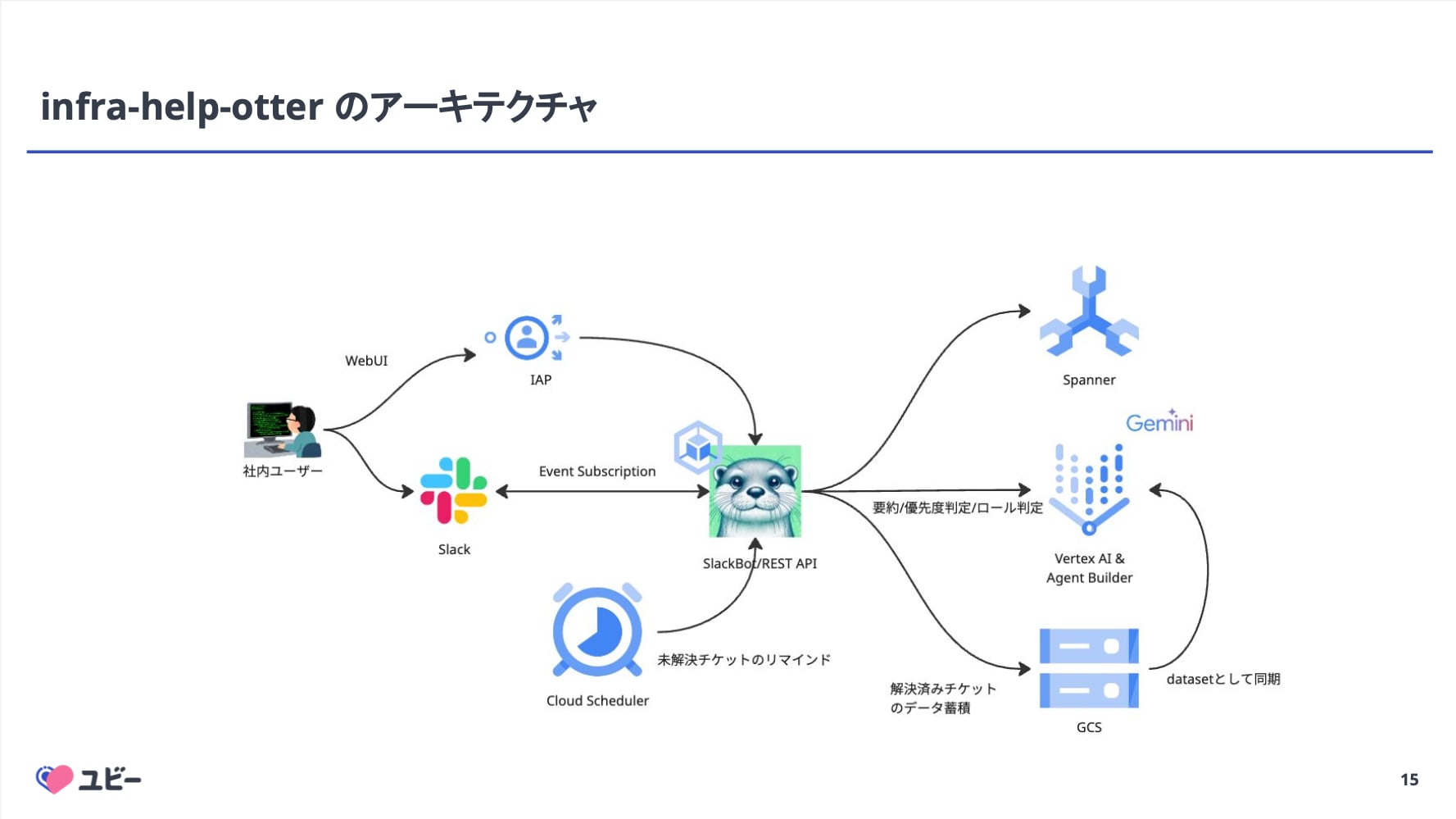
特筆すべきは、「AI のために人間がドキュメントを書く」というオンボ戦略です。 AI がドメイン知識を持たない問題を解決するため、SRE は問い合わせに直接答えるのではなく、Cursor 等を活用してドキュメントを書き、それを Vertex AI Search で検索可能にするアプローチを採用していると紹介されました。 この取り組みにより、自己解決率の向上だけでなく、ドキュメント文化の醸成という副次的な効果も生まれているようです。
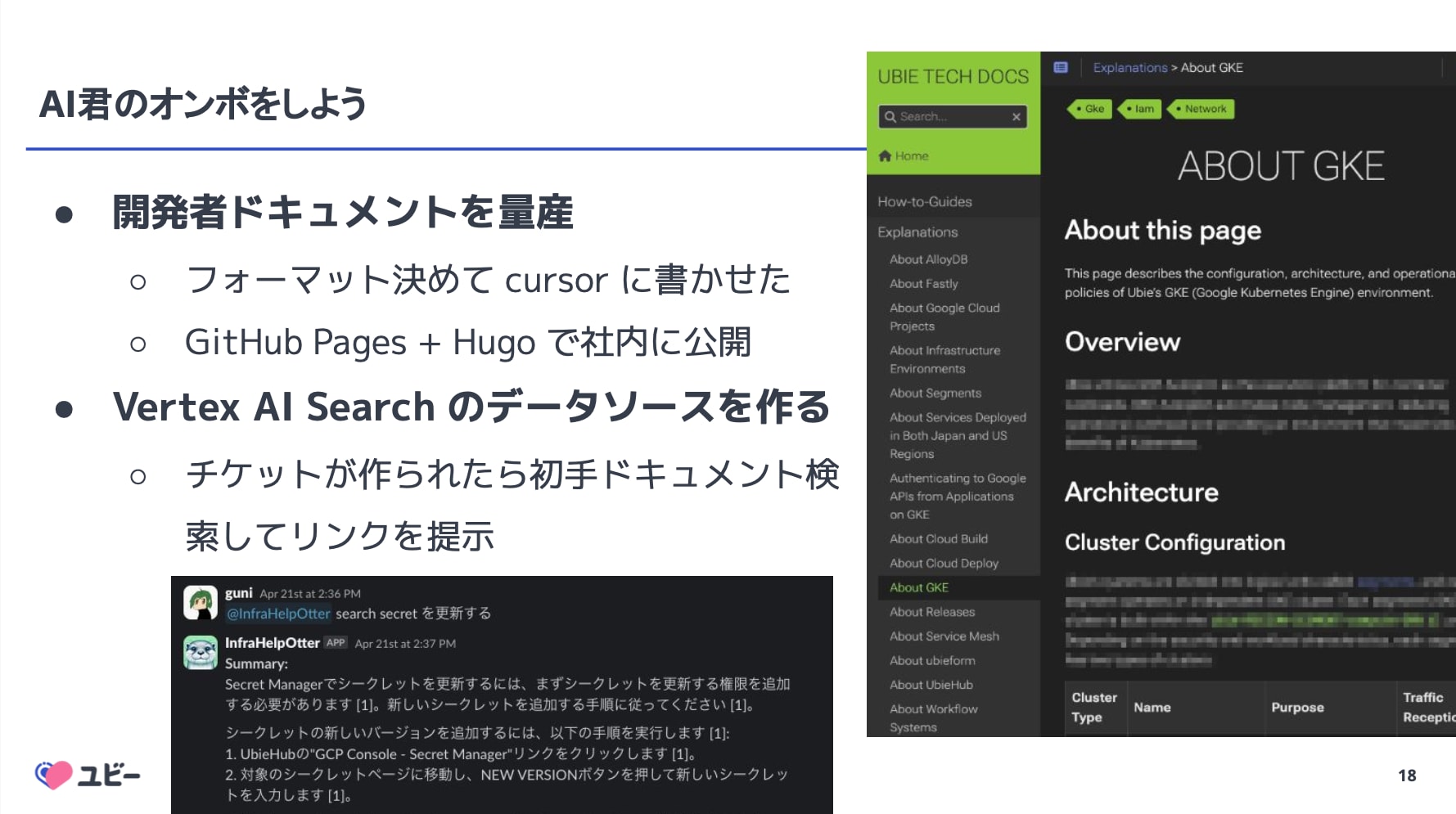
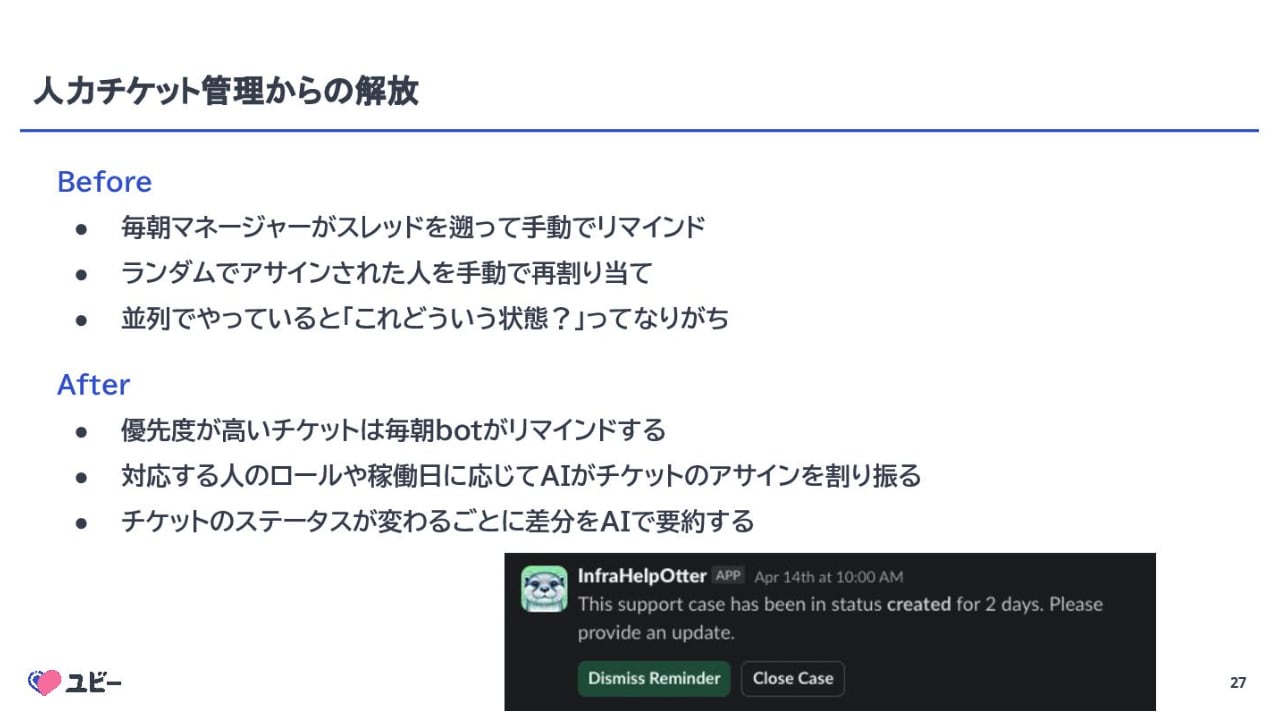
所感
「問い合わせ対応を減らすために、AI に答えさせる。 そのために人間はドキュメントを書く」という戦略が合理的だと思いました。 AI 導入においてドメイン知識不足は必ずぶつかる壁だと思いますが、それを逆手に取ってドキュメント文化の醸成に繋げた点は、組織改善の手法として参考になりました。
100% AI コード生成開発! AI Agent 時代の信頼性と開発効率のためのガードレール
- 株式会社リンクアンドモチベーション
- 川津 雄介
セッション概要
新規プロダクト開発において「100% AI コード生成」を目標に掲げ、Claude Code や Devin を活用した取り組みについての発表でした。
AI Agent は爆速で開発を進めるポテンシャルを持つ一方で、細かいミスや仕様の認識齟齬(期待値調整の失敗)により、手戻りが多く発生するという課題が挙げられていました。
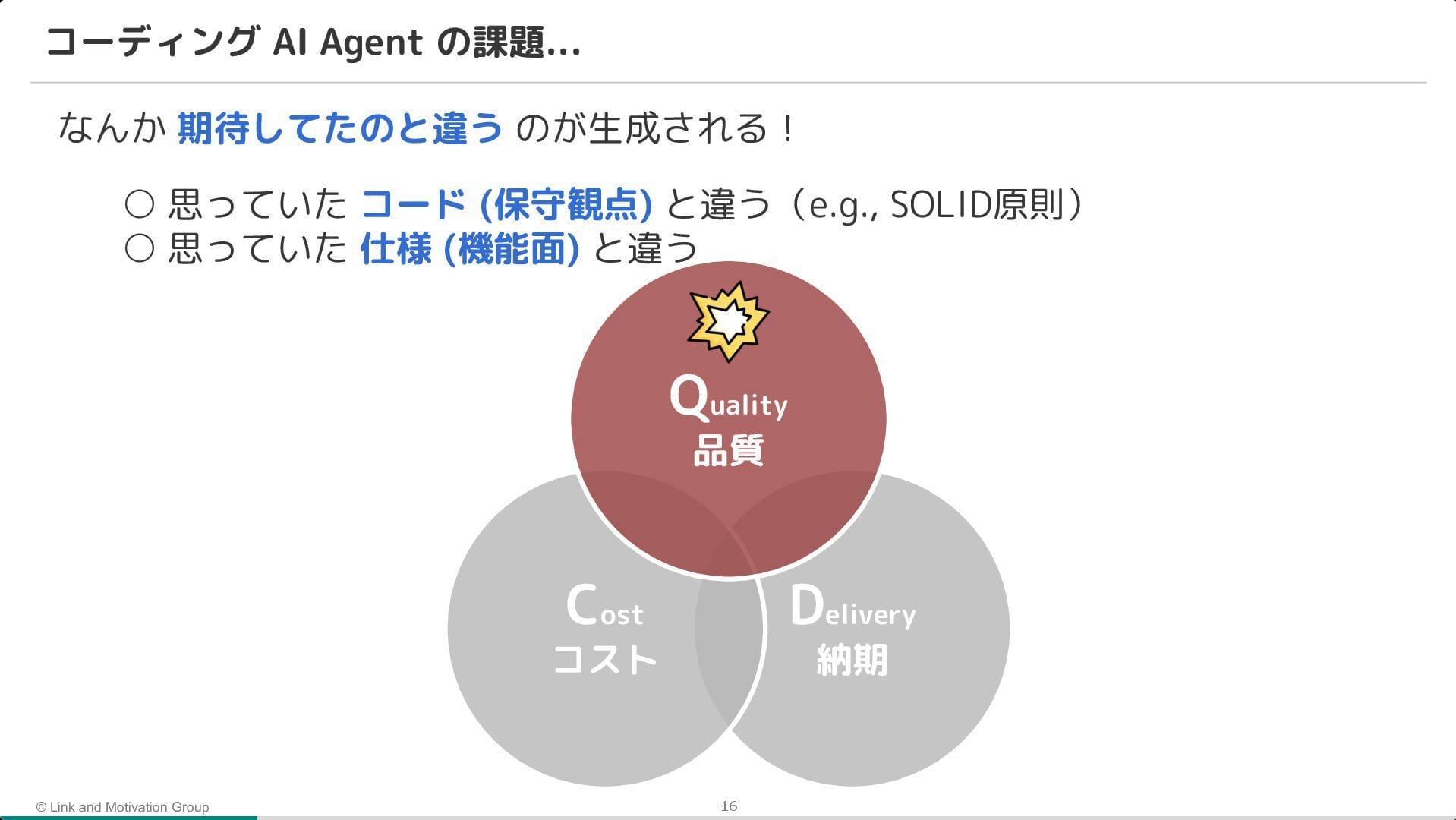
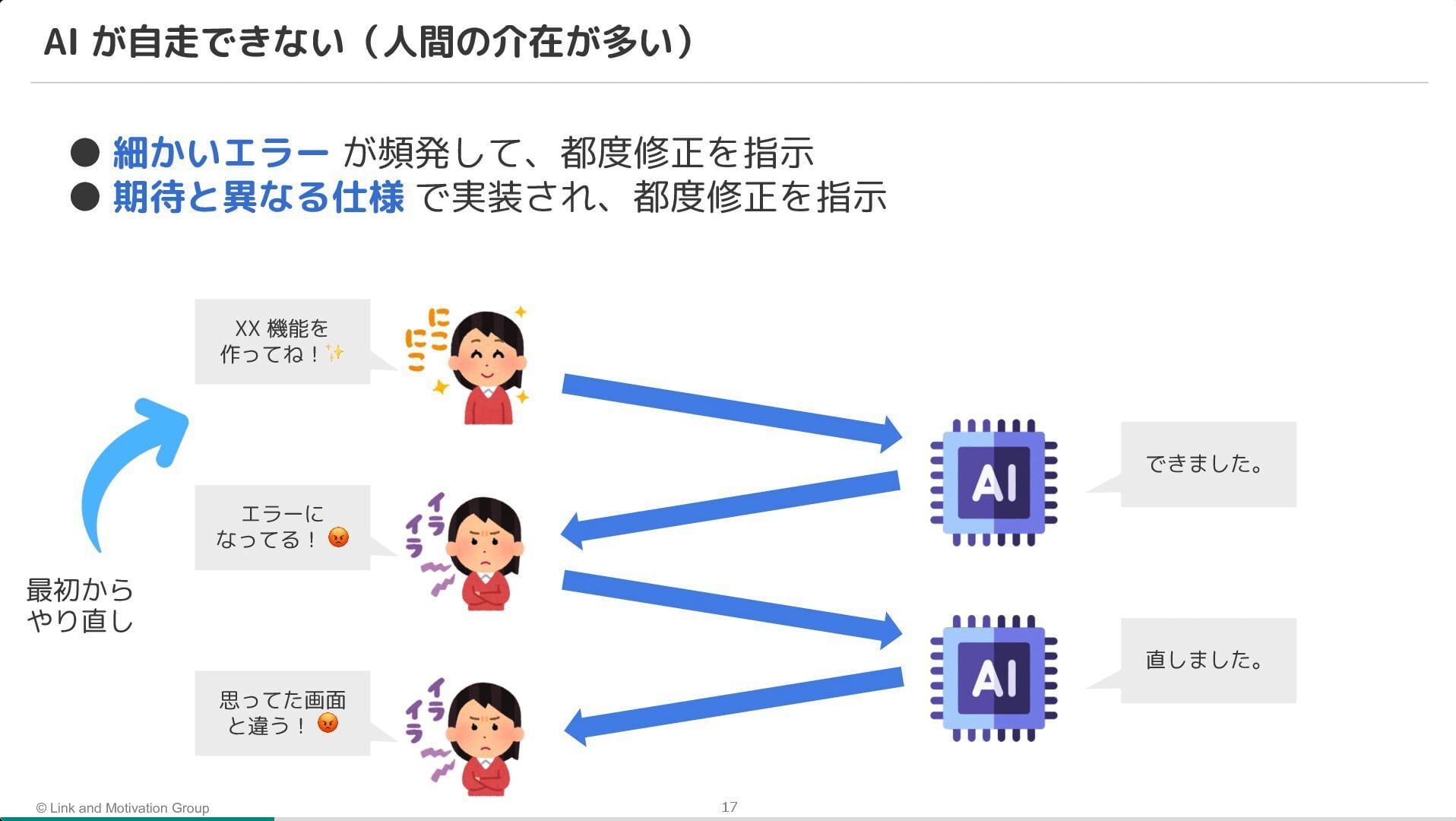
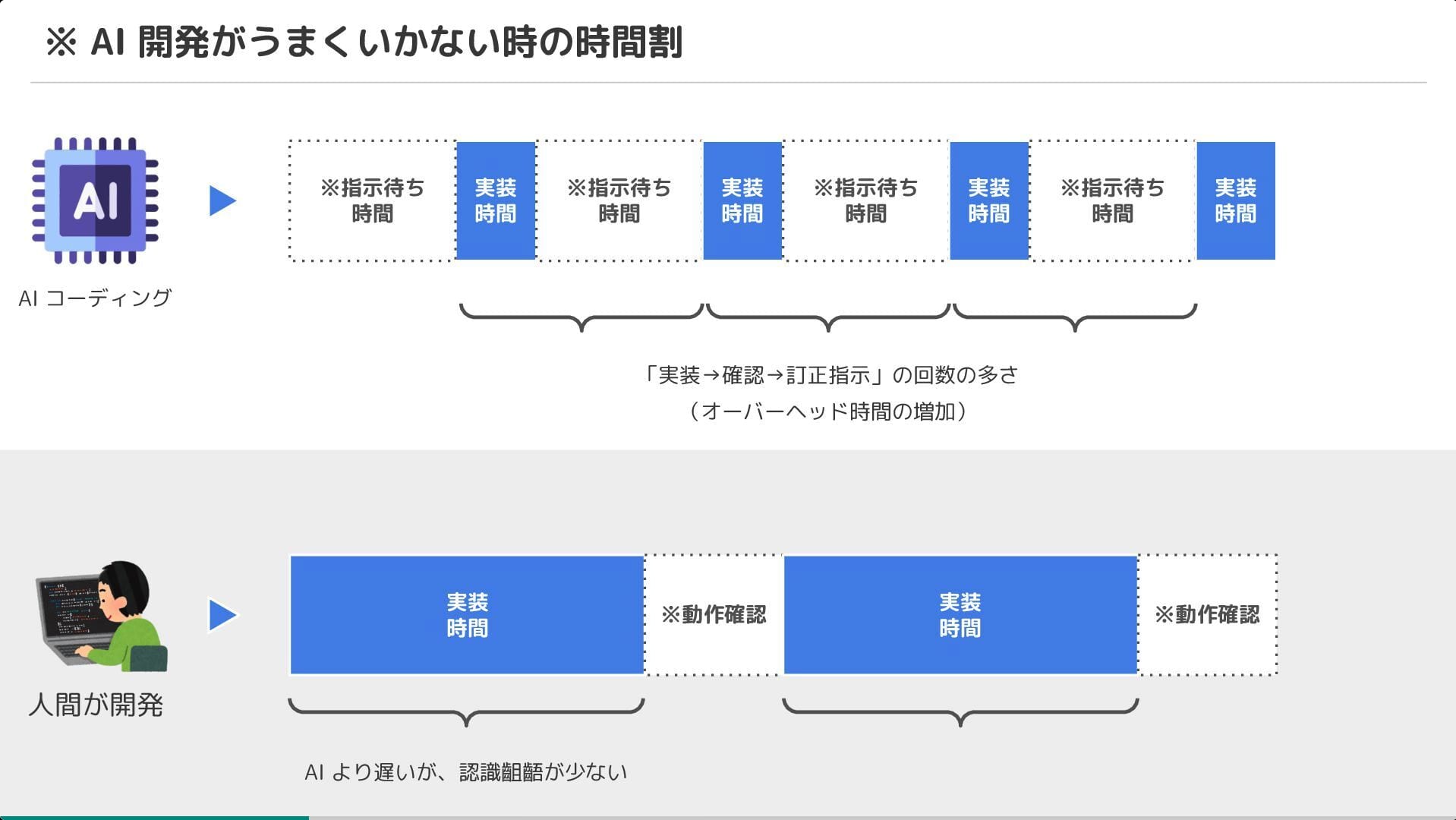
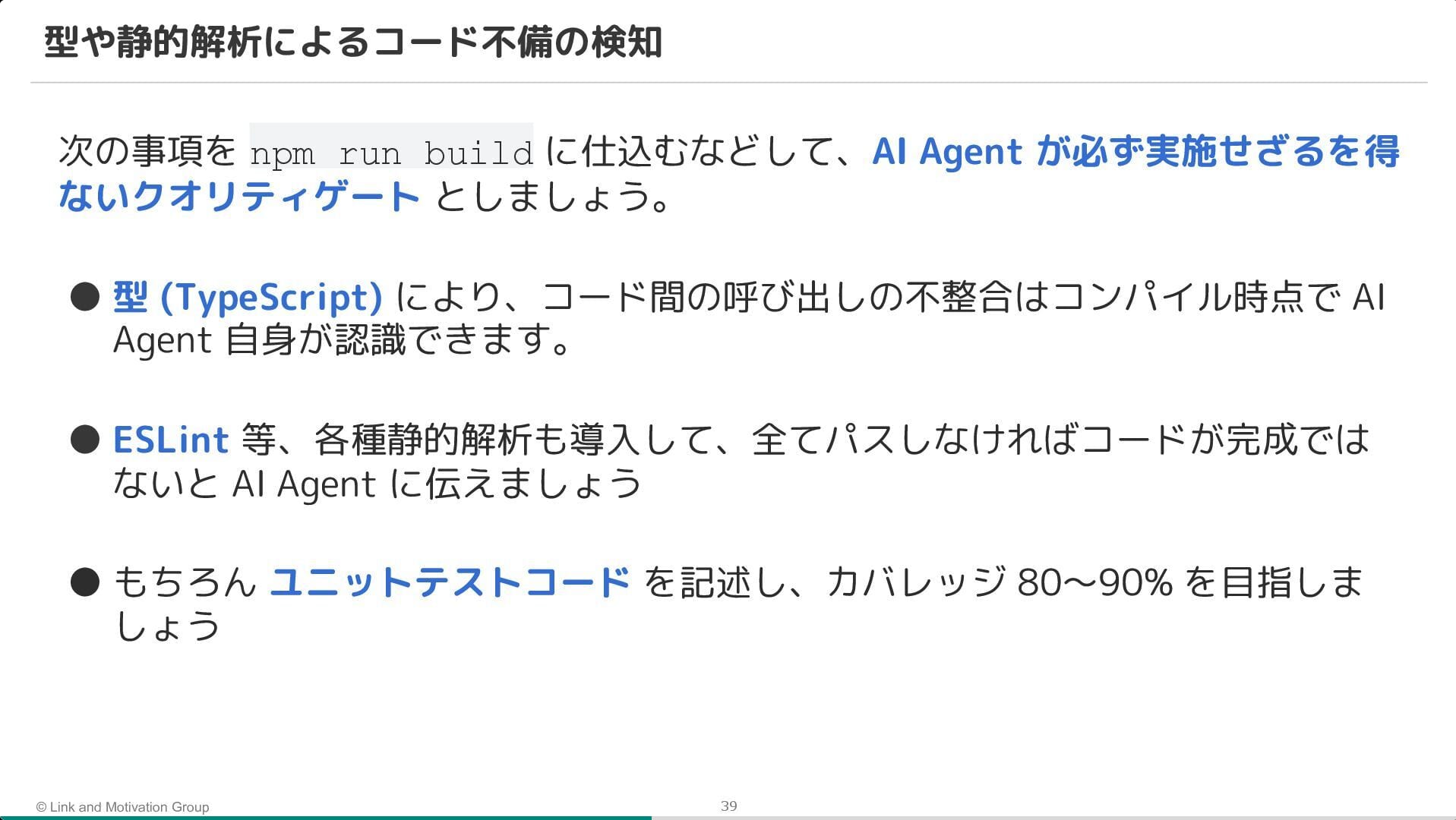
