OpenTelemetry Collector で構築するテレメトリパイプライン
はじめに
サービス規模が大きくなるにつれ、ログ・メトリクス・トレースといった テレメトリデータ の収集経路は複雑になりがちです。 ベンダ固有のエージェントや独自スクリプトが混在していると、管理コストが増大するだけでなく、運用環境に合わせたツールの移行も難しくなります。
こうした課題に対し、OpenTelemetry Collector はテレメトリデータの収集・加工・転送までを一元管理するテレメトリパイプラインを提供します。
今回のブログでは OpenTelemetry Collector のコンポーネントや、パイプラインの基本的な設計・運用パターンについて紹介したいと思います。
OpenTelemetry パイプラインの基本構成
OpenTelemetry Collector は YAML 形式の設定ファイルによって制御されます。 パイプラインを構築するためには、主に以下のコンポーネントについて理解する必要があります。
| コンポーネント | 設定 | 機能 |
|---|---|---|
| Receivers | 必須 | テレメトリデータの受信処理を管理する |
| Processors | 任意 | テレメトリデータの加工処理を管理する |
| Exporters | 必須 | テレメトリデータの送信処理を管理する |
| Connectors | 任意 | パイプライン間を接続する |
| Extensions | 任意 | Collector 自体の管理機能を提供する |
| Service | 必須 | パイプラインそのものの定義を管理する |
コンポーネント
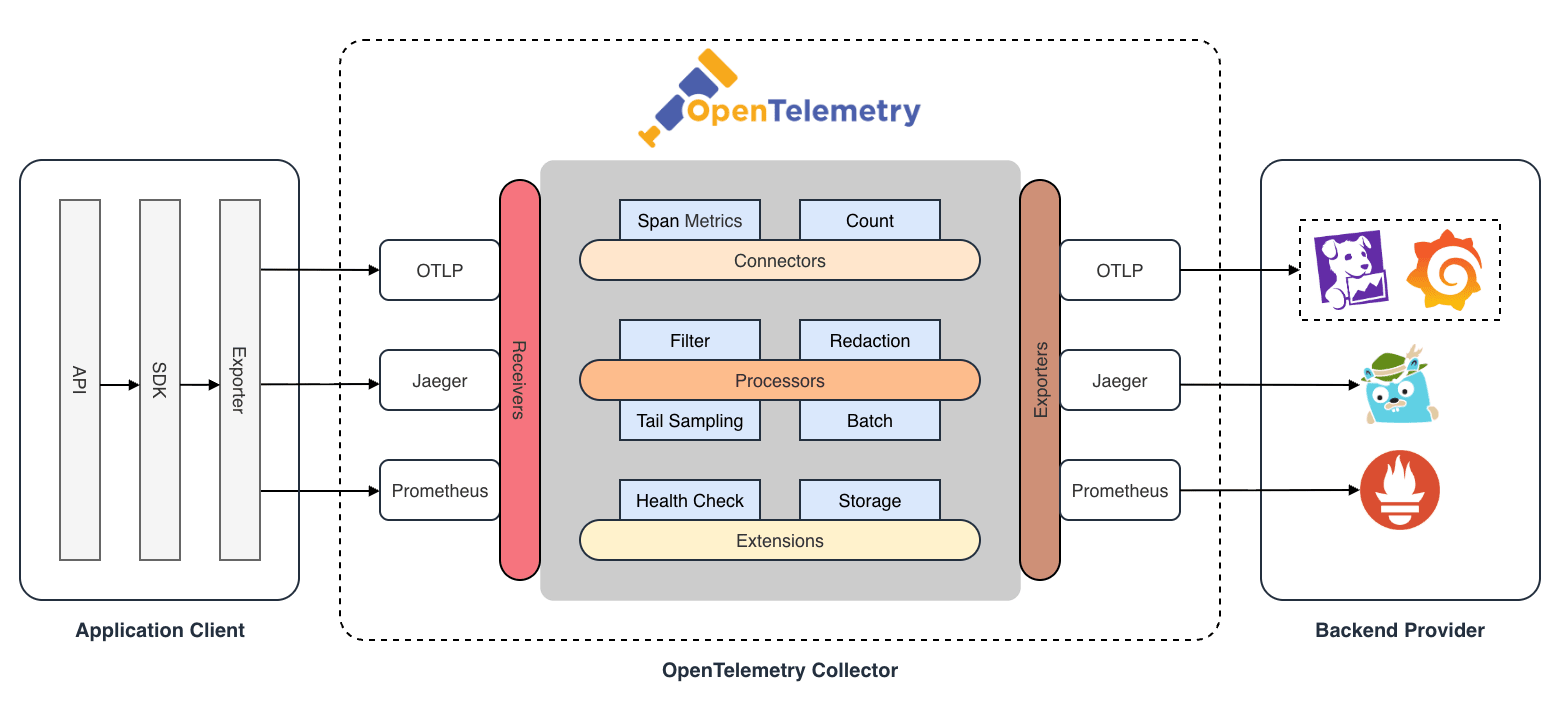
Receivers
各サービスからテレメトリデータを受け取る、パイプラインの入り口となるコンポーネントです。
データの取り込み方法には、OpenTelemetry Collector 側でポートを開放してデータを受信する Push 型(例:OTLP Receiver)と、ターゲットに対して定期的にデータを取りに行く Pull 型(例:Prometheus Receiver)があります。
Processors
受信したデータに対してフィルタリング、属性の追加・削除、バッチ処理等の加工を行う中間コンポーネントです。
Processors は必須ではありませんが、データのノイズ除去や機密情報のマスキング、転送効率の向上等、実運用においては重要な役割を担います。
Exporters
処理されたテレメトリデータを外部のバックエンドやシステムへ送信する、パイプラインの出口となるコンポーネントです。
受け取ったデータを送信先のフォーマット(例:Jaeger, Prometheus, OTLP)に変換して転送します。
バックエンドへの送信だけでなく、デバッグ用に標準出力へデータを書き出す debug エクスポータ等も存在します。
Connectors
あるパイプラインの出力を別のパイプラインの入力として接続するコンポーネントです。 「ログからメトリクスを生成する」といった異なるシグナル間の変換や、データの複製・ルーティングに使用されます。
Extensions
テレメトリデータの処理には直接関与しない、Collector 自体の管理機能を提供するコンポーネントです。 ヘルスチェック、プロファイリング(pprof)、内部状態の確認(zPages)などがこれに含まれます。
Service
定義された Receivers / Processors / Exporters / Connectors / Extensions を組み合わせて、実際のデータの流れ(パイプライン)を構築するオーケストレータです。
service セクションでは pipelines を定義し、有効化したいコンポーネントを指定することで初めて Collector が動作します。
例えば「OTLP で受信して Jaeger へ送信する」といった具体的なフローはここで定義されます。
