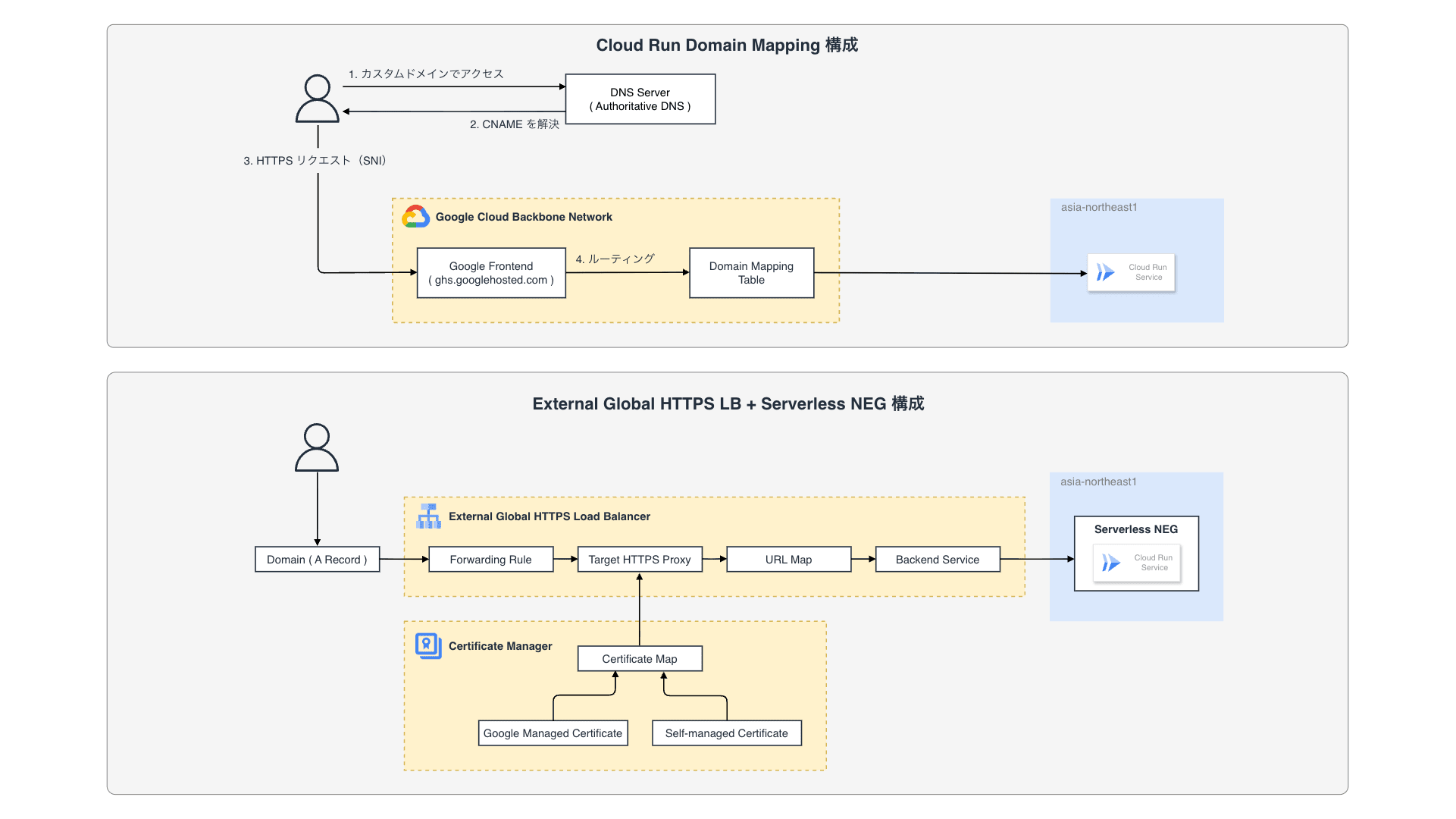
Cloud Run には標準で *.run.app というドメインが付与されますが、サービスとして公開する際には独自のカスタムドメインを割り当てたいケースがほとんどです。Cloud Run ではカスタムドメインを割り当てるための機能として Domain Mapping と呼ばれる仕組みを提供しています。Domain Mapping は非常に手軽に利用できる一方で、レイテンシの問題や証明書管理の柔軟性等、本番運用においていくつか懸念となる点も存在します。今回のブログでは、Cloud Run Domain Mapping の仕組みと、撤退するに至った理由、また移行時のダウンタイムを最小限に抑えるマイグレーション戦略について紹介したいと思います。
- Published on