そこで、AI Agent を活用しつつ、AI が自律的にミスに気づける環境(ガードレール)を整備。 具体的には、TypeScript や ESLint による静的解析に加え、モノレポと tRPC を採用することで、API の仕様不整合をコンパイルエラーとして検知できる仕組みが紹介されました。
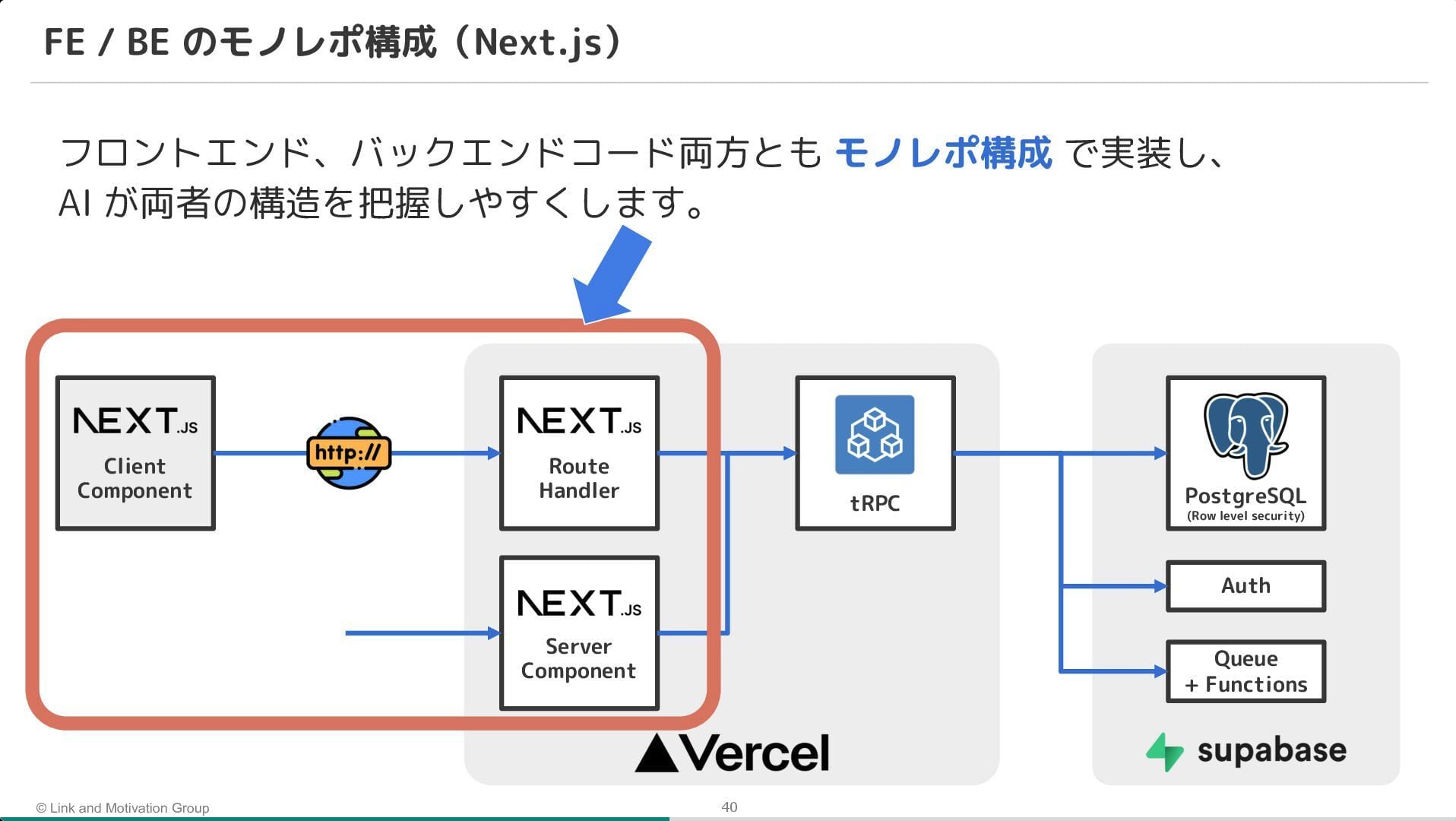
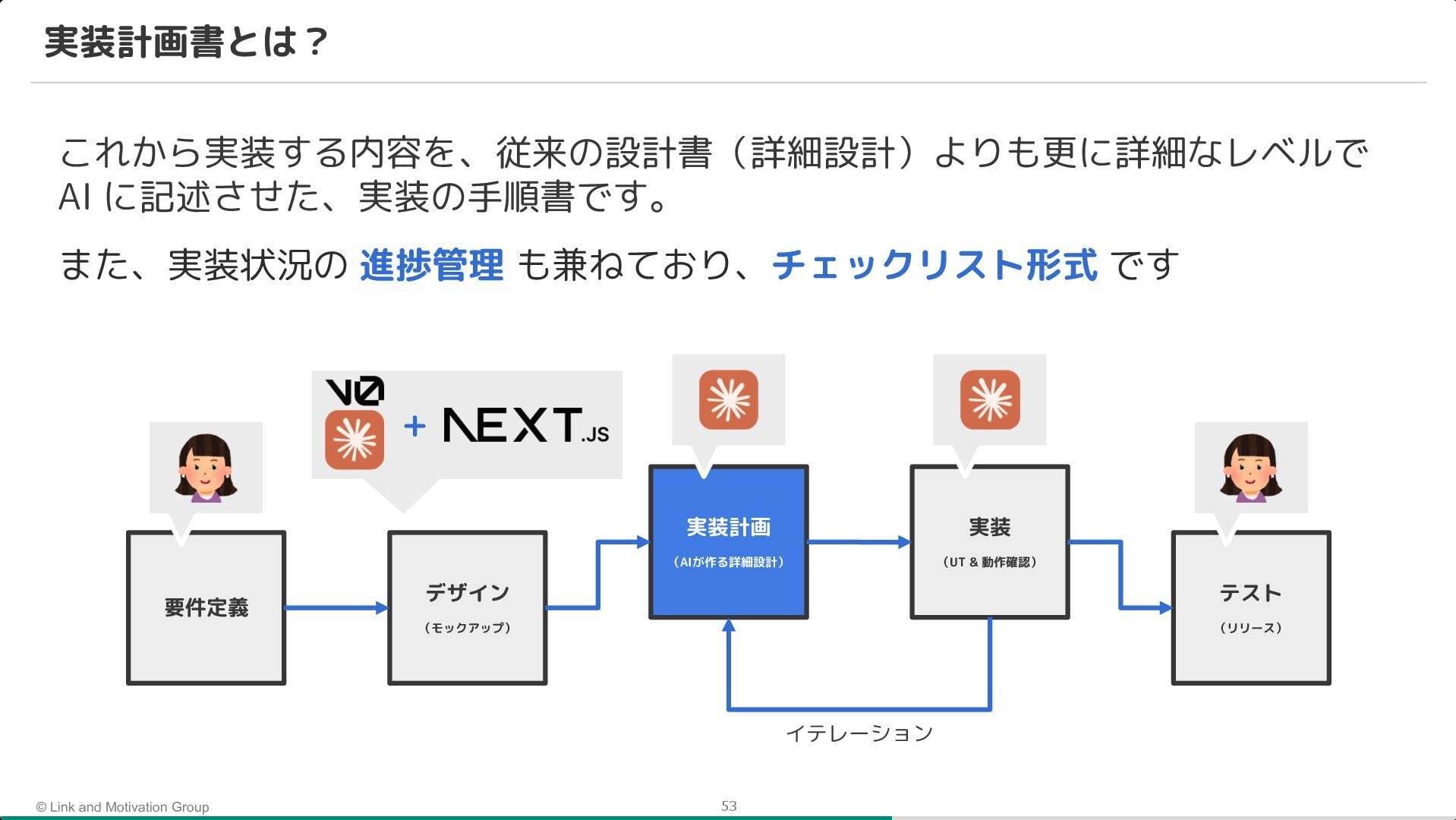
また、プロセス面では実装計画書の導入が鍵になったことが強調されていました。 いきなりコードを書かせるのではなく、まず計画書を AI に作成させ、人間がそれをレビュー・承認してから実装に進むことで、手戻りを防ぐフローを確立しているとのことです。
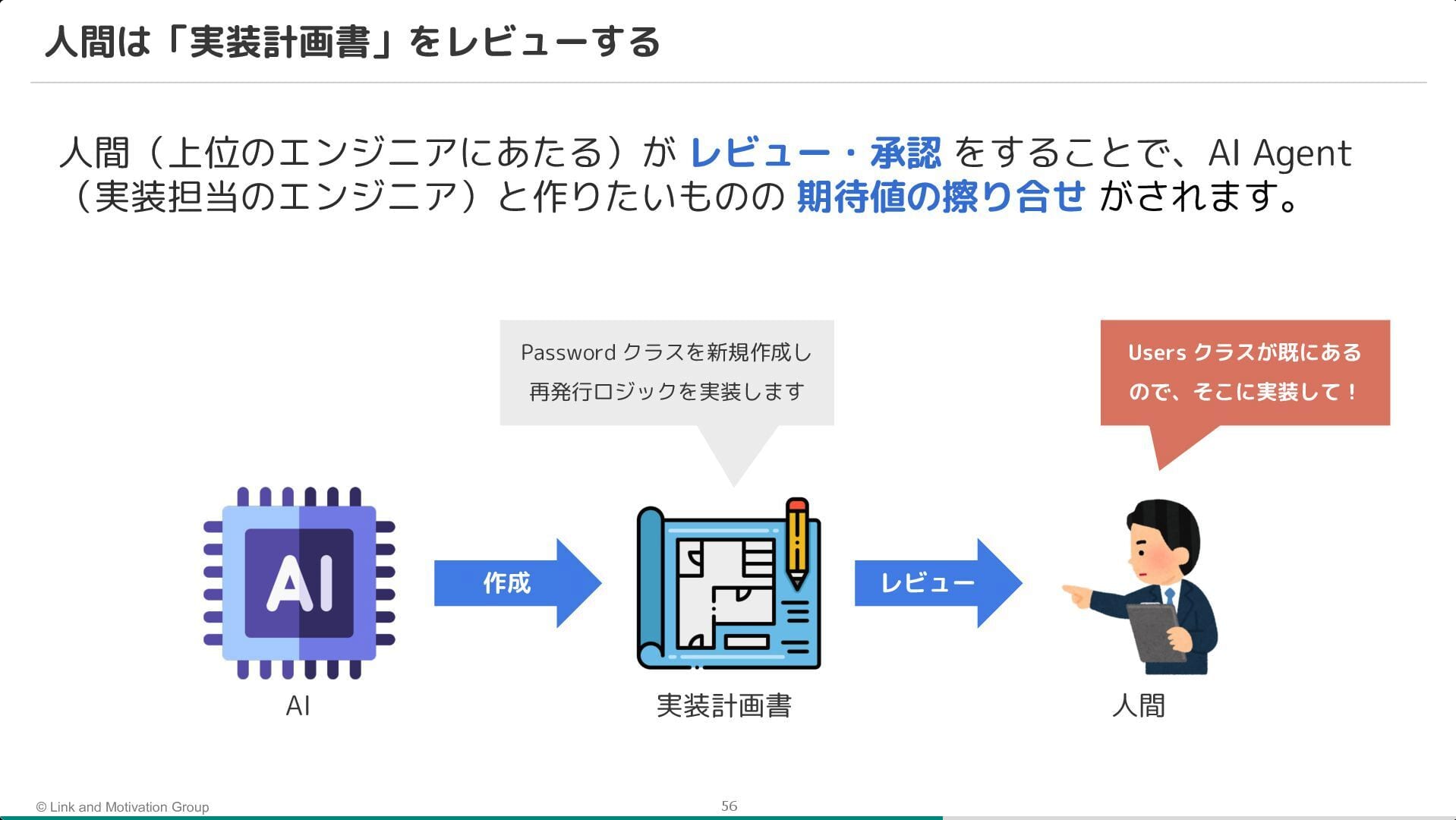
所感
AI にうまく指示を出す(プロンプトエンジニアリング)ことよりも、AI が自律的に試行錯誤できる環境(ガードレール)を整えることの方が重要である、という気づきがありました。
タイプセーフティな技術選定(tRPC 等)や静的解析を単なる品質担保の手段として採用するだけでなく、AI への高速なフィードバックループとして再定義する視点は、SRE 的なアプローチの進化系だなと思いました。 これからの Platform Engineering には、人間だけでなく AI Agent を積極的に活用し、AI 自体が安全かつ効率的に機能するアーキテクチャを設計することが要求されると感じました。
〜『世界中の家族のこころのインフラ』を目指して”次の 10 年”へ〜 SRE が導いたグローバルサービスの信頼性向上戦略とその舞台裏
- 株式会社 MIXI
- 杉本 浩平
セッション概要
「家族アルバム みてね」の 10 周年を機に、海外ユーザ増加に伴うレイテンシ問題への対策と、AWS マルチリージョン構成への移行プロセスに関するセッションでした。
「家族アルバム みてね」の登場初期は東京リージョン(ap-northeast-1)単独で運用していましたが、北米・欧州からのアクセス遅延が課題となり、SRE チーム発足後に CloudFront や S3 Transfer Acceleration といったソリューションの導入で改善を図ってきた経緯があります。