最小構成の設定例
これら 3 つのコンポーネントを組み合わせて最もシンプルなパイプラインを構築すると以下のようになります。
ここでは OTLP(OpenTelemetry Protocol) でログを受信し、そのままコンソールに出力だけの構成です。
OTLP(OpenTelemetry Protocol)とは、テレメトリデータを交換するために設計された汎用プロトコルで、debug エクスポータ(詳細モード)の出力では OTLP データモデルの階層構造をそのまま確認することができます。
上記のファイルを元に Docker で挙動確認をしてみます。
- OpenTelemetry Collector を起動
- 別ターミナルから telemetrygen を使ってテスト用のログデータを送信
送信が成功すると Collector 側にログが出力されます。
OTLP データの構造
通常、テレメトリデータは以下の 3 階層で構成されます。
1. Resource
- データの発生元(サービス、コンテナ、ホスト)を識別する情報
service.name/k8s.*.name/host.nameが該当し、配下のすべてのデータに共通して適用される
2. Scope
- アプリケーション内のどのライブラリやモジュール(Instrumentation Scope)からデータが生成されたかを示す
InstrumentationScope: otelgenが該当する
3. Record
- テレメトリデータ(ログ / スパン / メトリクス)の本体
- 以下が含まれる
Timestamp:時刻SeverityText:重要度Body:メッセージ本文Attributes:イベント固有の属性情報
テレメトリデータの処理と変換
OpenTelemetry Collector は Processors を利用して、データがパイプラインを通過する際に加工や変換を行うことができます。 これを利用することで、データのフィルタリング、属性の追加・削除、バッチ処理による効率化等が可能になります。
パイプラインの流れは Receiver -> [Processors] -> Exporter となります。
Batch Processor による効率化
個々のデータを都度送信するとネットワーク負荷が高くなるため、Batch Processor を使用してデータをバッチ単位でまとめて送信するのが一般的です。
Filter Processor によるノイズ削減
不要なログやメトリクスを除外することで、バックエンドのストレージコストや検索ノイズを削減できます。 Filter Processor と OpenTelemetry Transformation Language(OTTL) を組み合わせることで、柔軟なフィルタリング条件を記述できます。
Transform Processor によるデータの加工
Transform Processor を利用することで、データの属性(Attributes)やリソース情報(Resource)に対して OTTL を用いて複雑な変換処理を定義できます。
例えば、Receiver で受信したデータに対して、機密情報のマスキングや不要な属性の削除、データ形式の正規化といった追加の処理を行いたい場合に有用です。
Memory Limiter によるリソース保護
Memory Limiter Processor を利用することで、Collector 自身のメモリ使用量を監視し、過負荷時にデータの受け入れを制限することができます。 スパイク等によって OOM が発生するのを未然に防ぎたい場合に有用です。
service セクションで memory_limiter を呼び出す場合は、必ず プロセッサチェーンの先頭に配置 します。
高度なパイプライン構築
基本的なパイプラインに加え、OpenTelemetry Collector ではより複雑な要件に対応するための機能が提供されています。
複数シグナルの並列処理