2022 年以降はさらなる体験向上のため、マルチリージョン化されました。
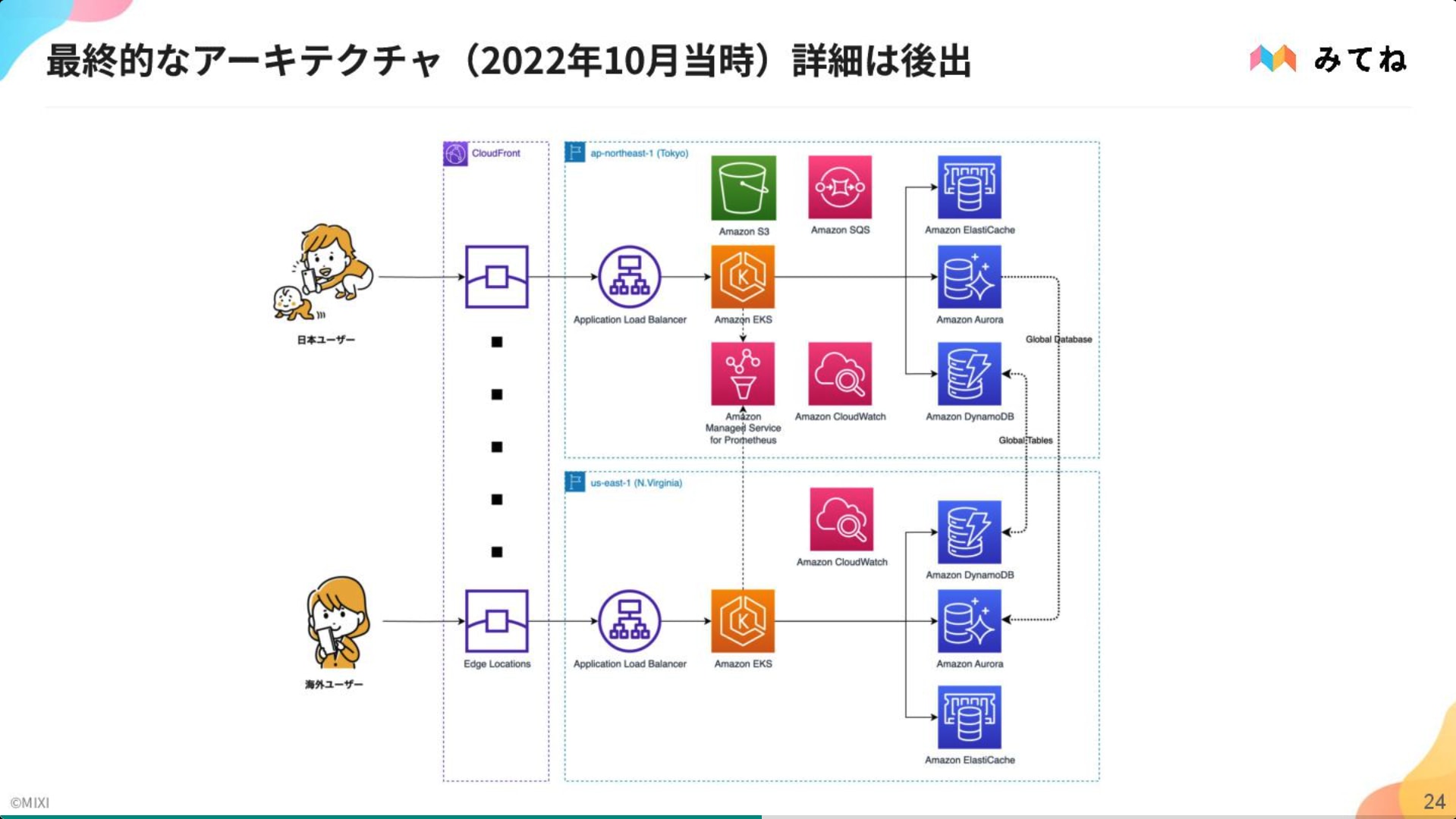
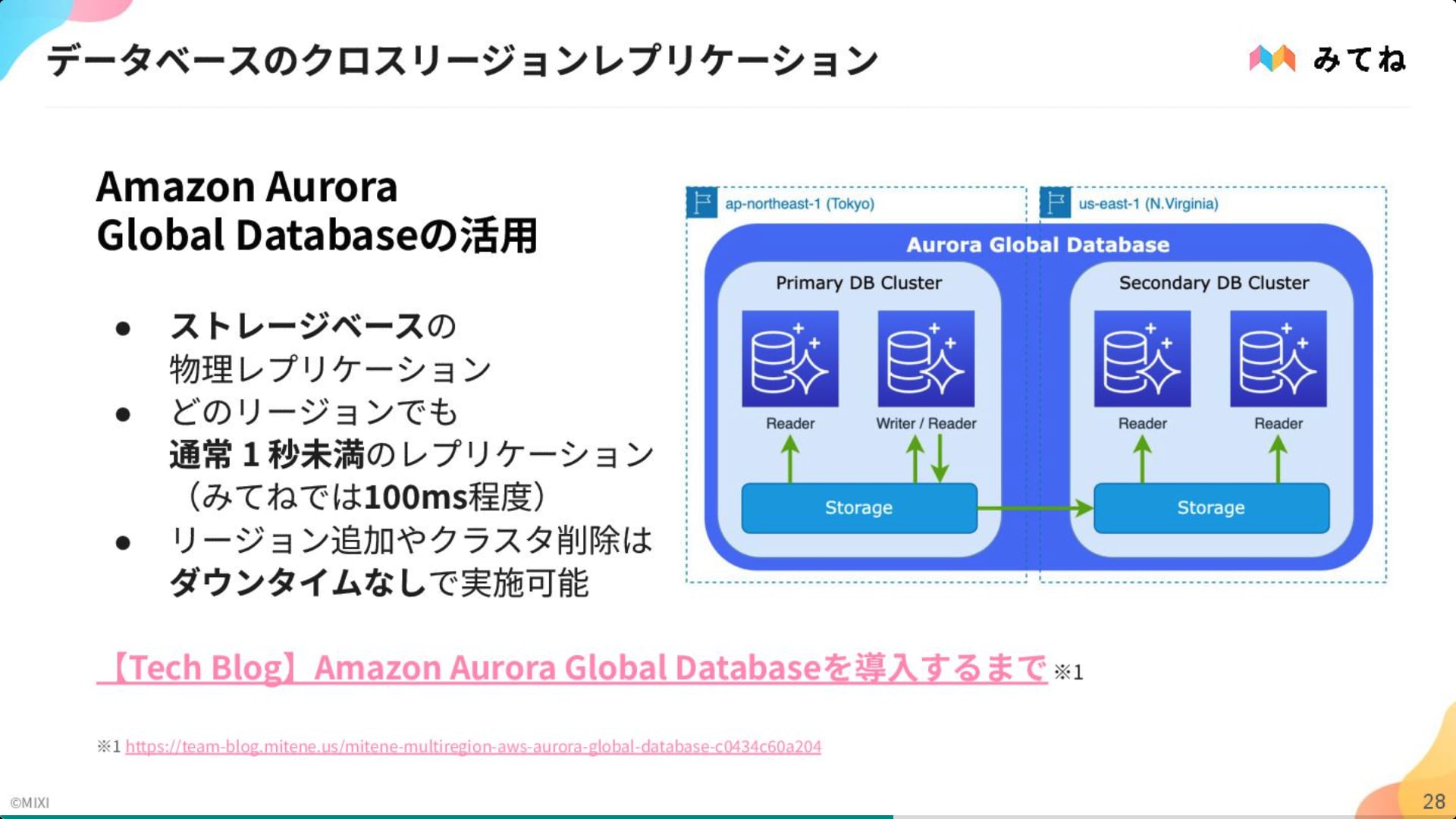
最も重要な閲覧体験にフォーカスし、セカンダリーリージョン(us-east-1)は読み取り専用(Read Replica)とする現実的な構成を選択。 技術的には、Aurora Global Database による低遅延同期や、Route53 / Lambda@Edge を組み合わせたルーティング制御を採用。

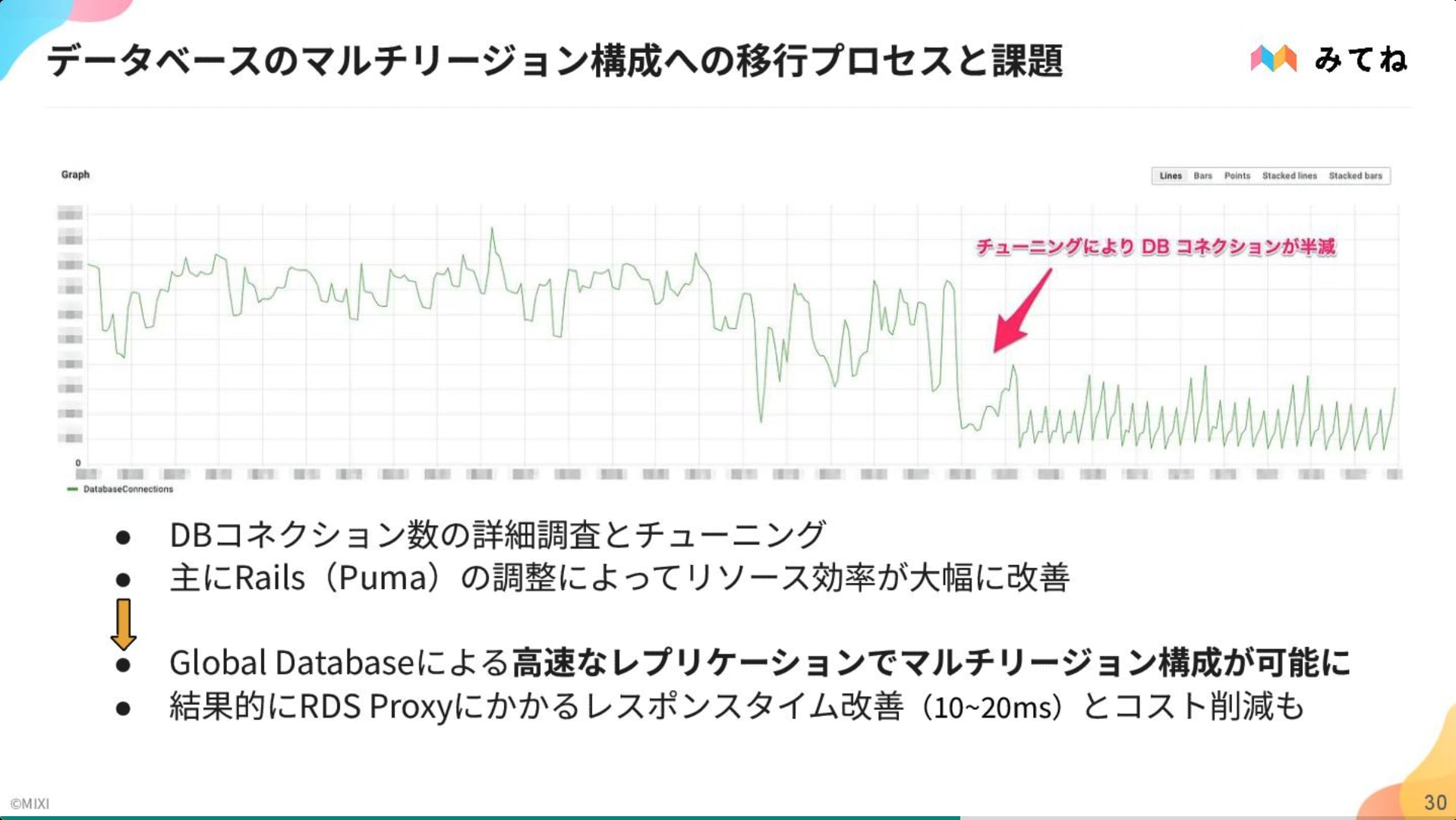
当時未対応だった RDS Proxy の代替策としてアプリケーション側のコネクション管理を最適化する等、泥臭い課題解決を積み重ねて実現に至ったプロセスについても紹介されていました。
所感
グローバルサービスにおいて、Route53 や Lambda@Edge といったソリューションを駆使したリージョンベースのルーティング制御や、Aurora Global Database を用いたデータ同期等、AWS のマネージドサービスを効果的に組み合わせたアーキテクチャ設計は非常に参考になりました。
RDS Proxy が未対応という制約に対してもインフラ側での解決に固執せず、アプリケーション側の改修で対処した点は現実的なアプローチだと感じました。 全てを一度に解決するのではなく、まずは特定のフィーチャ(閲覧体験)に絞るという現実的な技術判断も、大規模システムの移行戦略として参考になる点です。
Day 2 セッション
マルチプロダクト環境における SRE の役割 〜SmartHR の組織立ち上げから学ぶ実践知〜
- 株式会社 SmartHR
- 菅原 正宜
セッション概要
SmartHR では 10 数個のプロダクトが稼働しており、開発チームはフロントからインフラまで完結する ストリームアラインドチーム(Stream Aligned Team) 体制を採用しています。