OpenTelemetry Collector は、ログだけでなくトレースやメトリクスも同一のプロセスで扱うことができます。
service セクションで複数のパイプラインを定義することで、異なるシグナルを並列に処理することが可能です。
複数バックエンドへのファンアウト
1 つの入力データを複製し、複数の宛先へ同時に送信する処理形態を ファンアウト(fan-out) と呼びます。
OpenTelemetry Collector では、パイプラインの exporters リストに複数の宛先を指定するだけでファンアウトを実現することができます。
これにより、移行期間中の並行稼働や、用途に応じたデータの使い分けが容易になります。
Connectors によるパイプラインの連結
Connectors は、あるパイプラインの出力を別のパイプラインの入力として接続する機能です。 これにより「ログからメトリクスを生成する」「スパンからメトリクスを集計する」といった高度な処理が可能になります。
例えば、Count Connector を使用して、特定のエラーログの発生数をメトリクスとしてカウントし、別のパイプラインで処理したい場合、構成は以下のようになります。
運用と管理
本番環境で OpenTelemetry Collector を安定して運用するために必要な選定基準や監視方法について紹介しておきます。
Collector ディストリビューションの選定
OpenTelemetry Collector のバイナリには、同梱されているコンポーネント(Receiver, Processor, Exporter 等)の違いによって、主に 3 つのディストリビューションがあります。 本番環境への導入を検討する際、この選定はパフォーマンスとセキュリティの観点で非常に重要です。
Core:otelcol
OpenTelemetry プロジェクトが公式にメンテナンスしている、最も基本的かつ安定したコンポーネントのみを含んだ軽量版です。 OTLP 等の標準プロトコルのみを扱うシンプルな構成であればこれだけで十分ですが、AWS や Datadog といったベンダ固有のコンポーネントは含まれていません。
Contrib:otelcol-contrib
コミュニティによって開発・寄贈された多種多様なコンポーネントを含む「全部入り」のフルセット版です。 開発段階や PoC において、必要なコンポーネントが含まれていることが多いため非常に便利です。
一方で、本番運用においては以下の点を考慮する必要があります。
- バイナリサイズ:未使用のコンポーネントも大量に含まれるため、バイナリサイズが肥大化する(数百 MB 規模)
- セキュリティリスク:依存ライブラリが膨大になるため、脆弱性の影響を受ける(サプライチェーン攻撃)可能性が広がる
- 安定性:含まれるコンポーネントの中には実験的(Alpha / Beta)なステータスのものも混在する
Custom:ocb
本番環境や特に大規模なデプロイメントにおいては、ocb(OpenTelemetry Collector Builder)ツールを使用して、必要なコンポーネントだけをパッケージングした独自のバイナリをビルドすることが推奨されます。
Kubernetes の場合、マニフェストに利用したいコンポーネントを列挙して ocb コマンド を実行することで、Core や Contrib、あるいは独自のプライベートなコンポーネントを自由に組み合わせて最適化したバイナリ(コンテナイメージ)を生成することができます。
- マニフェストの準備
- ビルドの実行
- コンテナイメージの作成
Custom ビルドのメリットとしては以下のようなものがあります。
- イメージサイズの削減:不要なコードが含まれないため、コンテナイメージのサイズを削減できる
- セキュリティ:攻撃対象領域(Attack Surface)を最小限に抑えることができる
- ガバナンス:組織内で使用を許可するコンポーネントを明示的に管理できる
パイプラインのデバッグと監視
Collector 自体の健全性を維持するために、Extensions では以下の機能を利用することができます。