SRE 組織の立ち上げ当初は、信頼性向上の必要性は認識されつつも経験者不在等の諸課題があったが、外部専門家のコンサルティングを受けながら「プロダクト成長への貢献」「信頼性の向上」「自律性の確立」をミッションに掲げ、組織作りが進められました。

立ち上げの実践においては、以下のようなフレームワークを活用してチームの共通認識を形成しています。
インセプションデッキ:「我々は何者か」「なぜここにいるのか」を定義して期待値調整

信頼性の評価基準(E-E-A-T):Google の指標を参照してリアクティブからプロアクティブな状態へ
- E:Experience(経験)
- E:Expertise(専門性)
- A:Authoritativeness(権威性)
- T:Trustworthiness(信頼性)

Google Cloud Well-Architected Framework:5 つの柱を用いてロードマップを作成
- Operational excellence
- Security, privacy, and compliance
- Reliability
- Cost optimization
- Performance optimization

現在は少人数の SRE でレバレッジを効かせるため、各チームが自律的に動けるようなベストプラクティスの策定や共有に注力しており、今後は CI/CD 環境構築等の Platform Engineering 領域にも注力していくそうです。
所感
本セッションで紹介されていた E-E-A-T や Well-Architected Framework といった既存のフレームワークを効果的に活用して組織を定義し、リアクティブからプロアクティブな体制へと進化させたプロセスは、組織エンジニアリングの実践として参考になりました。 単に人手を増やすのではなく、共通認識の形成やベストプラクティスの共有を通じて少人数の SRE で組織全体にレバレッジを効かせるというアプローチは、リソース制約の中でスケーラビリティを確保するための合理的な戦略だと感じました。
ロールが細分化された組織で SRE は何をするか?
- KINTO テクノロジーズ株式会社
- 長内 則倫
セッション概要
KINTO テクノロジーズでは、SRE、Platform Engineering、DBRE、CCoE、Security、QA 等、専門組織が細分化されている環境において、「SRE ならではの価値」をどう定義し、発揮していくかがテーマでした。
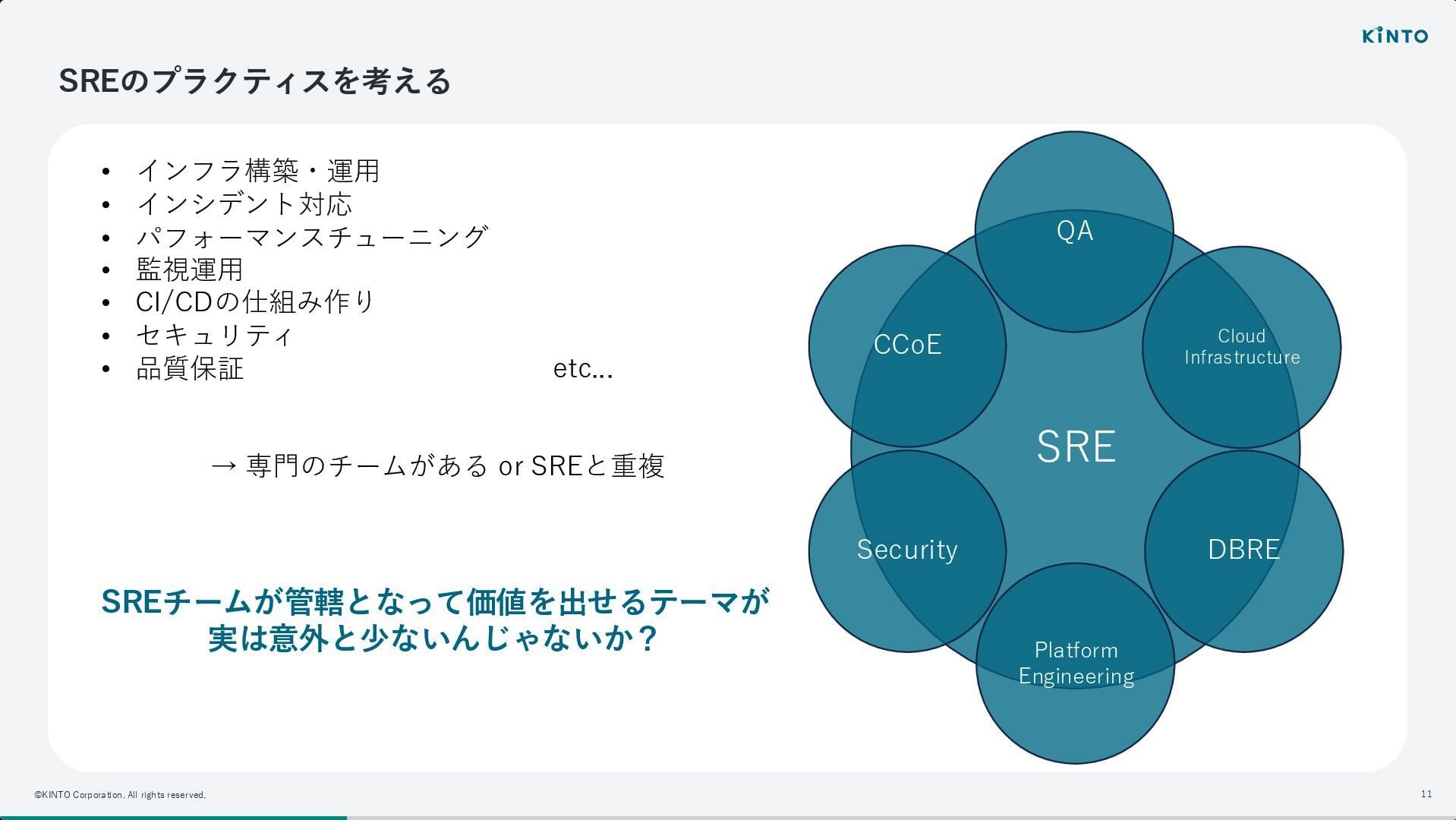
他部署と役割が重複しやすい中で、「自分たちは何をすべきか?」「SRE としての価値はどこにあるのか?」といった問いにチームとして向き合ってきたプロセスが紹介されました。
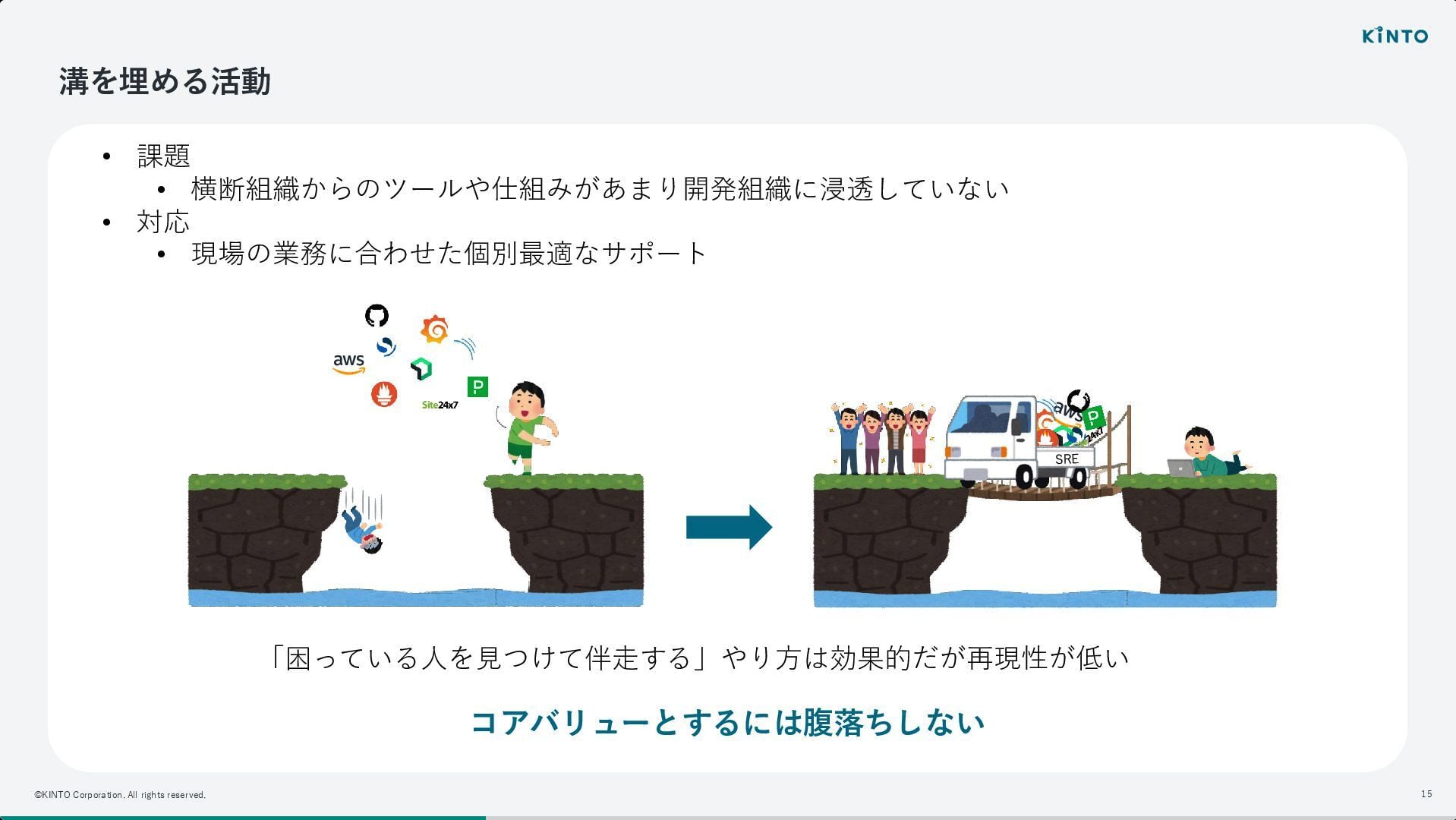
特に、SRE のプラクティスが多岐にわたるが故に、既存の専門組織と領域が重なるという大組織ならではの悩みに対し、境界線を引くのではなく、組織全体の信頼性向上という目的のために柔軟に役割を模索する姿勢が強調されていました。
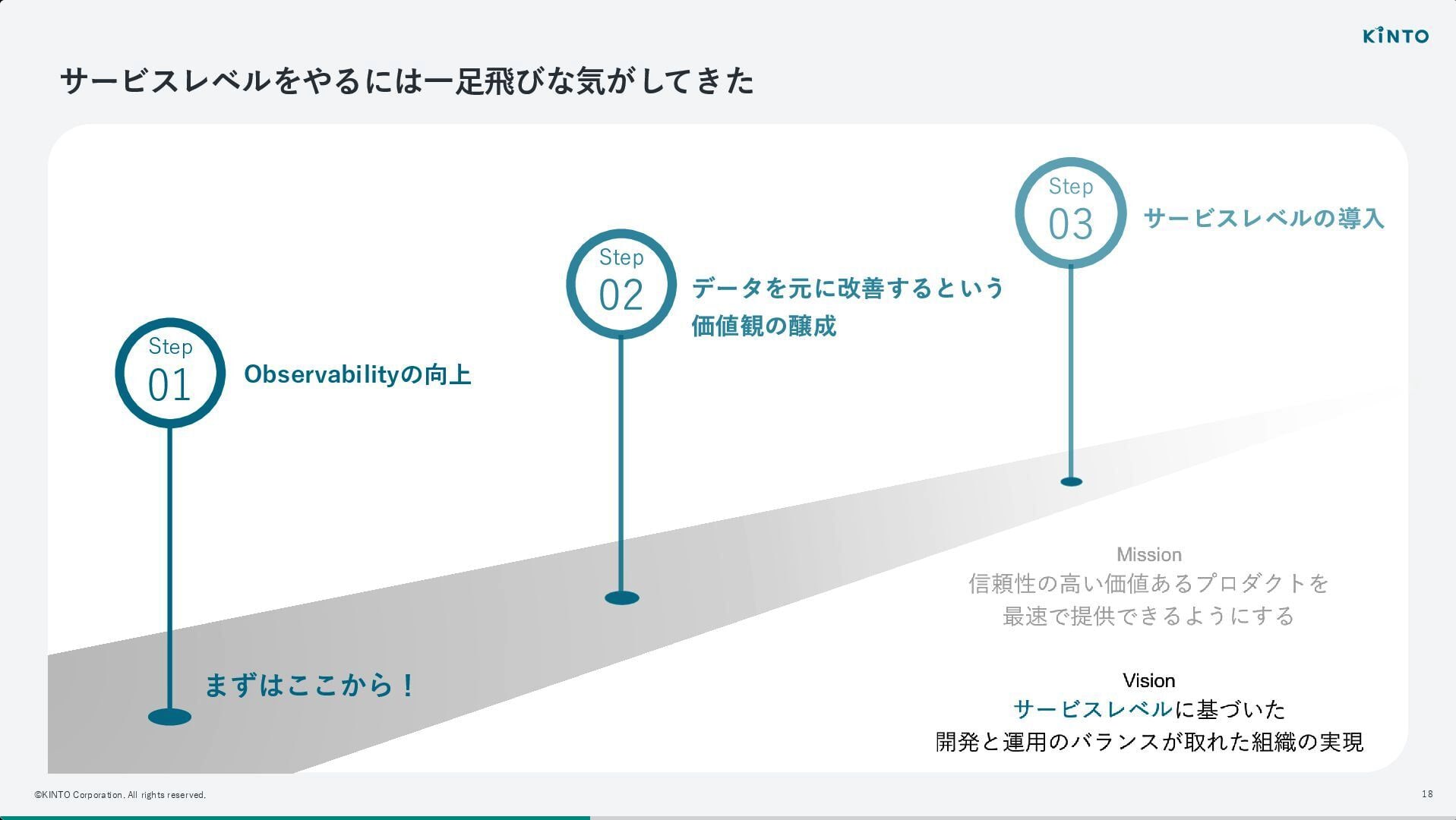
いきなりサービスレベル(SLO)の導入を目指すのではなく、まずは足元の可観測性(Observability)を向上させることから着手したとのことです。
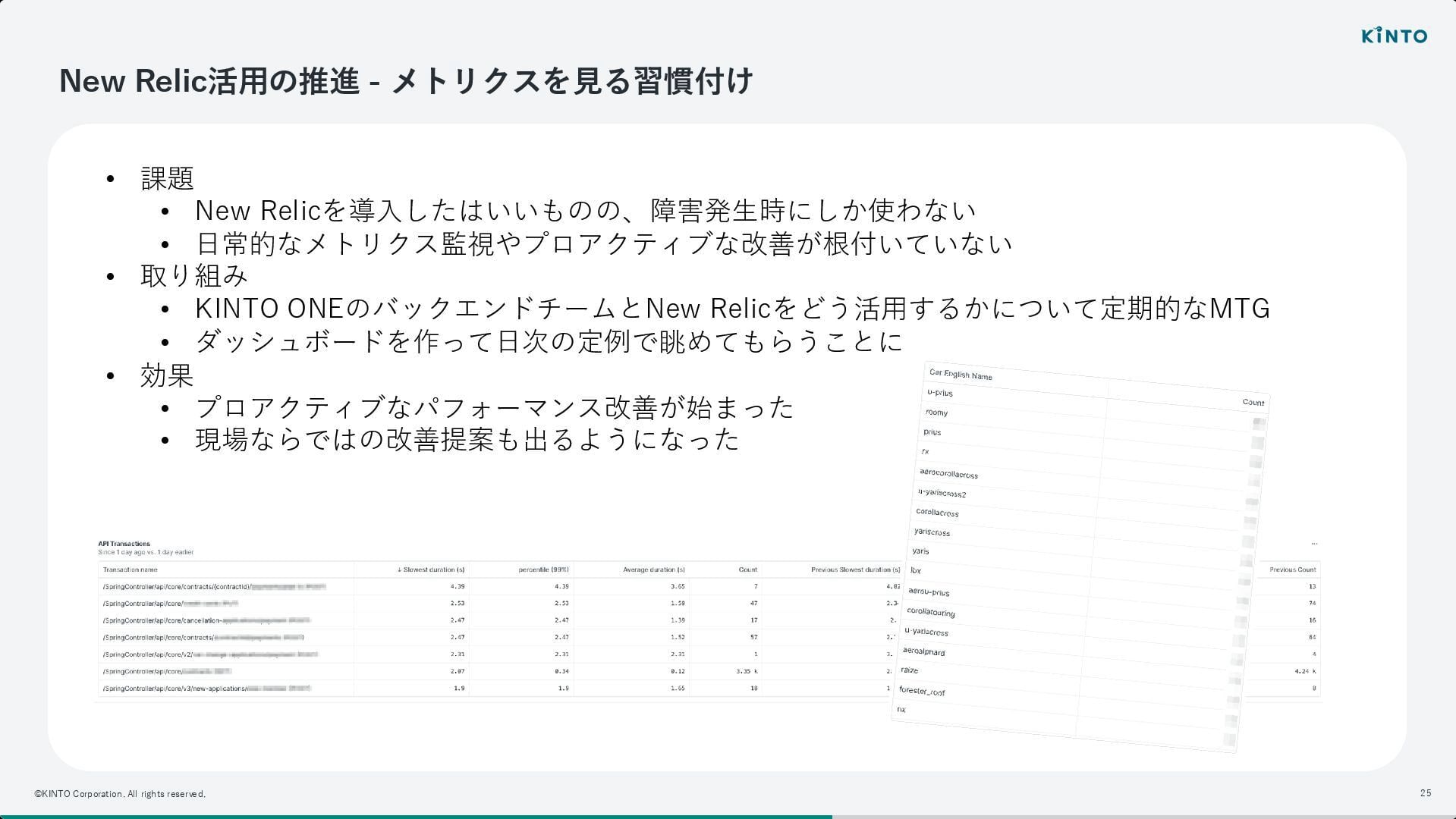
New Relic を導入したものの、当初は障害発生時にしか見ないという課題があったといいます。 そこで、日常的にメトリクスを確認し、プロアクティブな改善に繋げる習慣(モニタリング定例)を根付かせるための取り組みが進められました。
しかし、いざサービスレベルを導入しようとすると、「その目標値が妥当なのか分からない」という壁に直面したそうです。 EC サイトのようにレスポンスタイムが収益に直結するわけではなく、車のサブスクリプションという事業特性上、最適な指標を見つけるのが難しさについて話されていました。
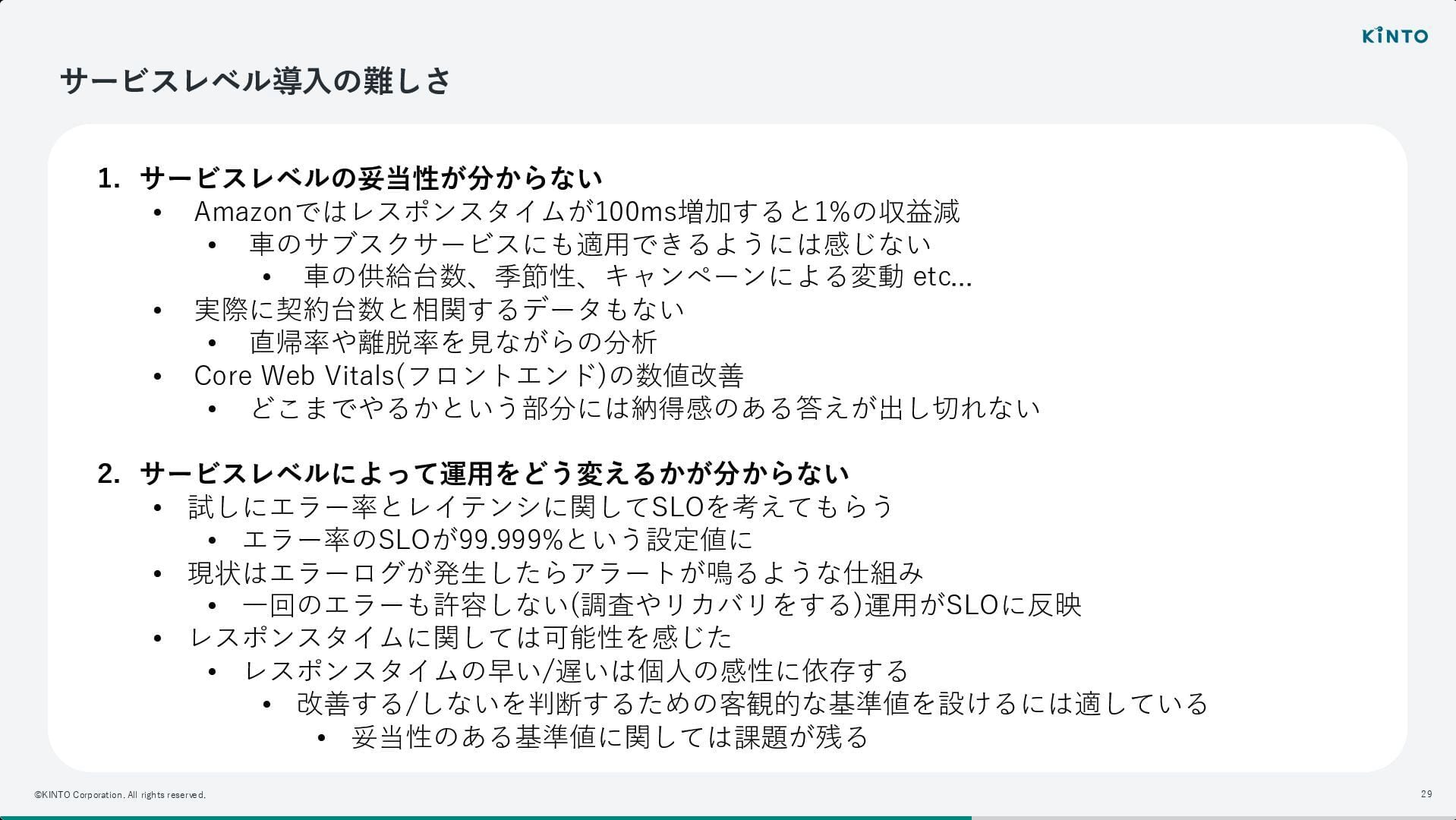
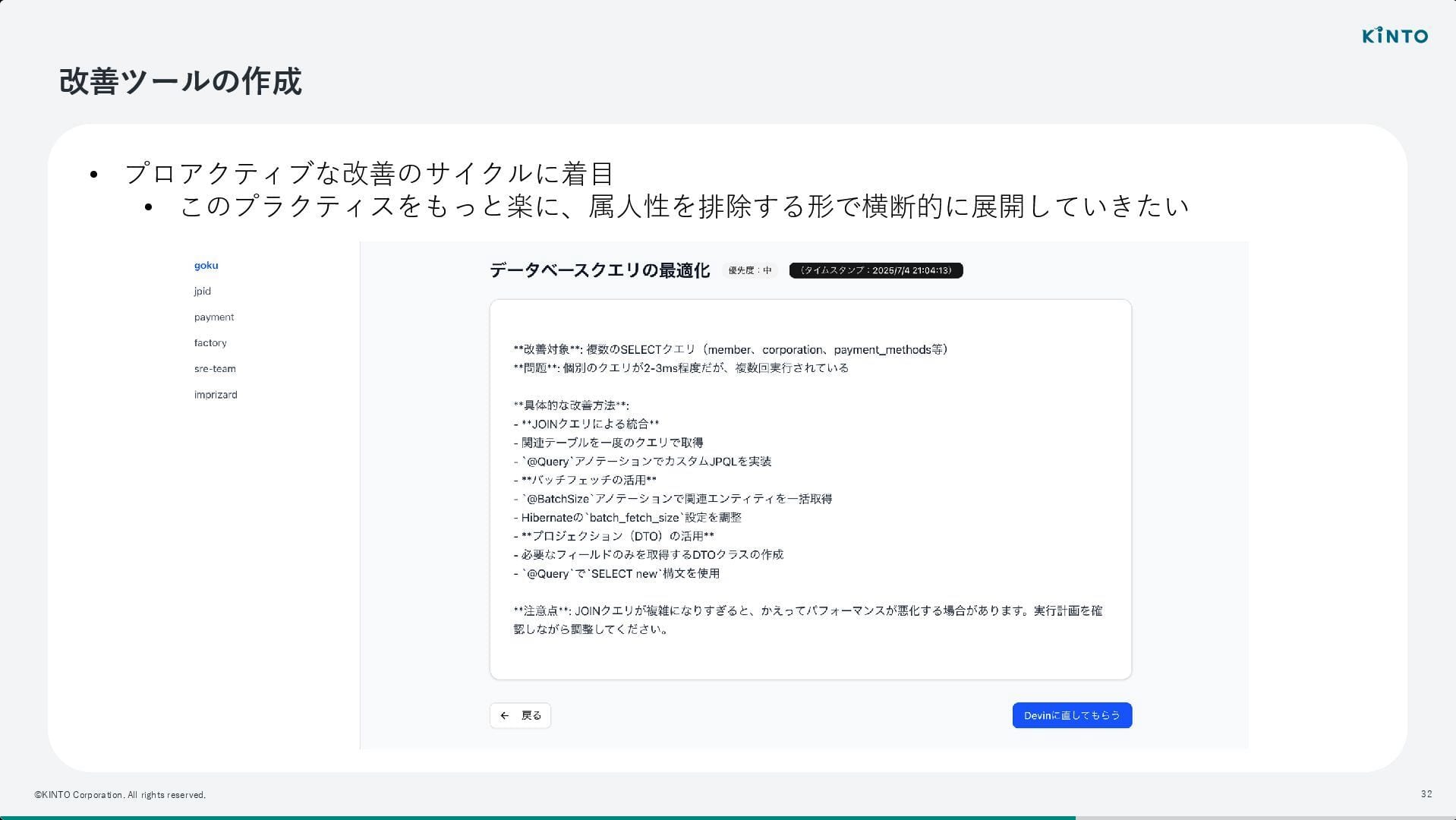
そこで、サービスレベルの厳密な定義に時間をかけるよりも、まずは「改善のサイクル」を回すことに注力し、属人性を排除しながら横断的に改善を促すためのツール作成へと舵を切ったとのことです。
現在も一定のサービスレベルを自然と満たせるような仕組みを模索中とのことです。
所感
専門組織が細分化された大組織ならではの「SRE の価値定義」という難題に対し、率直な悩みと試行錯誤のプロセスが語られ、どこも似たような課題に悩まされているなと、自分としては非常に共感する部分が多くありました。 「SRE とはこうあるべき」という定義に縛られすぎず、組織のフェーズや構成に合わせて柔軟に価値を提供していくことこそが、SRE の本質的な役割なのかもしれないと考えさせられました。
150 サービス連携を 3 人で運用する現場から ー 創業 4 ヶ月目におけるオブザーバビリティの実践
- Dress Code 株式会社
- 蒲生 廣人
セッション概要
「IT Force」という情シス向けプロダクトにおいて、3 人のエンジニアで 150 以上の SaaS 連携を運用するためのオブザーバビリティ実践事例の紹介でした。 本プロダクトでは外部サービス連携がビジネスの肝とのことですが、API の仕様変更や認証切れ、ユーザ操作ミスといった失敗の原因は多岐にわたります。
従来のログやトレースだけでは「何が、どこで、なぜ」起きたのかを把握しきれないという課題に対し、Datadog や Redash を活用して「どのアプリで、どのような連携が、なぜ失敗したのか」を詳細に可視化する環境を構築されたとのことです。



これにより、少人数チームでも迅速に原因を特定し、運用負荷を抑えながら高い信頼性を維持している事例が紹介されました。
所感
外部連携が多いシステムでは、障害時の原因切り分けに多くの工数を要すると思います。 セッションで紹介された事例のように、オブザーバビリティの目的を「調査コストの削減」に定め、ビジネスロジックレベルでの失敗理由まで可視化することで、少人数でも運用可能な状態を維持するアプローチは、リソース制約のある環境において非常に合理的だと感じました。
大量配信システムにおける SLO の実践 :「見えない」信頼性を SLO で可視化
- 株式会社プレイド
- 土谷 優五
セッション概要
CX プラットフォーム「KARTE Message」における大量配信(月間数億通)の信頼性を担保するための SLO 実践事例についての紹介でした。 サービスの健全性を測る上で、単一の指標では実態を捉えきれないため、信頼性の「解像度」を上げるアプローチが取られています。

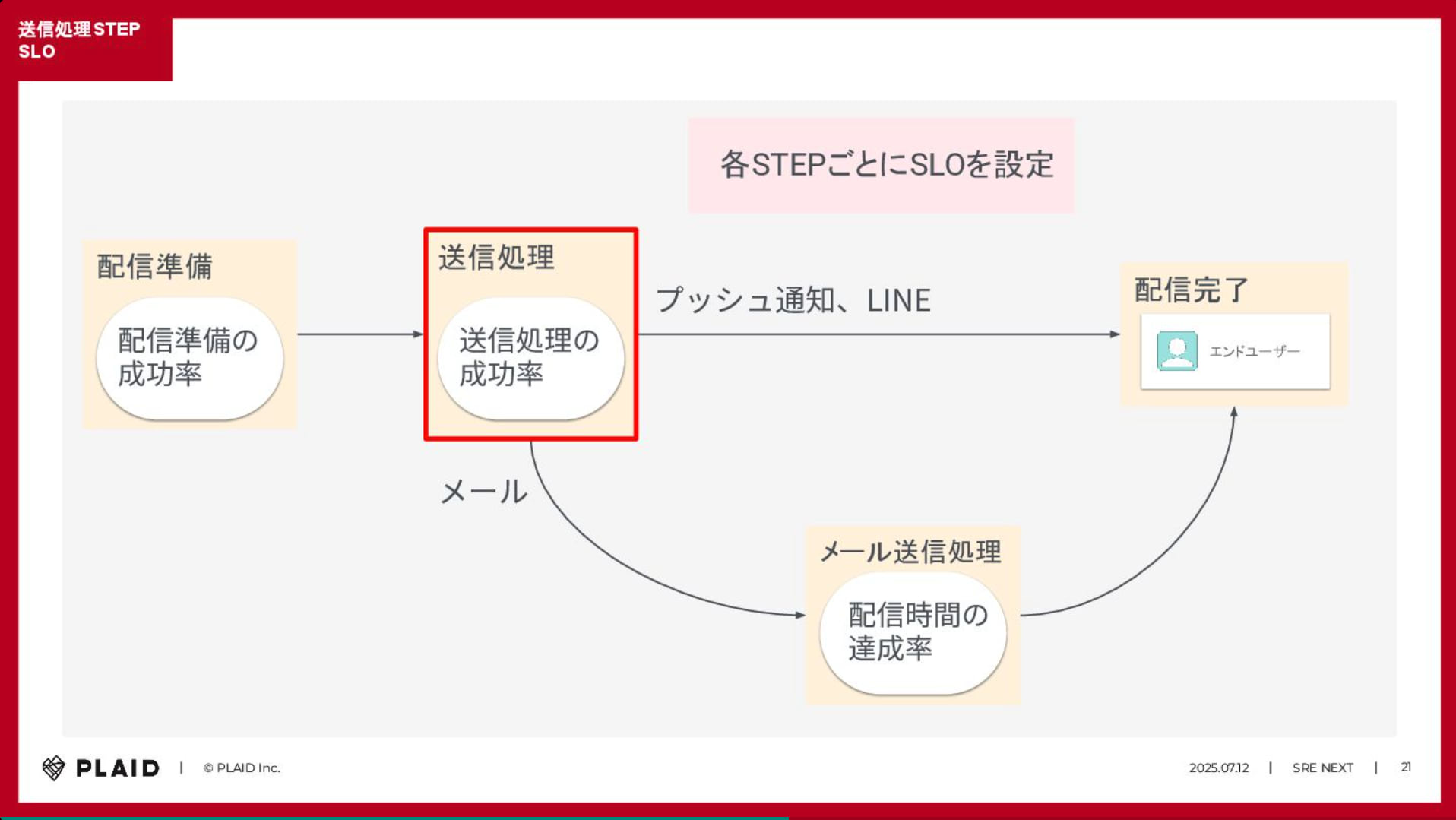
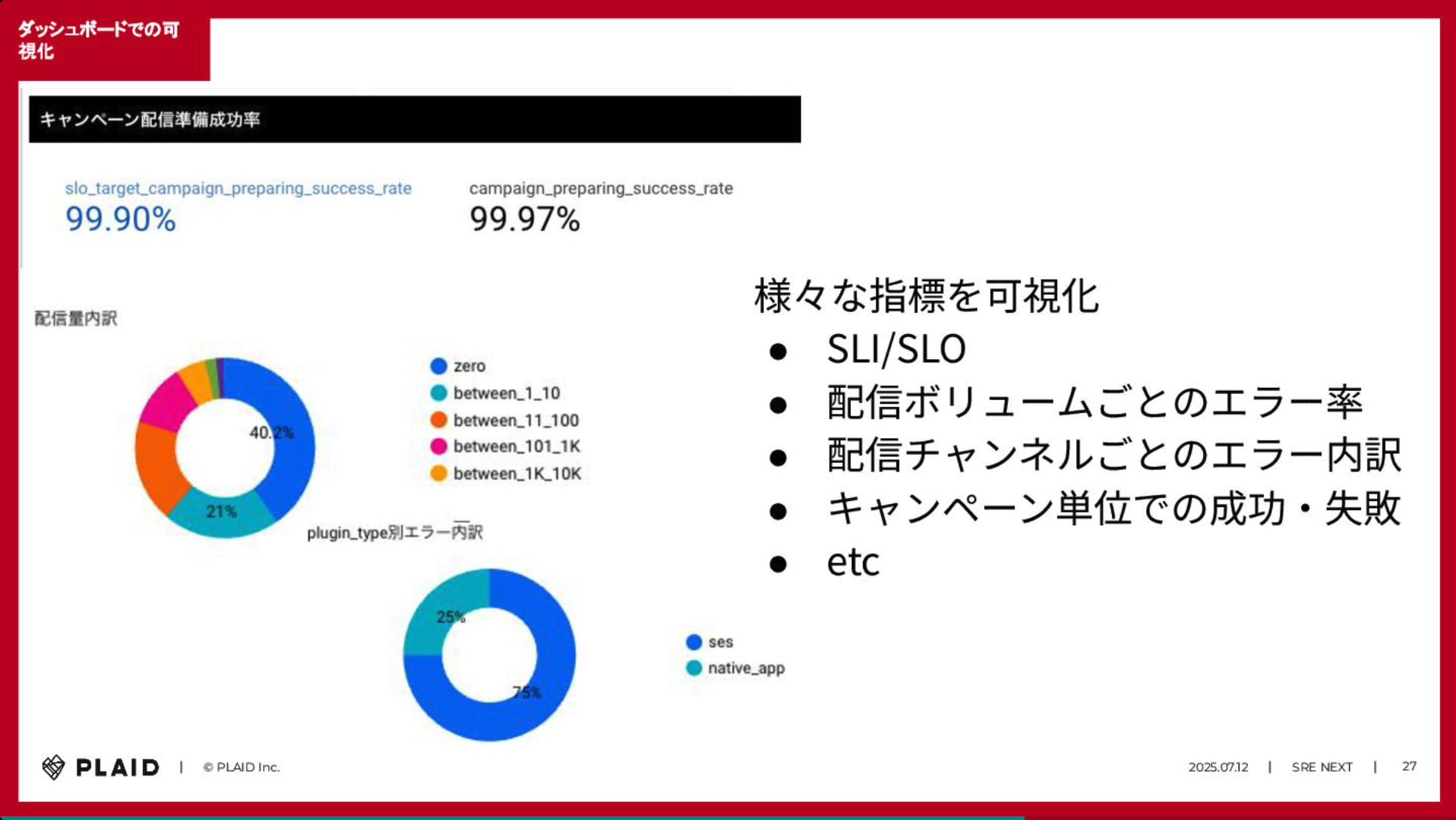
具体的には「配信成功」だけでなく「配信にかかった時間」や最終的なエンドユーザへの「到達」といった、異なる複数の側面からサービスレベル指標(SLI)を定義し、それらを運用改善のサイクルに組み込んでいるとのことです。
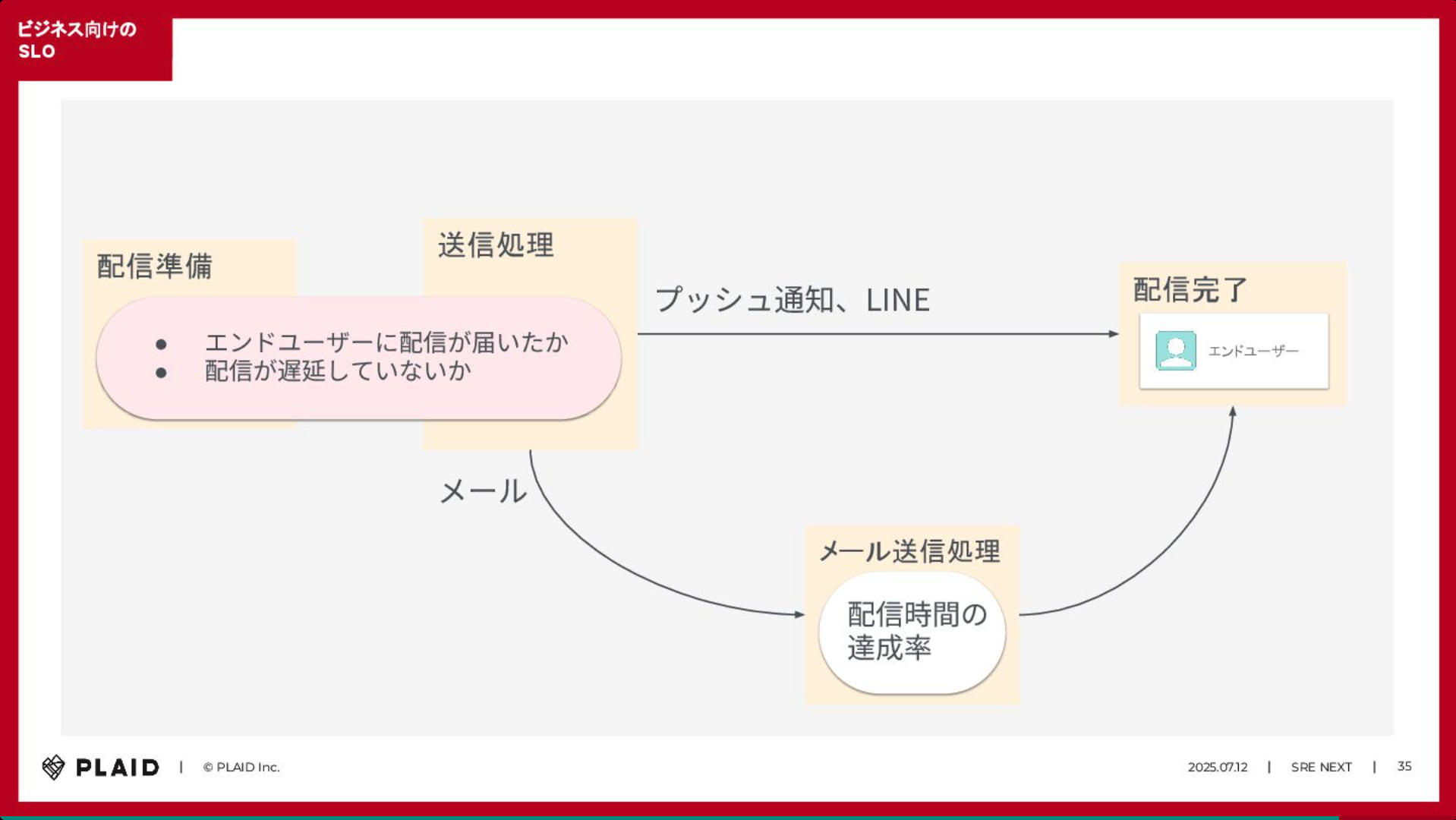
運用を開始した後に見えてくる課題に対しても、継続的に SLO や運用プロセスを見直し、改善を繰り返している知見が共有されました。
所感
メール配信という一見シンプルな機能に対し、ユーザ体験の質を担保するためにここまで多角的な SLI を定義しているのは凄いなと思いました。 単にシステムが動いているかどうかだけでなく、ユーザに価値が届いているかを定量的に指標化し、それを運用改善のサイクルに組み込む姿勢は、SLO 本来の目的を体現した好例として参考になりました。
Kubernetes で管理する大規模 Edge クラスタ: 200 台の EV チャージャーの安定稼働を支える技術
- 株式会社パワーエックス
- 米倉 遼太
セッション概要
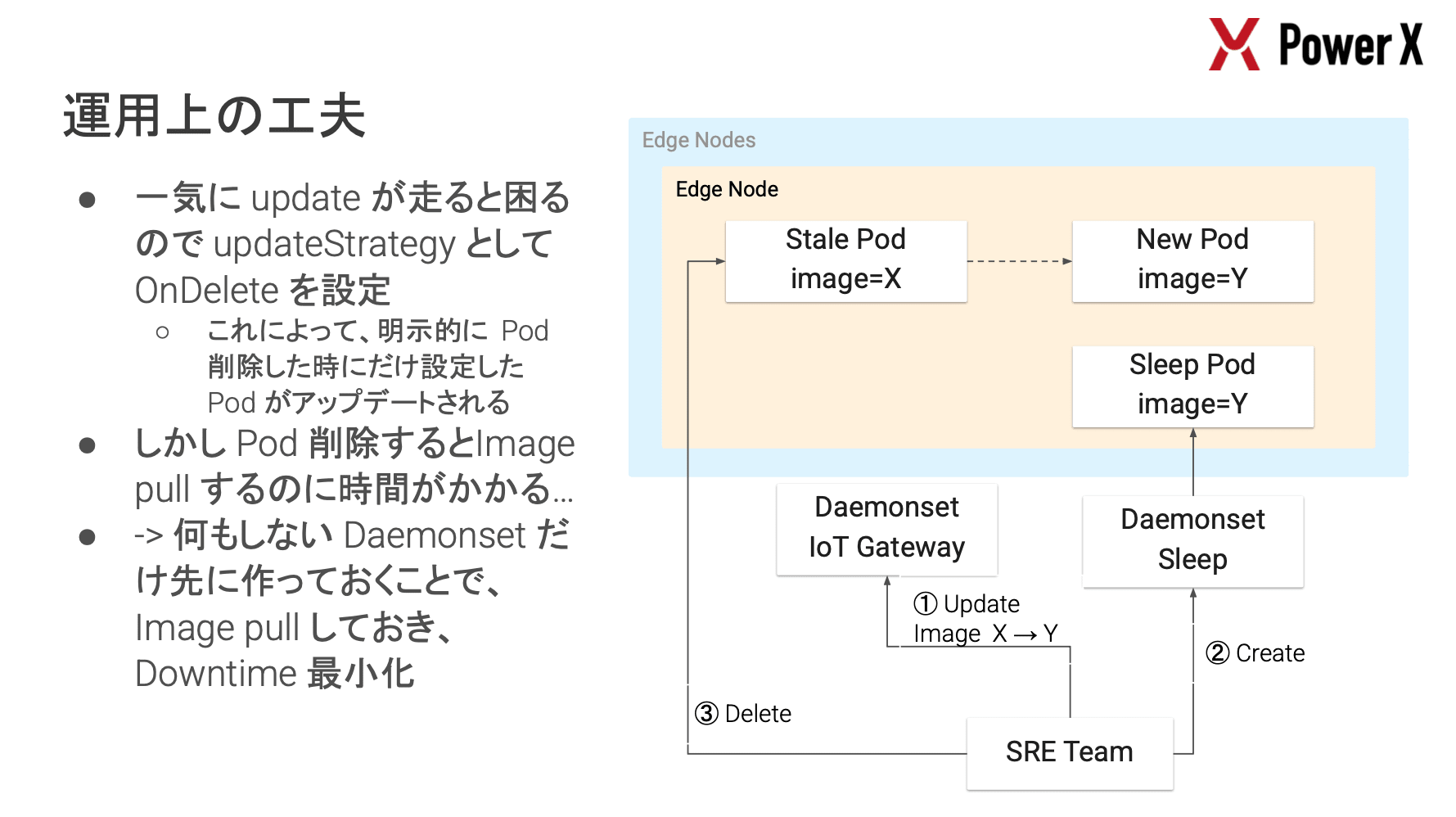
PowerX では、EV チャージャーや大型蓄電池(BESS)等、200 台を超えるエッジデバイスの安定稼働が最重要課題となっており、その解決策として k0s を採用した事例が紹介されました。