- zPages:ブラウザから Collector の内部状態(例:トレースやパイプラインのステータス)を確認することができる
- Health Check:Kubernetes の Liveness / Readiness Probe に利用できるエンドポイント
- Internal Telemetry:Collector 自身のメトリクス(例:処理したスパン数、ドロップ数、メモリ使用量)を Prometheus 等で収集することができる
- 2026 年 1 月時点では実験的な機能として導入されている [参考]
アーキテクチャの選定
Collector のデプロイ戦略は、システムの規模や要件に応じて選択します。 代表的な 3 つのパターンについて、それぞれの特徴とアーキテクチャを紹介します。
Agent パターン
最も基本的な構成で、各アプリケーションホストや Pod(サイドカーコンテナ)に直接 Collector を配置する方法で、アプリケーションと 1 対 1 または 1 対 N で動作します。
- メタデータの付与:アプリケーションに最も近い場所で動作するため、ホスト情報(IP アドレス、ホスト名)やコンテナ情報等のメタデータを容易に付与できる
- リソース消費:アプリケーションと同じホスト上で動作するため、Collector 自身のリソース消費がアプリケーションに影響を与える可能性がある
- 管理コスト:Collector の設定変更が必要な場合、すべてのホストに対してデプロイを行う必要がある
Gateway パターン
集約用の Collector(Gateway)を独立したサービスとして配置し、複数のアプリケーションからデータを受け取る方法です。 ロードバランサの背後に複数の Collector インスタンスを配置して冗長化するのが一般的です。
- 設定の一元管理:API キーや認証情報等の機密情報を Gateway 側で一元管理できるため、セキュリティリスクを低減できる
- 接続数の削減:バックエンドへの接続を Gateway からのみに限定できるため、バックエンド側の負荷を軽減できる
- メタデータの課題:アプリケーション側で適切なメタデータを付与して送信する必要がある
Agent + Gateway パターン
上記 2 つを組み合わせた構成で、大規模環境において最も推奨されるパターンです。 Agent でメタデータ付与等の軽量な処理を行い、Gateway で集約・高度な加工・ルーティングを行います。
- 責務分離:
- Agent:データの収集、メタデータの付与、Gateway への転送(軽量な処理)
- Gateway:認証、バッチ処理、サンプリング、ルーティング(重い処理)
- スケーラビリティ:Gateway 層を独立してスケールさせることができるため、トラフィックの増加に柔軟に対応できる
- 耐障害性:Gateway の前段に Kafka 等のメッセージキューを挟むことで、スパイクアクセス時のバッファリングを行い、データの欠損を防ぐことも可能
まとめ
今回のブログでは OpenTelemetry Collector のコンポーネントや、パイプラインの基本的な設計・運用パターンについて紹介しました。 OpenTelemetry Collector の最大の利点は、Receiver、Processor、Exporter といったコンポーネントを自由に組み合わせることで、環境や要件に応じた柔軟なパイプラインを構築できる点にあると思います。 テレメトリデータの収集と活用を疎結合にすることで、特定のベンダに依存することなく、将来的なツールの選定や移行もスムーズに行えるようになります。
OpenTelemetry だけ見てもコンポーネントが複雑に絡みあうため、導入当初は設定や概念の理解に時間を要すると思いますが、まずは最小構成から始め、要件に応じて Processor でデータを加工したり、Gateway を導入したりして、段階的にパイプラインを拡張していくのが良いと思います。