デバイスにはリソース制約が非常に厳しい旧型(ARMv7, メモリ 500MB)と新型が混在しており、これらを統一的に管理するために軽量な k0s を選定し、GKE のコントロールプレーンと VPN で接続したハイブリッドクラスタを構築しているとのことです。
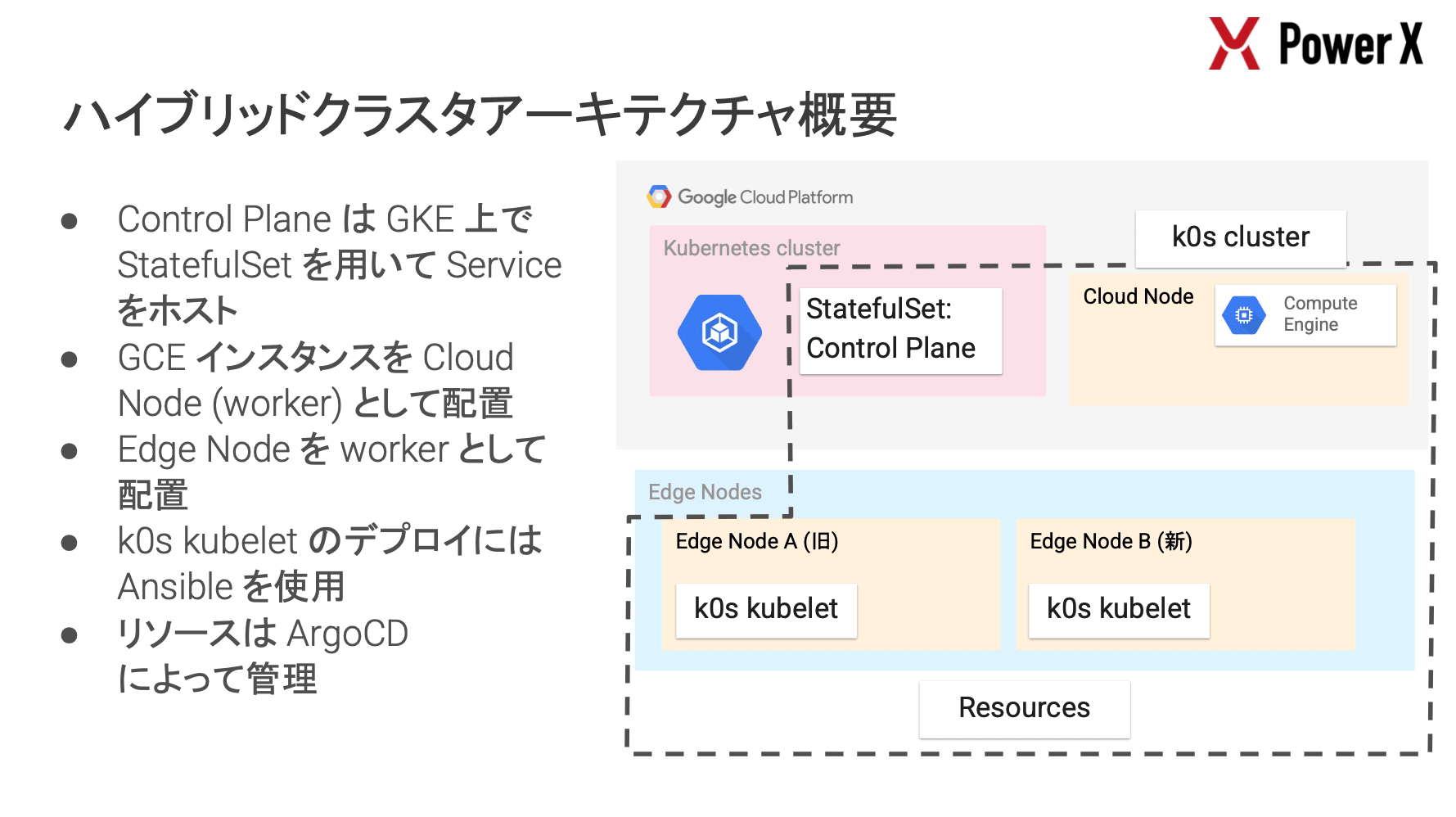
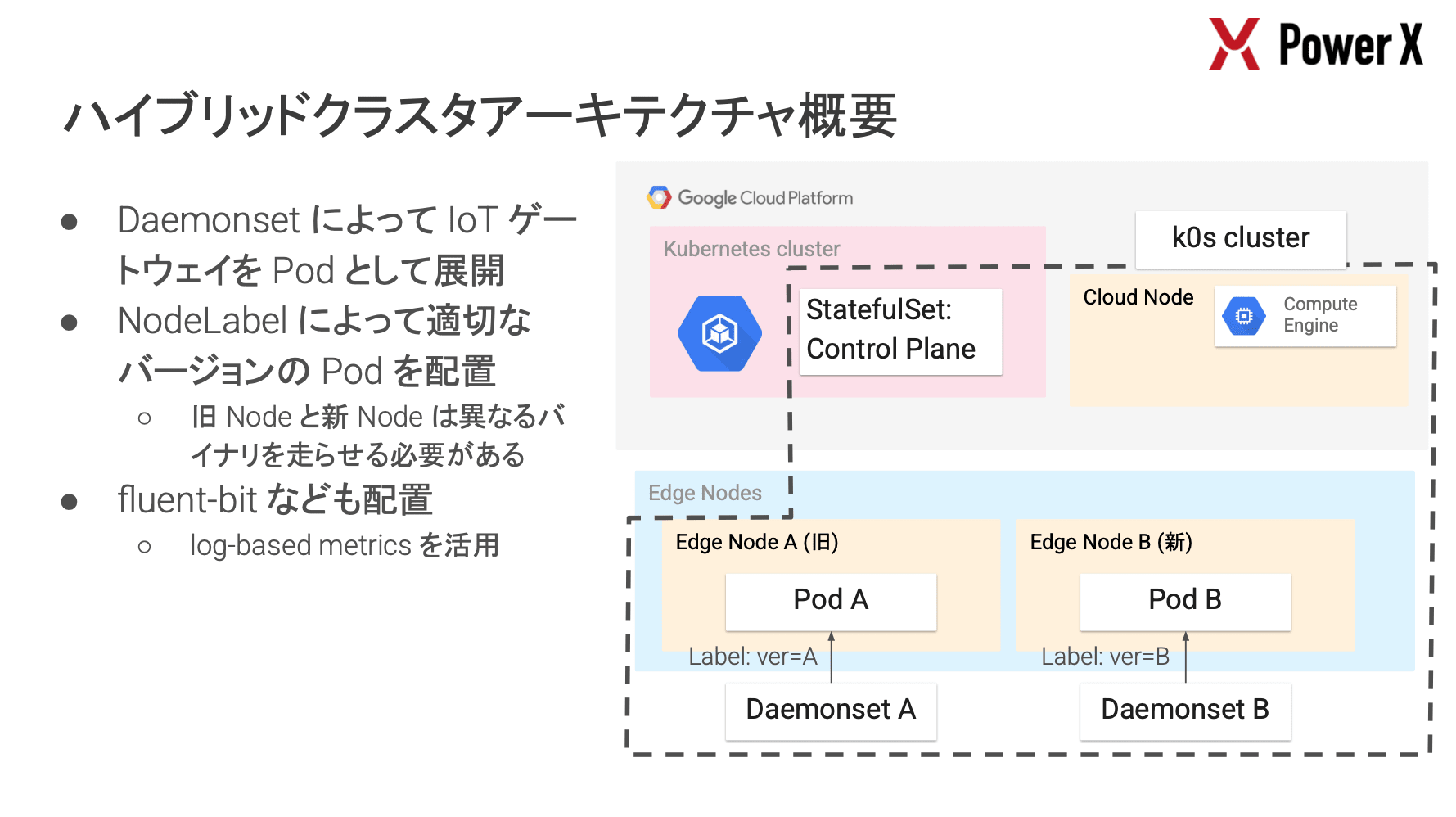
特に興味深かったのは、デバイスの制約に応じた Observability の確保戦略です。
- 新デバイス
- ノード内に OpenTelemetry Collector を配置し、Push 型でメトリクスを送信
- 旧デバイス
- リソース不足のため Collector を配置できない
- 解決策としてクラウド側(GCE)に配置した Collector から VPN 経由で Pull 型(Prometheus Receiver)でスクレイピング
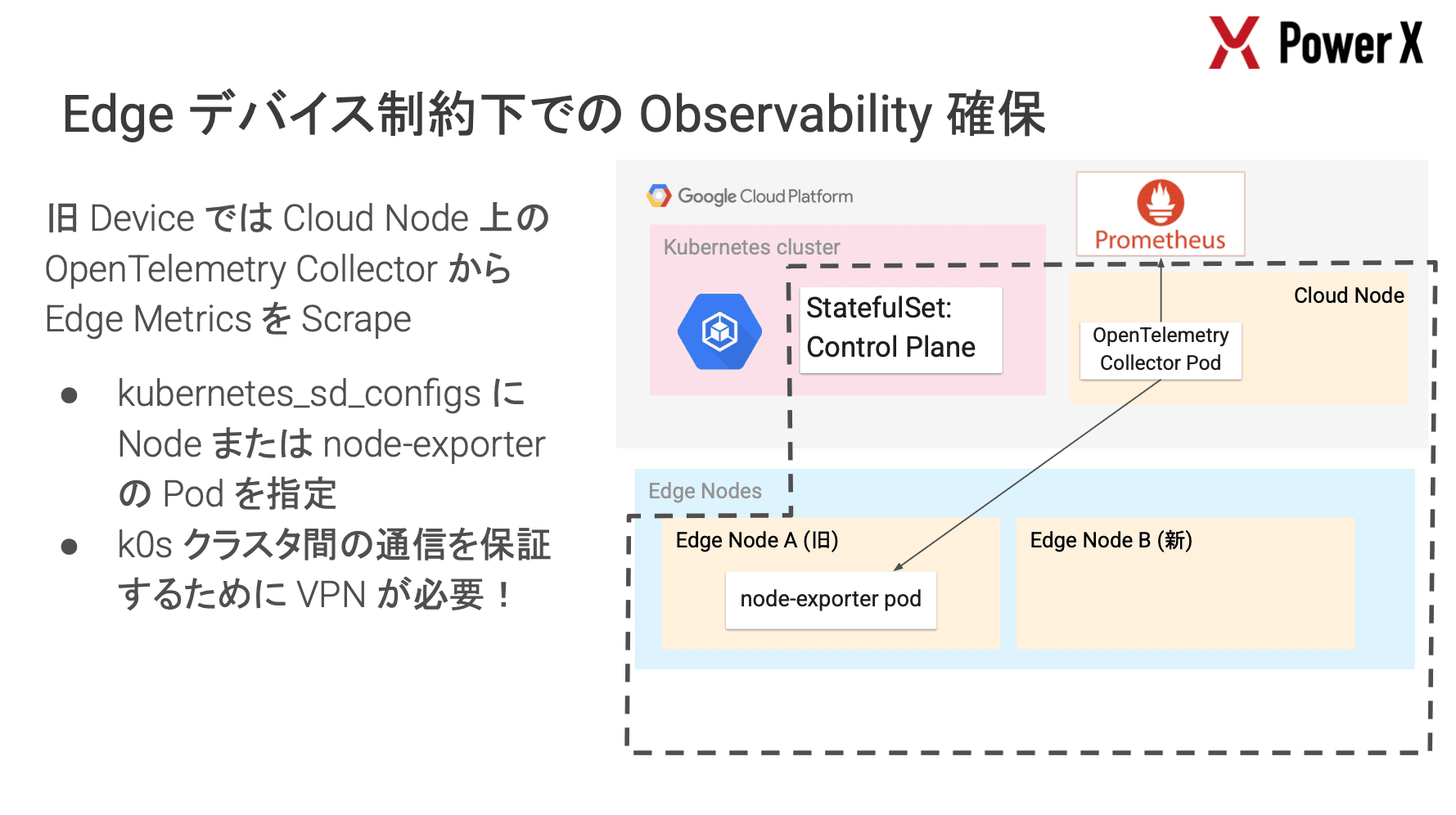
また、デプロイメントにおいても、DaemonSet のアップデート戦略に OnDelete を設定し、新しいイメージの Pull を完了させてから Pod を入れ替えることでダウンタイムを最小化する等、エッジ環境特有の制約を乗り越えるための実践的な工夫が随所に見られました。
所感
クラウドネイティブな技術の多くはリソースが豊富な環境が前提になっていると思いますが、本セッションではそれを物理的な制約が厳しいエッジ環境に適用するという、SRE の適用領域の広がりを強く印象付けるものでした。 Web サービスとは異なる制約(不安定なネットワーク、限られたリソース、物理的なアクセス困難性)の中で、デファクトスタンダードな技術をベースに取り入れつつ信頼性を担保しようとする試みは、インフラの形態を問わず SRE のアプローチが有効であることを示していると感じます。
特定の技術選定の巧みさ以上に、環境固有の厳しい制約と向き合い、トレードオフを評価しながら運用可能なシステムへと落とし込むエンジニアリングの過程は、聴講したセッションの中でも非常に面白かったです。
SRE のための eBPF 活用ステップアップガイド
- 株式会社グリー
- 岩堀 草平
セッション概要
「eBPF は強力だがハードルが高い」と感じる SRE に向けて eBPF の基礎から実践的なトラブルシューティング事例までを紹介しているセッションでした。




セッション中では、カーネル内部やブラックボックス化したプロセスの挙動を調査するための方法として以下 3 つの eBPF 活用事例が紹介されていました。
- 既存ツールの利用
OS 更新後に Ruby のワーカープロセスが落ちる現象に対し、killsnoop でシグナル送信元を特定。
Systemd のタイマ移行に伴う cgroup の挙動(Type=oneshot)が原因であることを突き止め、Systemd 管理への移行で解決。

- bpftrace での調査
Memcached のレイテンシ悪化時に、bpftrace で memcached_set 関数をフック。
キーと値のサイズを計測した結果、特定のフレームワークが巨大なインデックスオブジェクトを生成していることを特定して実装修正に繋げた。

- eBPF プログラム作成
肥大化した PHP コードベースの整理のため、PHP の USDT(User Statically-Defined Tracing)プローブを利用。 コンパイルされたコードパスを可視化することで、実際に使われているコードと不要なコードを明確化し、安全なコード削除を実現。
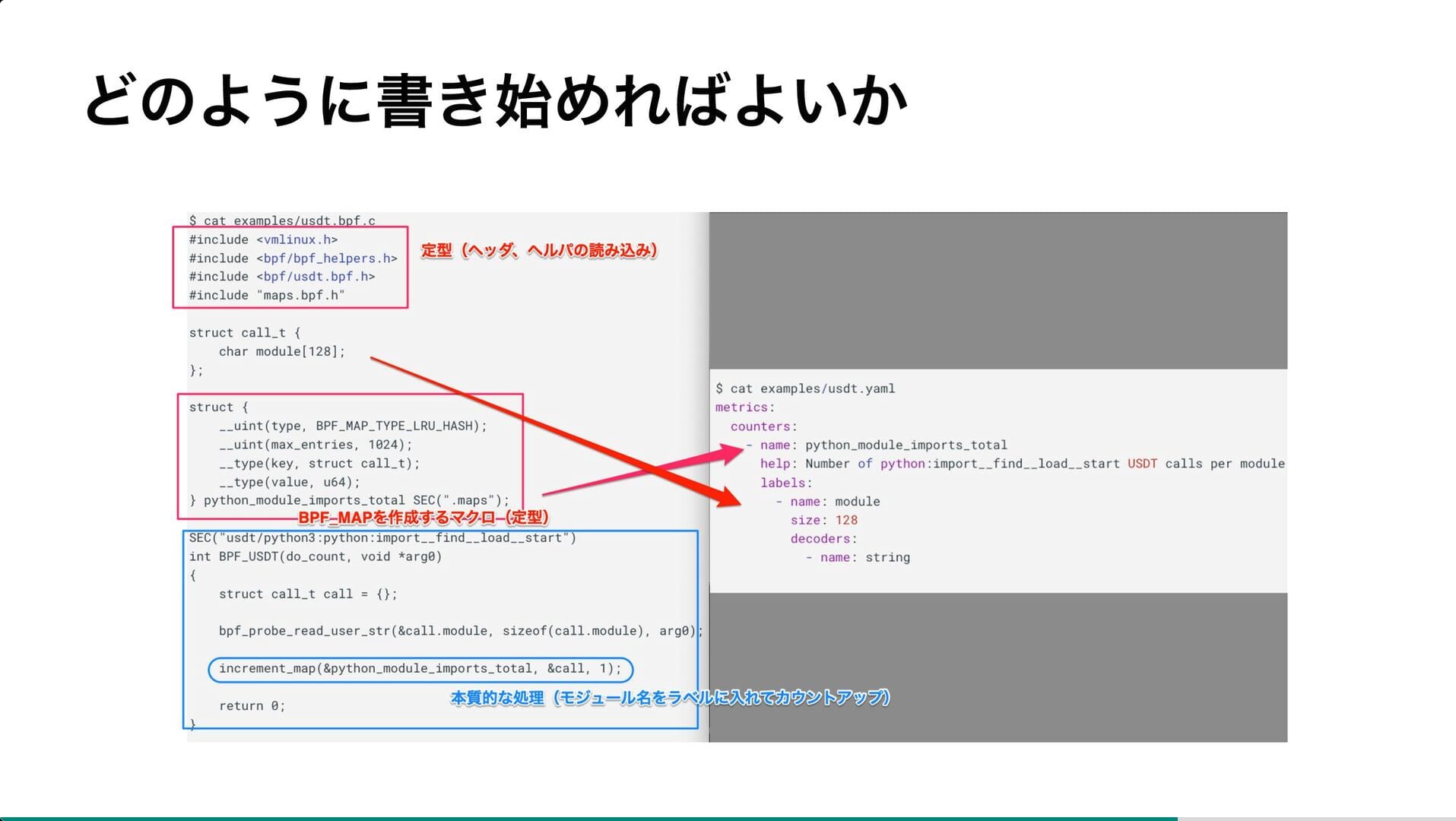
事例紹介を踏まえ、eBPF は単なる低レイヤのデバッグツールに留まらず、アプリケーションやミドルウェアのブラックボックス的な挙動をソースコードの修正無しに特定できる実用的な可観測性の手段であることが示されていました。

所感
これまで eBPF はカーネル開発者のための技術というイメージが強かったですが、本セッションを通じて、SRE が日常的に直面するアプリケーション外部の要因による不具合やミドルウェアのブラックボックス的な挙動を解明するための有効な選択肢になり得ると感じました。
特に bpftrace を用いることで、複雑な環境構築無しに execsnoop や opensnoop といったツールで即座に調査を開始できる手軽さは、トラブルシューティングの初動を劇的に変えるポテンシャルを感じます。
ソースコードが読めないから諦めるのではなく、システムコールレベルで何が起きているかを見るという選択肢を持つことで、SRE としての対応力の幅が大きく広がると感じました。
弊社のセッション紹介
弊社のセッションについても軽く紹介しておきます。
ABEMA の本番環境負荷試験への挑戦
- 株式会社 AbemaTV SRE
- 宮﨑 大芽
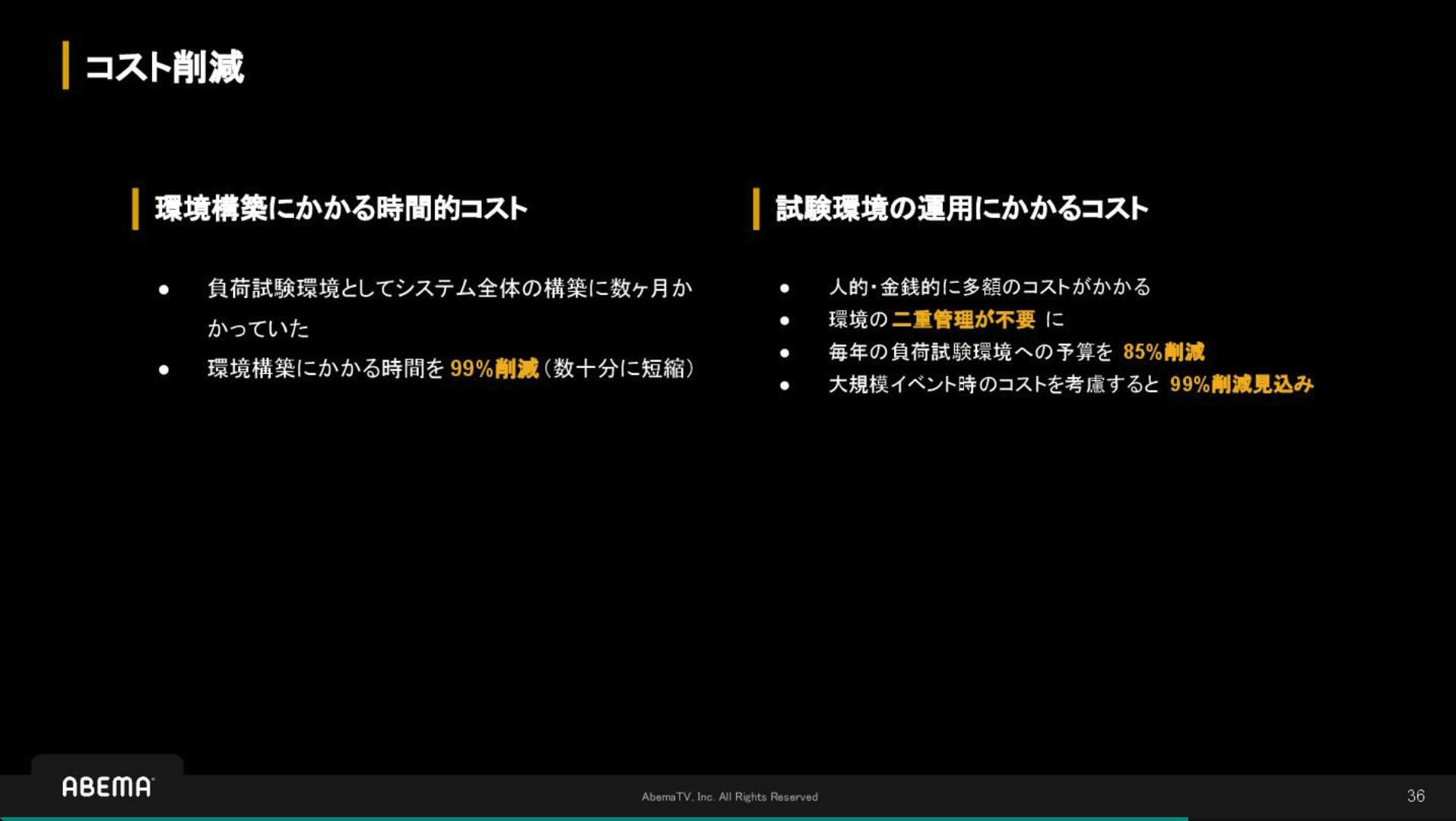
ABEMA では、ワールドカップ等の大型配信イベントや突発的なトラフィック急増に対応するため、あえて「本番環境での負荷試験」というアプローチを選択しています。
本セッションでは、検証環境での完全な再現が困難な中、ユーザ体験を損なわずに本番環境で試験を行うためのアーキテクチャ設計や、段階的な実施計画、SRE チームが主導した組織的な合意形成のプロセスについて紹介しています。 継続的な信頼性向上とキャパシティプランニングの基盤として機能している取り組みは、大規模サービスの運用において非常に示唆に富む内容です。

サイバーエージェントグループの SRE 10 年の歩みと AI 時代の生存戦略
- 株式会社サイバーエージェント メディア統括本部
- 柘植 翔太
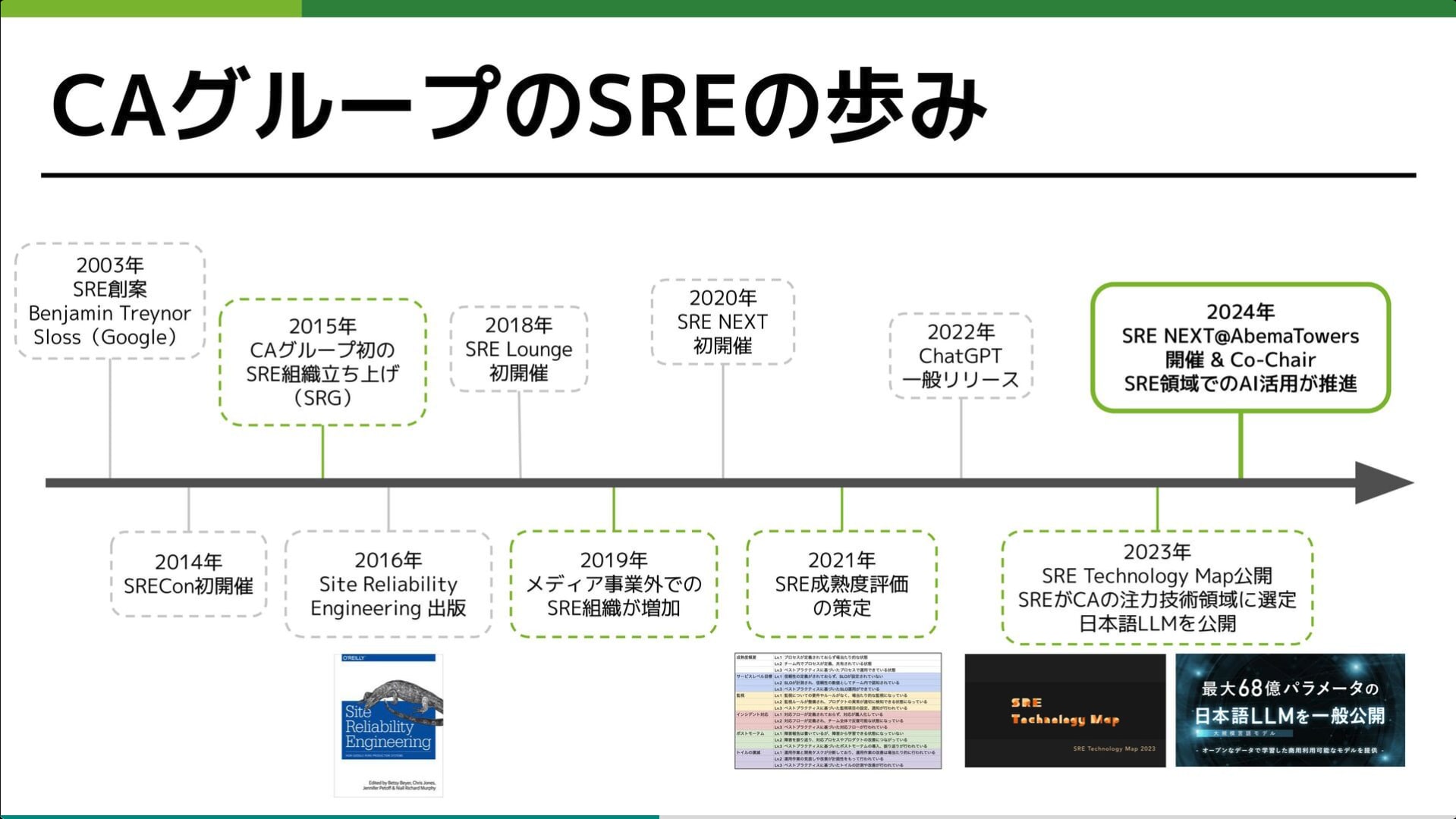
2015 年の組織立ち上げから約 10 年にわたるサイバーエージェントグループの SRE の歴史と、AI 時代における新たな生存戦略についての発表です。
「AI アーキテクチャレビュー」や「AI コーディングの徹底(AI 以外でのコーディング禁止)」といった具体的な活用事例とともに、SRE に求められる「AI シフト」のためのアーキテクチャ設計力や、エンジニアのモチベーション管理についても語られています。 AI を開発フローに深く組み込み、組織全体で適応していくための実践的な知見が詰まっています。

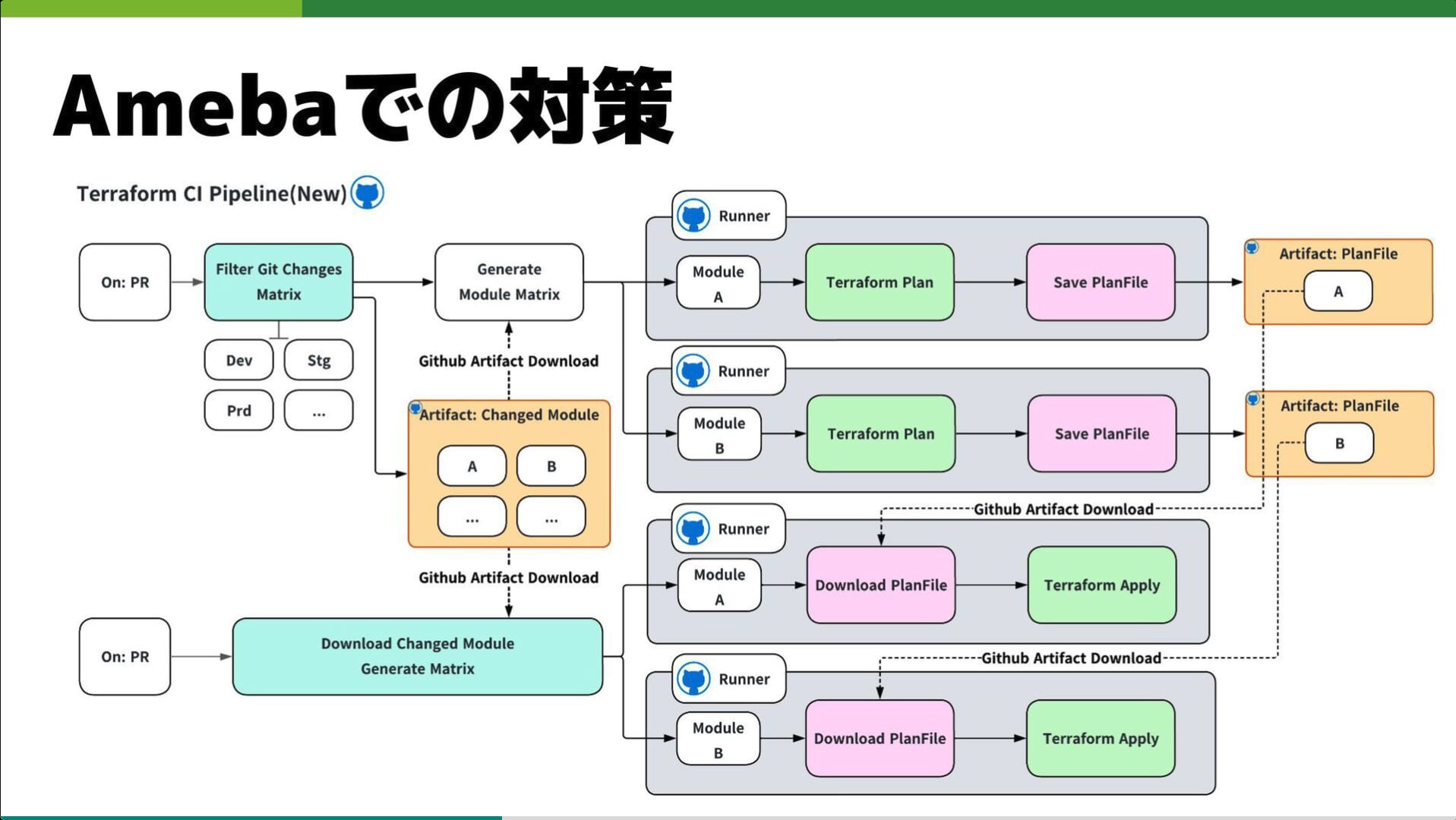
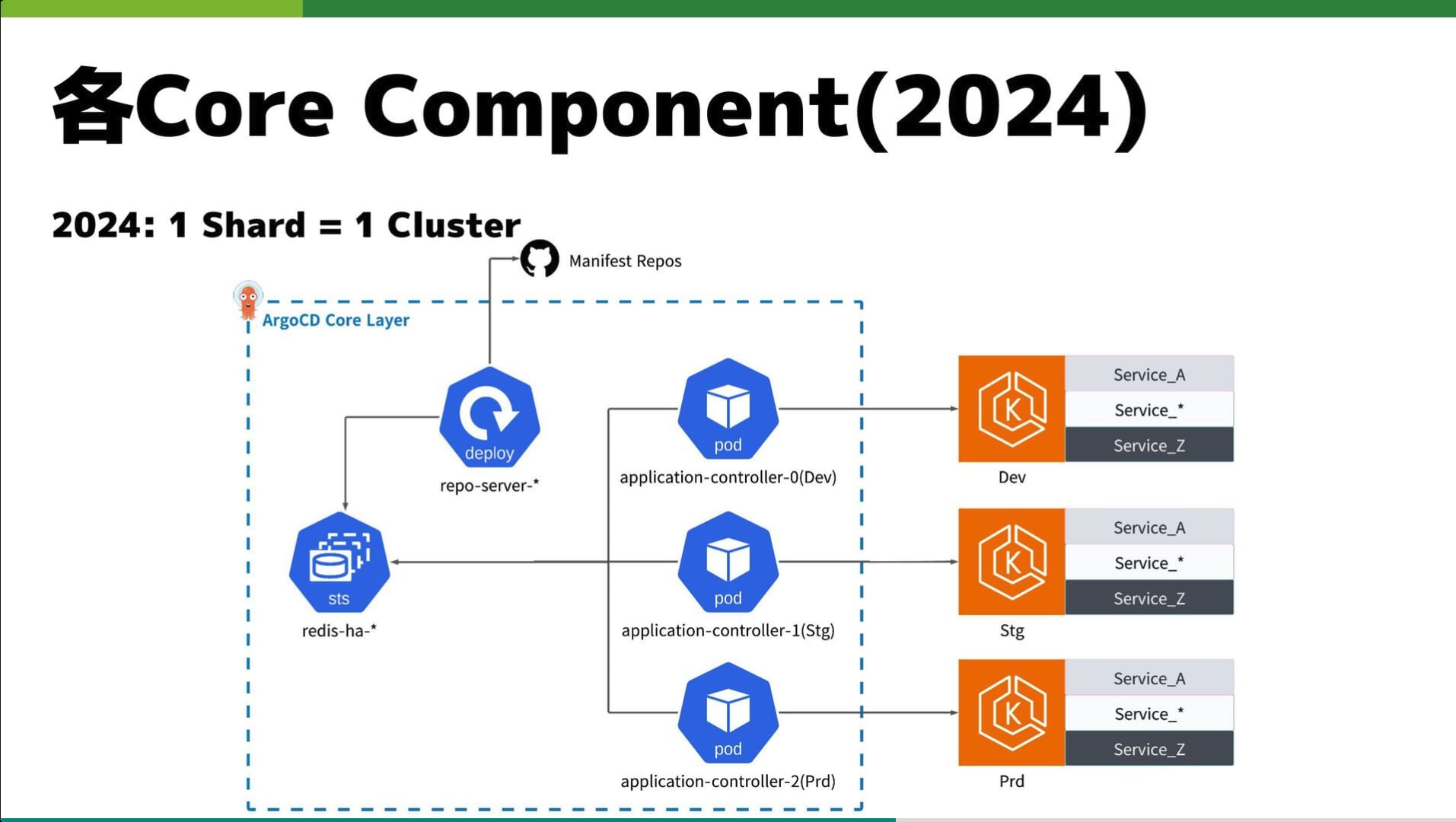
Ameba CI/CD: Terraform and Argo CD Improvements
- 株式会社サイバーエージェント メディア統括本部
- 石川 雲
Ameba プラットフォームにおける CI/CD 基盤の進化と、数万リソース規模の環境で直面した課題への対処法に関するセッションになっています。
Terraform の実行時間短縮に向けて、「変更があったモジュールのみを検出して並列実行する」仕組みや、「Plan ファイルを活用した Apply の高速化」、さらには「遅いリソース(ASG 等)の Karpenter への移行」といった具体的なチューニング手法が紹介されました。
また、CD 領域では Argo CD と Flux CD の併用運用におけるパフォーマンス改善や、KubeVela を活用したポストリリースワークフローの構築等、大規模な GitOps 基盤を支えるための実践的な知見が詰まっています。
まとめ
オンラインでも情報は得られますが、現地参加したことで、登壇者の熱量や、セッションの合間に交わされる生々しい悩みを肌で感じることができました。 特に、今回は AI はじめ、新しい領域に SRE がどう適応していくかという議論は、スライドの文字情報以上に、会場の空気感からその切実さや可能性を感じ取ることができました。
Brendan Gregg 氏の基調講演ではパフォーマンスの基礎に立ち返る重要性を再確認でき、各社の事例からは、技術選定だけでなく組織としての合意形成やエンジニアのモチベーション管理といった人間的な側面もまた、信頼性を支える重要な要素であるという学びを得ました。
同様の課題を持つ他社のエンジニアとの交流は、非常に有意義な時間でした。 今回得られた知見を日々の業務に還元し、来年は自らの実践事例として何らかの形でコミュニティに貢献できるよう、取り組みを続けていきたいと思います。
本ブログを通じて、SRE NEXT 2025 の熱気やセッション概要だけでも伝われば幸いです。
現地写真
Day 1 ランチセッションではまい泉の弁当が出てきた。 Day 2 ランチセッションは 5 種類ぐらい弁当があった。


展示ブースの様子(常に人で溢れてた)


懇親会の様子


Keropen の限定ビールとクッキー(Keropen が何かは未だよく分かってない)


SRE NEXT 2025 資料一覧
聴講できなかった他のセッションについては、公開されている範囲でスライドをまとめておきます。